 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCKT: Fine-Grained Cross-Task Knowledge Transfer with Semantic Contrastive Learning for Targeted Sentiment Analysis
May 28, 2025In this paper, we address the task of targeted sentiment analysis (TSA), which involves two sub-tasks, i.e., identifying specific aspects from reviews and determining their corresponding sentiments. Aspect extraction forms the foundation for sentiment prediction, highlighting the critical dependency between these two tasks for effective cross-task knowledge transfer. While most existing studies adopt a multi-task learning paradigm to align task-specific features in the latent space, they predominantly rely on coarse-grained knowledge transfer. Such approaches lack fine-grained control over aspect-sentiment relationships, often assuming uniform sentiment polarity within related aspects. This oversimplification neglects contextual cues that differentiate sentiments, leading to negative transfer. To overcome these limitations, we propose FCKT, a fine-grained cross-task knowledge transfer framework tailored for TSA. By explicitly incorporating aspect-level information into sentiment prediction, FCKT achieves fine-grained knowledge transfer, effectively mitigating negative transfer and enhancing task performance. Experiments on three datasets, including comparisons with various baselines and large language models (LLMs), demonstrate the effectiveness of FCKT. The source code is available on https://github.com/cwei01/FCKT.
Benchmarking Large Multimodal Models for Ophthalmic Visual Question Answering with OphthalWeChat
May 26, 2025Purpose: To develop a bilingual multimodal visual question answering (VQA) benchmark for evaluating VLMs in ophthalmology. Methods: Ophthalmic image posts and associated captions published between January 1, 2016, and December 31, 2024, were collected from WeChat Official Accounts. Based on these captions, bilingual question-answer (QA) pairs in Chinese and English were generated using GPT-4o-mini. QA pairs were categorized into six subsets by question type and language: binary (Binary_CN, Binary_EN), single-choice (Single-choice_CN, Single-choice_EN), and open-ended (Open-ended_CN, Open-ended_EN). The benchmark was used to evaluate the performance of three VLMs: GPT-4o, Gemini 2.0 Flash, and Qwen2.5-VL-72B-Instruct. Results: The final OphthalWeChat dataset included 3,469 images and 30,120 QA pairs across 9 ophthalmic subspecialties, 548 conditions, 29 imaging modalities, and 68 modality combinations. Gemini 2.0 Flash achieved the highest overall accuracy (0.548), outperforming GPT-4o (0.522, P < 0.001) and Qwen2.5-VL-72B-Instruct (0.514, P < 0.001). It also led in both Chinese (0.546) and English subsets (0.550). Subset-specific performance showed Gemini 2.0 Flash excelled in Binary_CN (0.687), Single-choice_CN (0.666), and Single-choice_EN (0.646), while GPT-4o ranked highest in Binary_EN (0.717), Open-ended_CN (BLEU-1: 0.301; BERTScore: 0.382), and Open-ended_EN (BLEU-1: 0.183; BERTScore: 0.240). Conclusions: This study presents the first bilingual VQA benchmark for ophthalmology, distinguished by its real-world context and inclusion of multiple examinations per patient. The dataset reflects authentic clinical decision-making scenarios and enables quantitative evaluation of VLMs, supporting the development of accurate, specialized, and trustworthy AI systems for eye care.
Hyperbolic Diffusion Recommender Model
Apr 02, 2025Diffusion models (DMs) have emerged as the new state-of-the-art family of deep generative models. To gain deeper insights into the limitations of diffusion models in recommender systems, we investigate the fundamental structural disparities between images and items. Consequently, items often exhibit distinct anisotropic and directional structures that are less prevalent in images. However, the traditional forward diffusion process continuously adds isotropic Gaussian noise, causing anisotropic signals to degrade into noise, which impairs the semantically meaningful representations in recommender systems. Inspired by the advancements in hyperbolic spaces, we propose a novel \textit{\textbf{H}yperbolic} \textit{\textbf{D}iffusion} \textit{\textbf{R}ecommender} \textit{\textbf{M}odel} (named HDRM). Unlike existing directional diffusion methods based on Euclidean space, the intrinsic non-Euclidean structure of hyperbolic space makes it particularly well-adapted for handling anisotropic diffusion processes. In particular, we begin by formulating concepts to characterize latent directed diffusion processes within a geometrically grounded hyperbolic space. Subsequently, we propose a novel hyperbolic latent diffusion process specifically tailored for users and items. Drawing upon the natural geometric attributes of hyperbolic spaces, we impose structural restrictions on the space to enhance hyperbolic diffusion propagation, thereby ensuring the preservation of the intrinsic topology of user-item graphs. Extensive experiments on three benchmark datasets demonstrate the effectiveness of HDRM.
