 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Question Answering in Ophthalmology: A Progressive and Practical Perspective
Paper and Code
Oct 22, 2024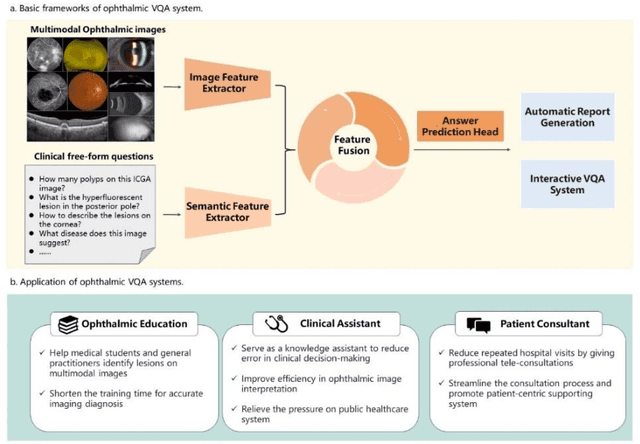
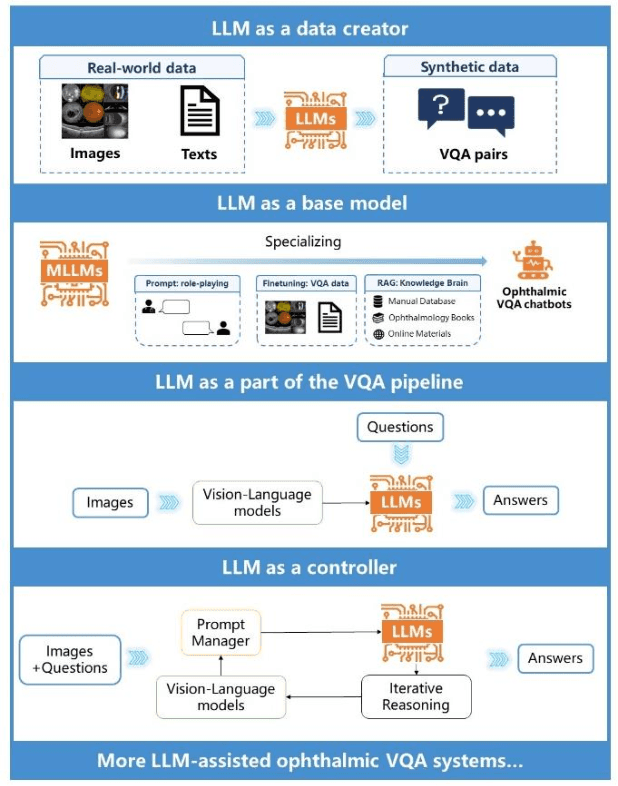
Accurate diagnosis of ophthalmic diseases relies heavily on the interpretation of multimodal ophthalmic images, a process often time-consuming and expertise-dependent. Visual Question Answering (VQA) presents a potential interdisciplinary solution by merging computer vision and natural language processing to comprehend and respond to queries about medical images. This review article explores the recent advancements and future prospects of VQA in ophthalmology from both theoretical and practical perspectives, aiming to provide eye care professionals with a deeper understanding and tools for leveraging the underlying models. Additionally, we discuss the promising trend of large language models (LLM) in enhancing various components of the VQA framework to adapt to multimodal ophthalmic tasks. Despite the promising outlook, ophthalmic VQA still faces several challenges, including the scarcity of annotated multimodal image datasets, the necessity of comprehensive and unified evaluation methods, and the obstacles to achieving effective real-world applications. This article highlights these challenges and clarifies future directions for advancing ophthalmic VQA with LLMs. The development of LLM-based ophthalmic VQA systems calls for collaborative efforts between medical professionals and AI experts to overcome existing obstacles and advance the diagnosis and care of eye diseases.