 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEyeWorld: A Generative World Model of Ocular State and Dynamics
Mar 14, 2026Ophthalmic decision-making depends on subtle lesion-scale cues interpreted across multimodal imaging and over time, yet most medical foundation models remain static and degrade under modality and acquisition shifts. Here we introduce EyeWorld, a generative world model that conceptualizes the eye as a partially observed dynamical system grounded in clinical imaging. EyeWorld learns an observation-stable latent ocular state shared across modalities, unifying fine-grained parsing, structure-preserving cross-modality translation and quality-robust enhancement within a single framework. Longitudinal supervision further enables time-conditioned state transitions, supporting forecasting of clinically meaningful progression while preserving stable anatomy. By moving from static representation learning to explicit dynamical modeling, EyeWorld provides a unified approach to robust multimodal interpretation and prognosis-oriented simulation in medicine.
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Benchmarking Large Multimodal Models for Ophthalmic Visual Question Answering with OphthalWeChat
May 26, 2025Purpose: To develop a bilingual multimodal visual question answering (VQA) benchmark for evaluating VLMs in ophthalmology. Methods: Ophthalmic image posts and associated captions published between January 1, 2016, and December 31, 2024, were collected from WeChat Official Accounts. Based on these captions, bilingual question-answer (QA) pairs in Chinese and English were generated using GPT-4o-mini. QA pairs were categorized into six subsets by question type and language: binary (Binary_CN, Binary_EN), single-choice (Single-choice_CN, Single-choice_EN), and open-ended (Open-ended_CN, Open-ended_EN). The benchmark was used to evaluate the performance of three VLMs: GPT-4o, Gemini 2.0 Flash, and Qwen2.5-VL-72B-Instruct. Results: The final OphthalWeChat dataset included 3,469 images and 30,120 QA pairs across 9 ophthalmic subspecialties, 548 conditions, 29 imaging modalities, and 68 modality combinations. Gemini 2.0 Flash achieved the highest overall accuracy (0.548), outperforming GPT-4o (0.522, P < 0.001) and Qwen2.5-VL-72B-Instruct (0.514, P < 0.001). It also led in both Chinese (0.546) and English subsets (0.550). Subset-specific performance showed Gemini 2.0 Flash excelled in Binary_CN (0.687), Single-choice_CN (0.666), and Single-choice_EN (0.646), while GPT-4o ranked highest in Binary_EN (0.717), Open-ended_CN (BLEU-1: 0.301; BERTScore: 0.382), and Open-ended_EN (BLEU-1: 0.183; BERTScore: 0.240). Conclusions: This study presents the first bilingual VQA benchmark for ophthalmology, distinguished by its real-world context and inclusion of multiple examinations per patient. The dataset reflects authentic clinical decision-making scenarios and enables quantitative evaluation of VLMs, supporting the development of accurate, specialized, and trustworthy AI systems for eye care.