Bridging Social Psychology and LLM Reasoning: Conflict-Aware Meta-Review Generation via Cognitive Alignment
Mar 21, 2025The rapid growth of scholarly submissions has overwhelmed traditional peer review systems, driving the need for intelligent automation to preserve scientific rigor. While large language models (LLMs) show promise in automating manuscript critiques, their ability to synthesize high-stakes meta-reviews, which require conflict-aware reasoning and consensus derivation, remains underdeveloped. Existing methods fail to effectively handle conflicting viewpoints within differing opinions, and often introduce additional cognitive biases, such as anchoring effects and conformity bias.To overcome these limitations, we propose the Cognitive Alignment Framework (CAF), a dual-process architecture that transforms LLMs into adaptive scientific arbitrators. By operationalizing Kahneman's dual-process theory, CAF introduces a three-step cognitive pipeline: review initialization, incremental integration, and cognitive alignment.Empirical validation shows that CAF outperforms existing LLM-based methods, with sentiment consistency gains reaching up to 19.47\% and content consistency improving by as much as 12.95\%.
FairDgcl: Fairness-aware Recommendation with Dynamic Graph Contrastive Learning
Oct 23, 2024



As trustworthy AI continues to advance, the fairness issue in recommendations has received increasing attention. A recommender system is considered unfair when it produces unequal outcomes for different user groups based on user-sensitive attributes (e.g., age, gender). Some researchers have proposed data augmentation-based methods aiming at alleviating user-level unfairness by altering the skewed distribution of training data among various user groups. Despite yielding promising results, they often rely on fairness-related assumptions that may not align with reality, potentially reducing the data quality and negatively affecting model effectiveness. To tackle this issue, in this paper, we study how to implement high-quality data augmentation to improve recommendation fairness. Specifically, we propose FairDgcl, a dynamic graph adversarial contrastive learning framework aiming at improving fairness in recommender system. First, FairDgcl develops an adversarial contrastive network with a view generator and a view discriminator to learn generating fair augmentation strategies in an adversarial style. Then, we propose two dynamic, learnable models to generate contrastive views within contrastive learning framework, which automatically fine-tune the augmentation strategies. Meanwhile, we theoretically show that FairDgcl can simultaneously generate enhanced representations that possess both fairness and accuracy. Lastly, comprehensive experiments conducted on four real-world datasets demonstrate the effectiveness of the proposed FairDgcl.
Knowledge-based Multiple Adaptive Spaces Fusion for Recommendation
Aug 29, 2023Since Knowledge Graphs (KGs) contain rich semantic information, recently there has been an influx of KG-enhanced recommendation methods. Most of existing methods are entirely designed based on euclidean space without considering curvature. However, recent studies have revealed that a tremendous graph-structured data exhibits highly non-euclidean properties. Motivated by these observations, in this work, we propose a knowledge-based multiple adaptive spaces fusion method for recommendation, namely MCKG. Unlike existing methods that solely adopt a specific manifold, we introduce the unified space that is compatible with hyperbolic, euclidean and spherical spaces. Furthermore, we fuse the multiple unified spaces in an attention manner to obtain the high-quality embeddings for better knowledge propagation. In addition, we propose a geometry-aware optimization strategy which enables the pull and push processes benefited from both hyperbolic and spherical spaces. Specifically, in hyperbolic space, we set smaller margins in the area near to the origin, which is conducive to distinguishing between highly similar positive items and negative ones. At the same time, we set larger margins in the area far from the origin to ensure the model has sufficient error tolerance. The similar manner also applies to spherical spaces. Extensive experiments on three real-world datasets demonstrate that the MCKG has a significant improvement over state-of-the-art recommendation methods. Further ablation experiments verify the importance of multi-space fusion and geometry-aware optimization strategy, justifying the rationality and effectiveness of MCKG.
