 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Aligned Reward Model beyond Semantics
Jan 30, 2026Reinforcement Learning from Human Feedback (RLHF) is a pivotal technique for aligning large language models (LLMs) with human preferences, yet it is susceptible to reward overoptimization, in which policy models overfit to the reward model, exploit spurious reward patterns instead of faithfully capturing human intent. Prior mitigations primarily relies on surface semantic information and fails to efficiently address the misalignment between the reward model (RM) and the policy model caused by continuous policy distribution shifts. This inevitably leads to an increasing reward discrepancy, exacerbating reward overoptimization. To address these limitations, we introduce R2M (Real-Time Aligned Reward Model), a novel lightweight RLHF framework. R2M goes beyond vanilla reward models that solely depend on the semantic representations of a pretrained LLM. Instead, it leverages the evolving hidden states of the policy (namely policy feedback) to align with the real-time distribution shift of the policy during the RL process. This work points to a promising new direction for improving the performance of reward models through real-time utilization of feedback from policy models.
Enhancing LLM-based Recommendation with Preference Hint Discovery from Knowledge Graph
Jan 26, 2026LLMs have garnered substantial attention in recommendation systems. Yet they fall short of traditional recommenders when capturing complex preference patterns. Recent works have tried integrating traditional recommendation embeddings into LLMs to resolve this issue, yet a core gap persists between their continuous embedding and discrete semantic spaces. Intuitively, textual attributes derived from interactions can serve as critical preference rationales for LLMs' recommendation logic. However, directly inputting such attribute knowledge presents two core challenges: (1) Deficiency of sparse interactions in reflecting preference hints for unseen items; (2) Substantial noise introduction from treating all attributes as hints. To this end, we propose a preference hint discovery model based on the interaction-integrated knowledge graph, enhancing LLM-based recommendation. It utilizes traditional recommendation principles to selectively extract crucial attributes as hints. Specifically, we design a collaborative preference hint extraction schema, which utilizes semantic knowledge from similar users' explicit interactions as hints for unseen items. Furthermore, we develop an instance-wise dual-attention mechanism to quantify the preference credibility of candidate attributes, identifying hints specific to each unseen item. Using these item- and user-based hints, we adopt a flattened hint organization method to shorten input length and feed the textual hint information to the LLM for commonsense reasoning. Extensive experiments on both pair-wise and list-wise recommendation tasks verify the effectiveness of our proposed framework, indicating an average relative improvement of over 3.02% against baselines.
Your Group-Relative Advantage Is Biased
Jan 13, 2026Reinforcement Learning from Verifier Rewards (RLVR) has emerged as a widely used approach for post-training large language models on reasoning tasks, with group-based methods such as GRPO and its variants gaining broad adoption. These methods rely on group-relative advantage estimation to avoid learned critics, yet its theoretical properties remain poorly understood. In this work, we uncover a fundamental issue of group-based RL: the group-relative advantage estimator is inherently biased relative to the true (expected) advantage. We provide the first theoretical analysis showing that it systematically underestimates advantages for hard prompts and overestimates them for easy prompts, leading to imbalanced exploration and exploitation. To address this issue, we propose History-Aware Adaptive Difficulty Weighting (HA-DW), an adaptive reweighting scheme that adjusts advantage estimates based on an evolving difficulty anchor and training dynamics. Both theoretical analysis and experiments on five mathematical reasoning benchmarks demonstrate that HA-DW consistently improves performance when integrated into GRPO and its variants. Our results suggest that correcting biased advantage estimation is critical for robust and efficient RLVR training.
LLMBoost: Make Large Language Models Stronger with Boosting
Dec 26, 2025Ensemble learning of LLMs has emerged as a promising alternative to enhance performance, but existing approaches typically treat models as black boxes, combining the inputs or final outputs while overlooking the rich internal representations and interactions across models.In this work, we introduce LLMBoost, a novel ensemble fine-tuning framework that breaks this barrier by explicitly leveraging intermediate states of LLMs. Inspired by the boosting paradigm, LLMBoost incorporates three key innovations. First, a cross-model attention mechanism enables successor models to access and fuse hidden states from predecessors, facilitating hierarchical error correction and knowledge transfer. Second, a chain training paradigm progressively fine-tunes connected models with an error-suppression objective, ensuring that each model rectifies the mispredictions of its predecessor with minimal additional computation. Third, a near-parallel inference paradigm design pipelines hidden states across models layer by layer, achieving inference efficiency approaching single-model decoding. We further establish the theoretical foundations of LLMBoost, proving that sequential integration guarantees monotonic improvements under bounded correction assumptions. Extensive experiments on commonsense reasoning and arithmetic reasoning tasks demonstrate that LLMBoost consistently boosts accuracy while reducing inference latency.