Predicting Diabetic Macular Edema Treatment Responses Using OCT: Dataset and Methods of APTOS Competition
May 09, 2025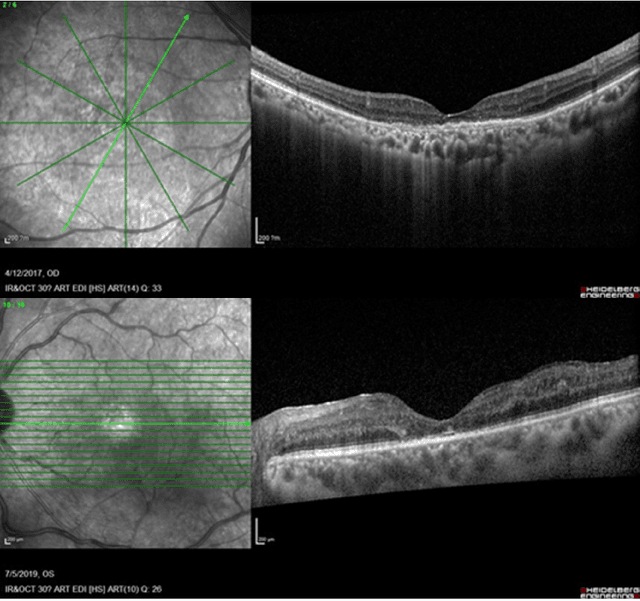
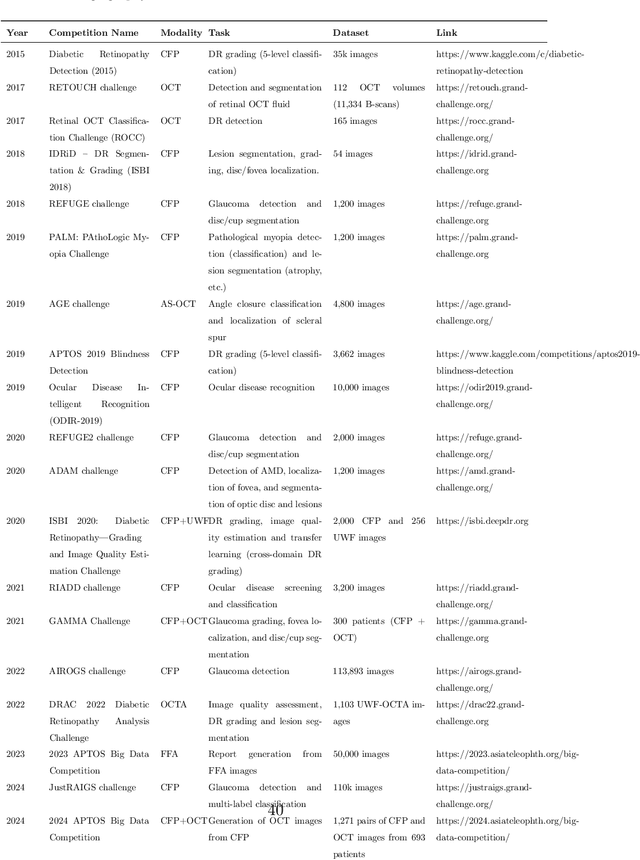
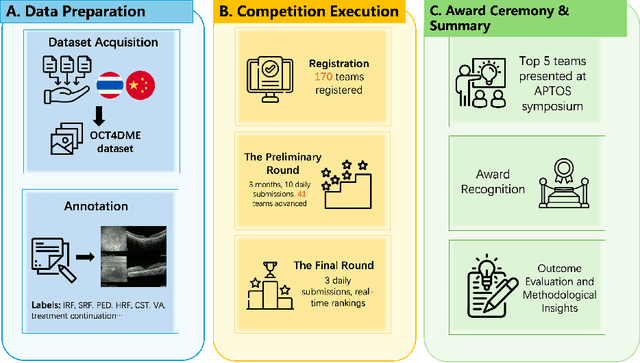

Diabetic macular edema (DME) significantly contributes to visual impairment in diabetic patients. Treatment responses to intravitreal therapies vary, highlighting the need for patient stratification to predict therapeutic benefits and enable personalized strategies. To our knowledge, this study is the first to explore pre-treatment stratification for predicting DME treatment responses. To advance this research, we organized the 2nd Asia-Pacific Tele-Ophthalmology Society (APTOS) Big Data Competition in 2021. The competition focused on improving predictive accuracy for anti-VEGF therapy responses using ophthalmic OCT images. We provided a dataset containing tens of thousands of OCT images from 2,000 patients with labels across four sub-tasks. This paper details the competition's structure, dataset, leading methods, and evaluation metrics. The competition attracted strong scientific community participation, with 170 teams initially registering and 41 reaching the final round. The top-performing team achieved an AUC of 80.06%, highlighting the potential of AI in personalized DME treatment and clinical decision-making.