Graceful User Following for Mobile Balance Assistive Robot in Daily Activities Assistance
Apr 18, 2023Numerous diseases and aging can cause degeneration of people's balance ability resulting in limited mobility and even high risks of fall. Robotic technologies can provide more intensive rehabilitation exercises or be used as assistive devices to compensate for balance ability. However, With the new healthcare paradigm shifting from hospital care to home care, there is a gap in robotic systems that can provide care at home. This paper introduces Mobile Robotic Balance Assistant (MRBA), a compact and cost-effective balance assistive robot that can provide both rehabilitation training and activities of daily living (ADLs) assistance at home. A three degrees of freedom (3-DoF) robotic arm was designed to mimic the therapist arm function to provide balance assistance to the user. To minimize the interference to users' natural pelvis movements and gait patterns, the robot must have a Human-Robot Interface(HRI) that can detect user intention accurately and follow the user's movement smoothly and timely. Thus, a graceful user following control rule was proposed. The overall control architecture consists of two parts: an observer for human inputs estimation and an LQR-based controller with disturbance rejection. The proposed controller is validated in high-fidelity simulation with actual human trajectories, and the results successfully show the effectiveness of the method in different walking modes.
A Review of Computer Vision Technologies for Fish Tracking
Oct 11, 2021
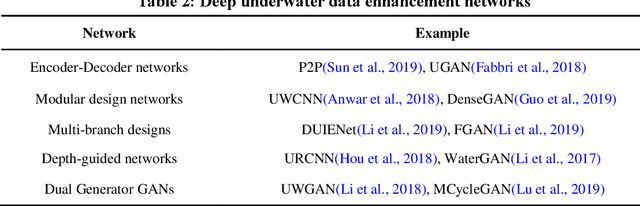
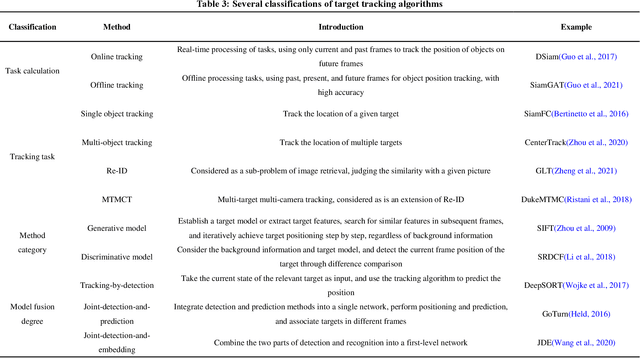
Fish tracking based on computer vision is a complex and challenging task in fishery production and ecological studies. Most of the applications of fish tracking use classic filtering algorithms, which lack in accuracy and efficiency. To solve this issue, deep learning methods utilized deep neural networks to extract the features, which achieve a good performance in the fish tracking. Some one-stage detection algorithms have gradually been adopted in this area for the real-time applications. The transfer learning to fish target is the current development direction. At present, fish tracking technology is not enough to cover actual application requirements. According to the literature data collected by us, there has not been any extensive review about vision-based fish tracking in the community. In this paper, we introduced the development and application prospects of fish tracking technology in last ten years. Firstly, we introduced the open source datasets of fish, and summarized the preprocessing technologies of underwater images. Secondly, we analyzed the detection and tracking algorithms for fish, and sorted out some transferable frontier tracking model. Thirdly, we listed the actual applications, metrics and bottlenecks of the fish tracking such as occlusion and multi-scale. Finally, we give the discussion for fish tracking datasets, solutions of the bottlenecks, and improvements. We expect that our work can help the fish tracking models to achieve higher accuracy and robustness.