How Do Graph Signals Affect Recommendation: Unveiling the Mystery of Low and High-Frequency Graph Signals
Dec 10, 2025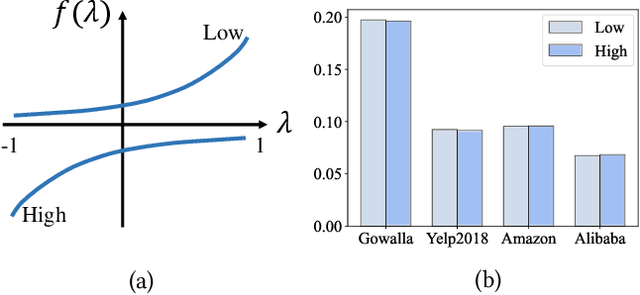
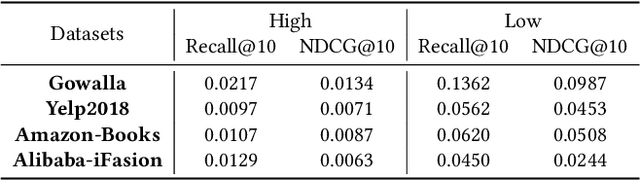
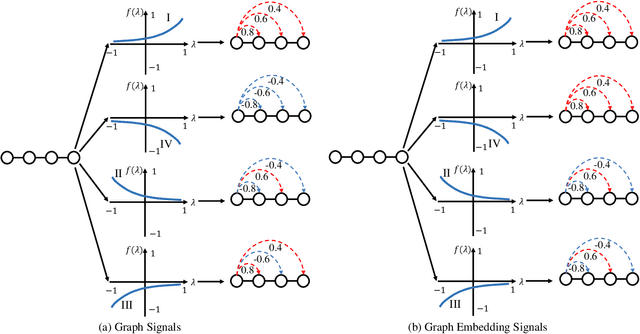
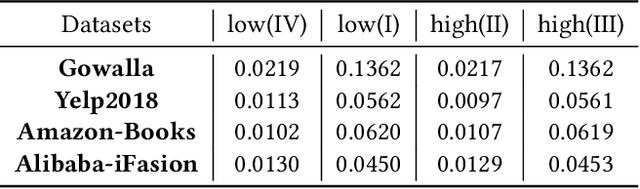
Spectral graph neural networks (GNNs) are highly effective in modeling graph signals, with their success in recommendation often attributed to low-pass filtering. However, recent studies highlight the importance of high-frequency signals. The role of low-frequency and high-frequency graph signals in recommendation remains unclear. This paper aims to bridge this gap by investigating the influence of graph signals on recommendation performance. We theoretically prove that the effects of low-frequency and high-frequency graph signals are equivalent in recommendation tasks, as both contribute by smoothing the similarities between user-item pairs. To leverage this insight, we propose a frequency signal scaler, a plug-and-play module that adjusts the graph signal filter function to fine-tune the smoothness between user-item pairs, making it compatible with any GNN model. Additionally, we identify and prove that graph embedding-based methods cannot fully capture the characteristics of graph signals. To address this limitation, a space flip method is introduced to restore the expressive power of graph embeddings. Remarkably, we demonstrate that either low-frequency or high-frequency graph signals alone are sufficient for effective recommendations. Extensive experiments on four public datasets validate the effectiveness of our proposed methods. Code is avaliable at https://github.com/mojosey/SimGCF.
Multi-Aspect Cross-modal Quantization for Generative Recommendation
Nov 19, 2025Generative Recommendation (GR) has emerged as a new paradigm in recommender systems. This approach relies on quantized representations to discretize item features, modeling users' historical interactions as sequences of discrete tokens. Based on these tokenized sequences, GR predicts the next item by employing next-token prediction methods. The challenges of GR lie in constructing high-quality semantic identifiers (IDs) that are hierarchically organized, minimally conflicting, and conducive to effective generative model training. However, current approaches remain limited in their ability to harness multimodal information and to capture the deep and intricate interactions among diverse modalities, both of which are essential for learning high-quality semantic IDs and for effectively training GR models. To address this, we propose Multi-Aspect Cross-modal quantization for generative Recommendation (MACRec), which introduces multimodal information and incorporates it into both semantic ID learning and generative model training from different aspects. Specifically, we first introduce cross-modal quantization during the ID learning process, which effectively reduces conflict rates and thus improves codebook usability through the complementary integration of multimodal information. In addition, to further enhance the generative ability of our GR model, we incorporate multi-aspect cross-modal alignments, including the implicit and explicit alignments. Finally, we conduct extensive experiments on three well-known recommendation datasets to demonstrate the effectiveness of our proposed method.
