 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHiRPE: A Step Towards Real-World Clinical NLP with Clinician-Oriented Model Explanations
Jan 26, 2026The medical adoption of NLP tools requires interpretability by end users, yet traditional explainable AI (XAI) methods are misaligned with clinical reasoning and lack clinician input. We introduce CHiRPE (Clinical High-Risk Prediction with Explainability), an NLP pipeline that takes transcribed semi-structured clinical interviews to: (i) predict psychosis risk; and (ii) generate novel SHAP explanation formats co-developed with clinicians. Trained on 944 semi-structured interview transcripts across 24 international clinics of the AMP-SCZ study, the CHiRPE pipeline integrates symptom-domain mapping, LLM summarisation, and BERT classification. CHiRPE achieved over 90% accuracy across three BERT variants and outperformed baseline models. Explanation formats were evaluated by 28 clinical experts who indicated a strong preference for our novel concept-guided explanations, especially hybrid graph-and-text summary formats. CHiRPE demonstrates that clinically-guided model development produces both accurate and interpretable results. Our next step is focused on real-world testing across our 24 international sites.
PsychEthicsBench: Evaluating Large Language Models Against Australian Mental Health Ethics
Jan 07, 2026The increasing integration of large language models (LLMs) into mental health applications necessitates robust frameworks for evaluating professional safety alignment. Current evaluative approaches primarily rely on refusal-based safety signals, which offer limited insight into the nuanced behaviors required in clinical practice. In mental health, clinically inadequate refusals can be perceived as unempathetic and discourage help-seeking. To address this gap, we move beyond refusal-centric metrics and introduce \texttt{PsychEthicsBench}, the first principle-grounded benchmark based on Australian psychology and psychiatry guidelines, designed to evaluate LLMs' ethical knowledge and behavioral responses through multiple-choice and open-ended tasks with fine-grained ethicality annotations. Empirical results across 14 models reveal that refusal rates are poor indicators of ethical behavior, revealing a significant divergence between safety triggers and clinical appropriateness. Notably, we find that domain-specific fine-tuning can degrade ethical robustness, as several specialized models underperform their base backbones in ethical alignment. PsychEthicsBench provides a foundation for systematic, jurisdiction-aware evaluation of LLMs in mental health, encouraging more responsible development in this domain.
MAKE: Multi-Aspect Knowledge-Enhanced Vision-Language Pretraining for Zero-shot Dermatological Assessment
May 14, 2025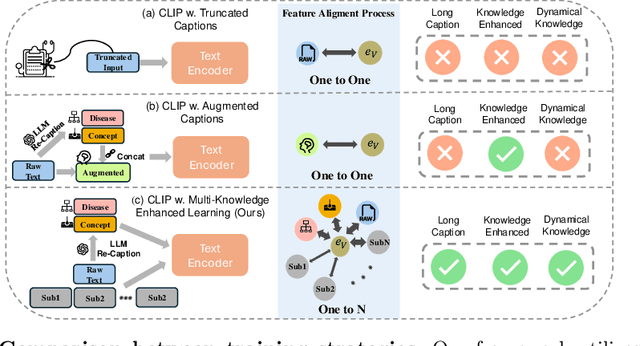
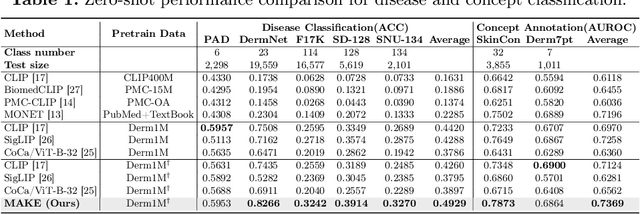
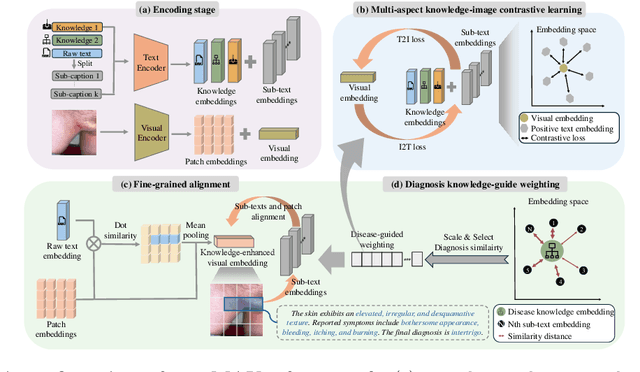
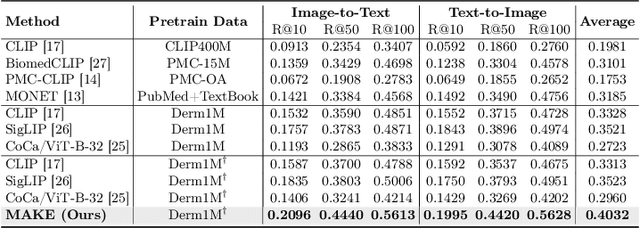
Dermatological diagnosis represents a complex multimodal challenge that requires integrating visual features with specialized clinical knowledge. While vision-language pretraining (VLP) has advanced medical AI, its effectiveness in dermatology is limited by text length constraints and the lack of structured texts. In this paper, we introduce MAKE, a Multi-Aspect Knowledge-Enhanced vision-language pretraining framework for zero-shot dermatological tasks. Recognizing that comprehensive dermatological descriptions require multiple knowledge aspects that exceed standard text constraints, our framework introduces: (1) a multi-aspect contrastive learning strategy that decomposes clinical narratives into knowledge-enhanced sub-texts