A Deep Learning-based Quality Assessment and Segmentation System with a Large-scale Benchmark Dataset for Optical Coherence Tomographic Angiography Image
Jul 22, 2021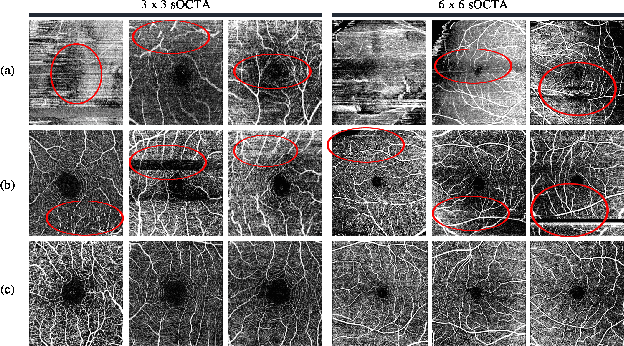
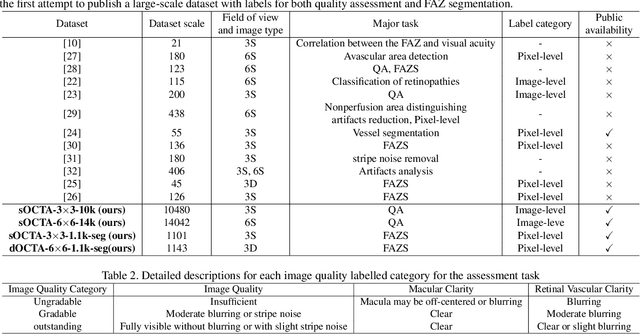
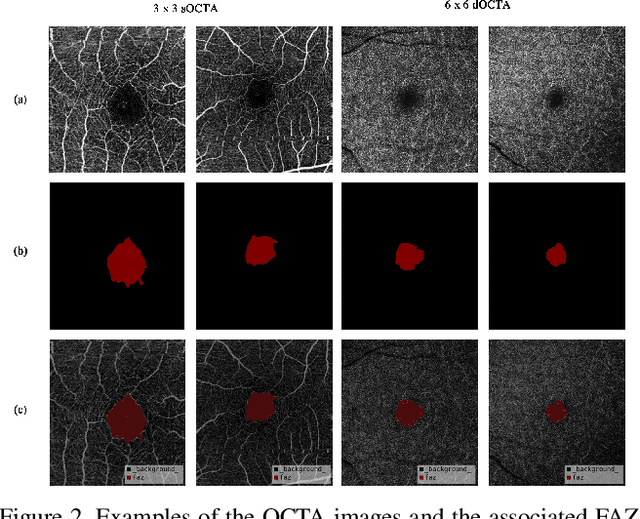
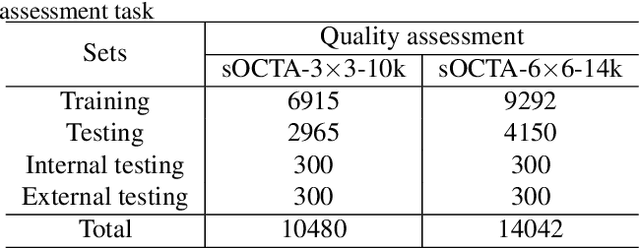
Optical Coherence Tomography Angiography (OCTA) is a non-invasive and non-contacting imaging technique providing visualization of microvasculature of retina and optic nerve head in human eyes in vivo. The adequate image quality of OCTA is the prerequisite for the subsequent quantification of retinal microvasculature. Traditionally, the image quality score based on signal strength is used for discriminating low quality. However, it is insufficient for identifying artefacts such as motion and off-centration, which rely specialized knowledge and need tedious and time-consuming manual identification. One of the most primary issues in OCTA analysis is to sort out the foveal avascular zone (FAZ) region in the retina, which highly correlates with any visual acuity disease. However, the variations in OCTA visual quality affect the performance of deep learning in any downstream marginally. Moreover, filtering the low-quality OCTA images out is both labor-intensive and time-consuming. To address these issues, we develop an automated computer-aided OCTA image processing system using deep neural networks as the classifier and segmentor to help ophthalmologists in clinical diagnosis and research. This system can be an assistive tool as it can process OCTA images of different formats to assess the quality and segment the FAZ area. The source code is freely available at https://github.com/shanzha09/COIPS.git. Another major contribution is the large-scale OCTA dataset, namely OCTA-25K-IQA-SEG we publicize for performance evaluation. It is comprised of four subsets, namely sOCTA-3$\times$3-10k, sOCTA-6$\times$6-14k, sOCTA-3$\times$3-1.1k-seg, and dOCTA-6$\times$6-1.1k-seg, which contains a total number of 25,665 images. The large-scale OCTA dataset is available at https://doi.org/10.5281/zenodo.5111975, https://doi.org/10.5281/zenodo.5111972.