FLeW: Facet-Level and Adaptive Weighted Representation Learning of Scientific Documents
Sep 09, 2025Scientific document representation learning provides powerful embeddings for various tasks, while current methods face challenges across three approaches. 1) Contrastive training with citation-structural signals underutilizes citation information and still generates single-vector representations. 2) Fine-grained representation learning, which generates multiple vectors at the sentence or aspect level, requires costly integration and lacks domain generalization. 3) Task-aware learning depends on manually predefined task categorization, overlooking nuanced task distinctions and requiring extra training data for task-specific modules. To address these problems, we propose a new method that unifies the three approaches for better representations, namely FLeW. Specifically, we introduce a novel triplet sampling method that leverages citation intent and frequency to enhance citation-structural signals for training. Citation intents (background, method, result), aligned with the general structure of scientific writing, facilitate a domain-generalized facet partition for fine-grained representation learning. Then, we adopt a simple weight search to adaptively integrate three facet-level embeddings into a task-specific document embedding without task-aware fine-tuning. Experiments show the applicability and robustness of FLeW across multiple scientific tasks and fields, compared to prior models.
H2Tune: Federated Foundation Model Fine-Tuning with Hybrid Heterogeneity
Jul 30, 2025Different from existing federated fine-tuning (FFT) methods for foundation models, hybrid heterogeneous federated fine-tuning (HHFFT) is an under-explored scenario where clients exhibit double heterogeneity in model architectures and downstream tasks. This hybrid heterogeneity introduces two significant challenges: 1) heterogeneous matrix aggregation, where clients adopt different large-scale foundation models based on their task requirements and resource limitations, leading to dimensional mismatches during LoRA parameter aggregation; and 2) multi-task knowledge interference, where local shared parameters, trained with both task-shared and task-specific knowledge, cannot ensure only task-shared knowledge is transferred between clients. To address these challenges, we propose H2Tune, a federated foundation model fine-tuning with hybrid heterogeneity. Our framework H2Tune consists of three key components: (i) sparsified triple matrix decomposition to align hidden dimensions across clients through constructing rank-consistent middle matrices, with adaptive sparsification based on client resources; (ii) relation-guided matrix layer alignment to handle heterogeneous layer structures and representation capabilities; and (iii) alternating task-knowledge disentanglement mechanism to decouple shared and specific knowledge of local model parameters through alternating optimization. Theoretical analysis proves a convergence rate of O(1/\sqrt{T}). Extensive experiments show our method achieves up to 15.4% accuracy improvement compared to state-of-the-art baselines. Our code is available at https://anonymous.4open.science/r/H2Tune-1407.
Proto-EVFL: Enhanced Vertical Federated Learning via Dual Prototype with Extremely Unaligned Data
Jul 30, 2025In vertical federated learning (VFL), multiple enterprises address aligned sample scarcity by leveraging massive locally unaligned samples to facilitate collaborative learning. However, unaligned samples across different parties in VFL can be extremely class-imbalanced, leading to insufficient feature representation and limited model prediction space. Specifically, class-imbalanced problems consist of intra-party class imbalance and inter-party class imbalance, which can further cause local model bias and feature contribution inconsistency issues, respectively. To address the above challenges, we propose Proto-EVFL, an enhanced VFL framework via dual prototypes. We first introduce class prototypes for each party to learn relationships between classes in the latent space, allowing the active party to predict unseen classes. We further design a probabilistic dual prototype learning scheme to dynamically select unaligned samples by conditional optimal transport cost with class prior probability. Moreover, a mixed prior guided module guides this selection process by combining local and global class prior probabilities. Finally, we adopt an \textit{adaptive gated feature aggregation strategy} to mitigate feature contribution inconsistency by dynamically weighting and aggregating local features across different parties. We proved that Proto-EVFL, as the first bi-level optimization framework in VFL, has a convergence rate of 1/\sqrt T. Extensive experiments on various datasets validate the superiority of our Proto-EVFL. Even in a zero-shot scenario with one unseen class, it outperforms baselines by at least 6.97%
CDC: Causal Domain Clustering for Multi-Domain Recommendation
Jul 09, 2025Multi-domain recommendation leverages domain-general knowledge to improve recommendations across several domains. However, as platforms expand to dozens or hundreds of scenarios, training all domains in a unified model leads to performance degradation due to significant inter-domain differences. Existing domain grouping methods, based on business logic or data similarities, often fail to capture the true transfer relationships required for optimal grouping. To effectively cluster domains, we propose Causal Domain Clustering (CDC). CDC models domain transfer patterns within a large number of domains using two distinct effects: the Isolated Domain Affinity Matrix for modeling non-interactive domain transfers, and the Hybrid Domain Affinity Matrix for considering dynamic domain synergy or interference under joint training. To integrate these two transfer effects, we introduce causal discovery to calculate a cohesion-based coefficient that adaptively balances their contributions. A Co-Optimized Dynamic Clustering algorithm iteratively optimizes target domain clustering and source domain selection for training. CDC significantly enhances performance across over 50 domains on public datasets and in industrial settings, achieving a 4.9% increase in online eCPM. Code is available at https://github.com/Chrissie-Law/Causal-Domain-Clustering-for-Multi-Domain-Recommendation