AI-powered virtual eye: perspective, challenges and opportunities
May 07, 2025We envision the "virtual eye" as a next-generation, AI-powered platform that uses interconnected foundation models to simulate the eye's intricate structure and biological function across all scales. Advances in AI, imaging, and multiomics provide a fertile ground for constructing a universal, high-fidelity digital replica of the human eye. This perspective traces the evolution from early mechanistic and rule-based models to contemporary AI-driven approaches, integrating in a unified model with multimodal, multiscale, dynamic predictive capabilities and embedded feedback mechanisms. We propose a development roadmap emphasizing the roles of large-scale multimodal datasets, generative AI, foundation models, agent-based architectures, and interactive interfaces. Despite challenges in interpretability, ethics, data processing and evaluation, the virtual eye holds the potential to revolutionize personalized ophthalmic care and accelerate research into ocular health and disease.
Interpretable Few-Shot Retinal Disease Diagnosis with Concept-Guided Prompting of Vision-Language Models
Mar 04, 2025Recent advancements in deep learning have shown significant potential for classifying retinal diseases using color fundus images. However, existing works predominantly rely exclusively on image data, lack interpretability in their diagnostic decisions, and treat medical professionals primarily as annotators for ground truth labeling. To fill this gap, we implement two key strategies: extracting interpretable concepts of retinal diseases using the knowledge base of GPT models and incorporating these concepts as a language component in prompt-learning to train vision-language (VL) models with both fundus images and their associated concepts. Our method not only improves retinal disease classification but also enriches few-shot and zero-shot detection (novel disease detection), while offering the added benefit of concept-based model interpretability. Our extensive evaluation across two diverse retinal fundus image datasets illustrates substantial performance gains in VL-model based few-shot methodologies through our concept integration approach, demonstrating an average improvement of approximately 5.8\% and 2.7\% mean average precision for 16-shot learning and zero-shot (novel class) detection respectively. Our method marks a pivotal step towards interpretable and efficient retinal disease recognition for real-world clinical applications.
DeepSeek-R1 Outperforms Gemini 2.0 Pro, OpenAI o1, and o3-mini in Bilingual Complex Ophthalmology Reasoning
Feb 25, 2025Purpose: To evaluate the accuracy and reasoning ability of DeepSeek-R1 and three other recently released large language models (LLMs) in bilingual complex ophthalmology cases. Methods: A total of 130 multiple-choice questions (MCQs) related to diagnosis (n = 39) and management (n = 91) were collected from the Chinese ophthalmology senior professional title examination and categorized into six topics. These MCQs were translated into English using DeepSeek-R1. The responses of DeepSeek-R1, Gemini 2.0 Pro, OpenAI o1 and o3-mini were generated under default configurations between February 15 and February 20, 2025. Accuracy was calculated as the proportion of correctly answered questions, with omissions and extra answers considered incorrect. Reasoning ability was evaluated through analyzing reasoning logic and the causes of reasoning error. Results: DeepSeek-R1 demonstrated the highest overall accuracy, achieving 0.862 in Chinese MCQs and 0.808 in English MCQs. Gemini 2.0 Pro, OpenAI o1, and OpenAI o3-mini attained accuracies of 0.715, 0.685, and 0.692 in Chinese MCQs (all P<0.001 compared with DeepSeek-R1), and 0.746 (P=0.115), 0.723 (P=0.027), and 0.577 (P<0.001) in English MCQs, respectively. DeepSeek-R1 achieved the highest accuracy across five topics in both Chinese and English MCQs. It also excelled in management questions conducted in Chinese (all P<0.05). Reasoning ability analysis showed that the four LLMs shared similar reasoning logic. Ignoring key positive history, ignoring key positive signs, misinterpretation medical data, and too aggressive were the most common causes of reasoning errors. Conclusion: DeepSeek-R1 demonstrated superior performance in bilingual complex ophthalmology reasoning tasks than three other state-of-the-art LLMs. While its clinical applicability remains challenging, it shows promise for supporting diagnosis and clinical decision-making.