Minor Privacy Protection Through Real-time Video Processing at the Edge
May 03, 2020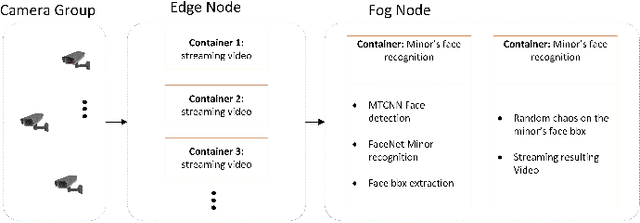
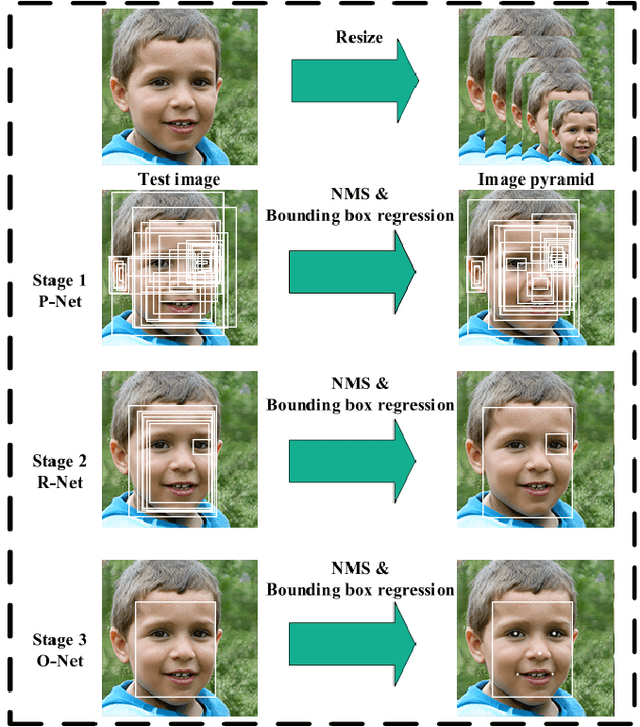
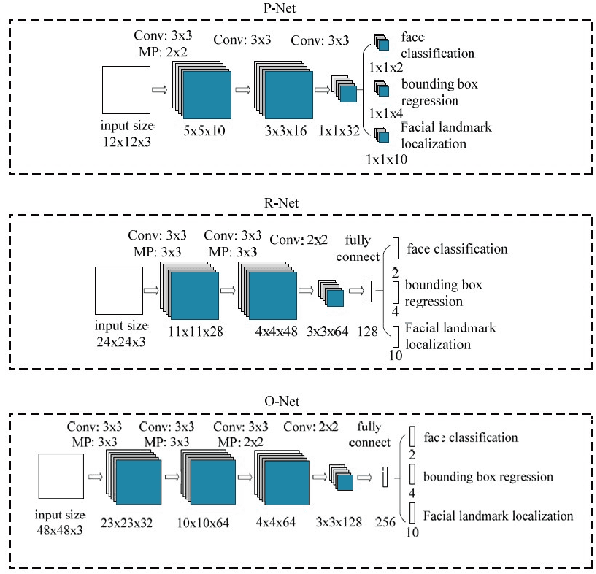

The collection of a lot of personal information about individuals, including the minor members of a family, by closed-circuit television (CCTV) cameras creates a lot of privacy concerns. Particularly, revealing children's identifications or activities may compromise their well-being. In this paper, we investigate lightweight solutions that are affordable to edge surveillance systems, which is made feasible and accurate to identify minors such that appropriate privacy-preserving measures can be applied accordingly. State of the art deep learning architectures are modified and re-purposed in a cascaded fashion to maximize the accuracy of our model. A pipeline extracts faces from the input frames and classifies each one to be of an adult or a child. Over 20,000 labeled sample points are used for classification. We explore the timing and resources needed for such a model to be used in the Edge-Fog architecture at the edge of the network, where we can achieve near real-time performance on the CPU. Quantitative experimental results show the superiority of our proposed model with an accuracy of 92.1% in classification compared to some other face recognition based child detection approaches.