through large language models, (2) a fine-grained alignment mechanism that connects subcaptions with diagnostically relevant image features, and (3) a diagnosis-guided weighting scheme that adaptively prioritizes different sub-captions based on clinical significance prior. Through pretraining on 403,563 dermatological image-text pairs collected from education resources, MAKE significantly outperforms state-of-the-art VLP models on eight datasets across zero-shot skin disease classification, concept annotation, and cross-modal retrieval tasks. Our code will be made publicly available at https: //github.com/SiyuanYan1/MAKE.
Derm1M: A Million-scale Vision-Language Dataset Aligned with Clinical Ontology Knowledge for Dermatology
Mar 19, 2025The emergence of vision-language models has transformed medical AI, enabling unprecedented advances in diagnostic capability and clinical applications. However, progress in dermatology has lagged behind other medical domains due to the lack of standard image-text pairs. Existing dermatological datasets are limited in both scale and depth, offering only single-label annotations across a narrow range of diseases instead of rich textual descriptions, and lacking the crucial clinical context needed for real-world applications. To address these limitations, we present Derm1M, the first large-scale vision-language dataset for dermatology, comprising 1,029,761 image-text pairs. Built from diverse educational resources and structured around a standard ontology collaboratively developed by experts, Derm1M provides comprehensive coverage for over 390 skin conditions across four hierarchical levels and 130 clinical concepts with rich contextual information such as medical history, symptoms, and skin tone. To demonstrate Derm1M potential in advancing both AI research and clinical application, we pretrained a series of CLIP-like models, collectively called DermLIP, on this dataset. The DermLIP family significantly outperforms state-of-the-art foundation models on eight diverse datasets across multiple tasks, including zero-shot skin disease classification, clinical and artifacts concept identification, few-shot/full-shot learning, and cross-modal retrieval. Our dataset and code will be public.
Interpretable Few-Shot Retinal Disease Diagnosis with Concept-Guided Prompting of Vision-Language Models
Mar 04, 2025Recent advancements in deep learning have shown significant potential for classifying retinal diseases using color fundus images. However, existing works predominantly rely exclusively on image data, lack interpretability in their diagnostic decisions, and treat medical professionals primarily as annotators for ground truth labeling. To fill this gap, we implement two key strategies: extracting interpretable concepts of retinal diseases using the knowledge base of GPT models and incorporating these concepts as a language component in prompt-learning to train vision-language (VL) models with both fundus images and their associated concepts. Our method not only improves retinal disease classification but also enriches few-shot and zero-shot detection (novel disease detection), while offering the added benefit of concept-based model interpretability. Our extensive evaluation across two diverse retinal fundus image datasets illustrates substantial performance gains in VL-model based few-shot methodologies through our concept integration approach, demonstrating an average improvement of approximately 5.8\% and 2.7\% mean average precision for 16-shot learning and zero-shot (novel class) detection respectively. Our method marks a pivotal step towards interpretable and efficient retinal disease recognition for real-world clinical applications.