Fundus2Globe: Generative AI-Driven 3D Digital Twins for Personalized Myopia Management
Feb 18, 2025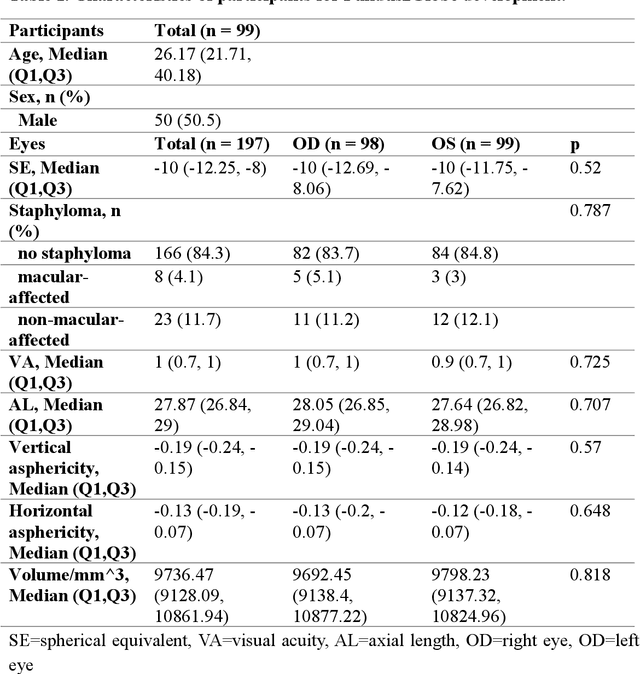
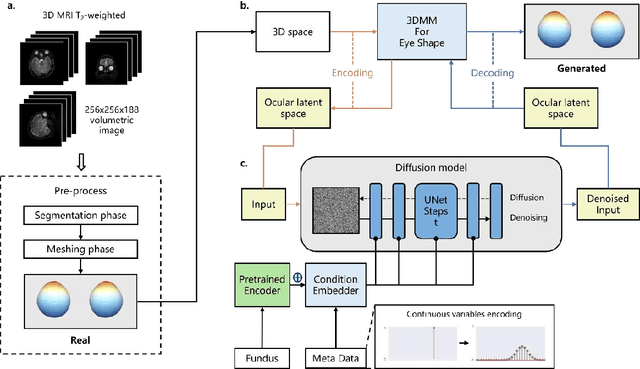
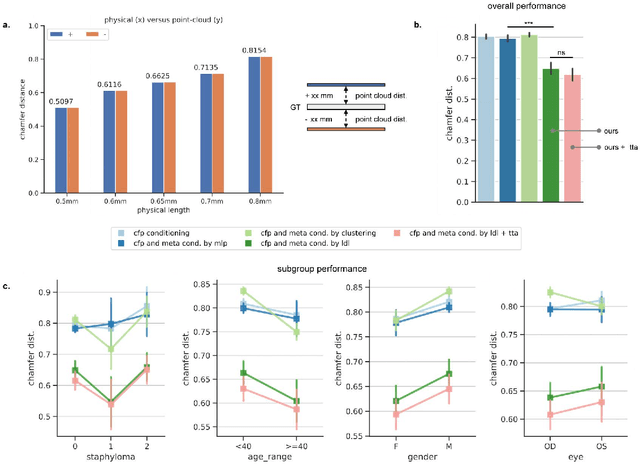
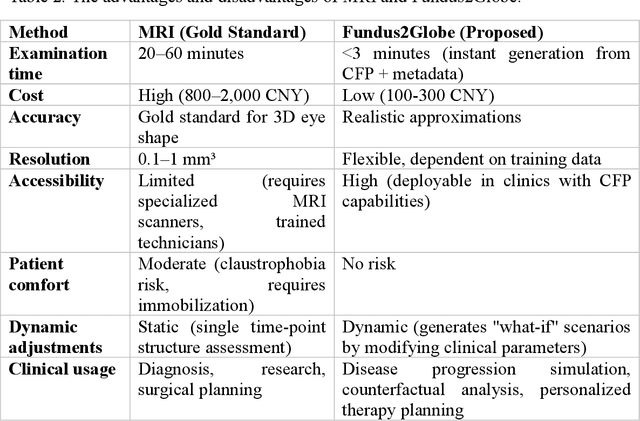
Myopia, projected to affect 50% population globally by 2050, is a leading cause of vision loss. Eyes with pathological myopia exhibit distinctive shape distributions, which are closely linked to the progression of vision-threatening complications. Recent understanding of eye-shape-based biomarkers requires magnetic resonance imaging (MRI), however, it is costly and unrealistic in routine ophthalmology clinics. We present Fundus2Globe, the first AI framework that synthesizes patient-specific 3D eye globes from ubiquitous 2D color fundus photographs (CFPs) and routine metadata (axial length, spherical equivalent), bypassing MRI dependency. By integrating a 3D morphable eye model (encoding biomechanical shape priors) with a latent diffusion model, our approach achieves submillimeter accuracy in reconstructing posterior ocular anatomy efficiently. Fundus2Globe uniquely quantifies how vision-threatening lesions (e.g., staphylomas) in CFPs correlate with MRI-validated 3D shape abnormalities, enabling clinicians to simulate posterior segment changes in response to refractive shifts. External validation demonstrates its robust generation performance, ensuring fairness across underrepresented groups. By transforming 2D fundus imaging into 3D digital replicas of ocular structures, Fundus2Globe is a gateway for precision ophthalmology, laying the foundation for AI-driven, personalized myopia management.
FFA Sora, video generation as fundus fluorescein angiography simulator
Dec 23, 2024



Fundus fluorescein angiography (FFA) is critical for diagnosing retinal vascular diseases, but beginners often struggle with image interpretation. This study develops FFA Sora, a text-to-video model that converts FFA reports into dynamic videos via a Wavelet-Flow Variational Autoencoder (WF-VAE) and a diffusion transformer (DiT). Trained on an anonymized dataset, FFA Sora accurately simulates disease features from the input text, as confirmed by objective metrics: Frechet Video Distance (FVD) = 329.78, Learned Perceptual Image Patch Similarity (LPIPS) = 0.48, and Visual-question-answering Score (VQAScore) = 0.61. Specific evaluations showed acceptable alignment between the generated videos and textual prompts, with BERTScore of 0.35. Additionally, the model demonstrated strong privacy-preserving performance in retrieval evaluations, achieving an average Recall@K of 0.073. Human assessments indicated satisfactory visual quality, with an average score of 1.570(scale: 1 = best, 5 = worst). This model addresses privacy concerns associated with sharing large-scale FFA data and enhances medical education.
EyeDiff: text-to-image diffusion model improves rare eye disease diagnosis
Nov 15, 2024The rising prevalence of vision-threatening retinal diseases poses a significant burden on the global healthcare systems. Deep learning (DL) offers a promising solution for automatic disease screening but demands substantial data. Collecting and labeling large volumes of ophthalmic images across various modalities encounters several real-world challenges, especially for rare diseases. Here, we introduce EyeDiff, a text-to-image model designed to generate multimodal ophthalmic images from natural language prompts and evaluate its applicability in diagnosing common and rare diseases. EyeDiff is trained on eight large-scale datasets using the advanced latent diffusion model, covering 14 ophthalmic image modalities and over 80 ocular diseases, and is adapted to ten multi-country external datasets. The generated images accurately capture essential lesional characteristics, achieving high alignment with text prompts as evaluated by objective metrics and human experts. Furthermore, integrating generated images significantly enhances the accuracy of detecting minority classes and rare eye diseases, surpassing traditional oversampling methods in addressing data imbalance. EyeDiff effectively tackles the issue of data imbalance and insufficiency typically encountered in rare diseases and addresses the challenges of collecting large-scale annotated images, offering a transformative solution to enhance the development of expert-level diseases diagnosis models in ophthalmic field.