 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDid Models Sufficient Learn? Attribution-Guided Training via Subset-Selected Counterfactual Augmentation
Nov 15, 2025In current visual model training, models often rely on only limited sufficient causes for their predictions, which makes them sensitive to distribution shifts or the absence of key features. Attribution methods can accurately identify a model's critical regions. However, masking these areas to create counterfactuals often causes the model to misclassify the target, while humans can still easily recognize it. This divergence highlights that the model's learned dependencies may not be sufficiently causal. To address this issue, we propose Subset-Selected Counterfactual Augmentation (SS-CA), which integrates counterfactual explanations directly into the training process for targeted intervention. Building on the subset-selection-based LIMA attribution method, we develop Counterfactual LIMA to identify minimal spatial region sets whose removal can selectively alter model predictions. Leveraging these attributions, we introduce a data augmentation strategy that replaces the identified regions with natural background, and we train the model jointly on both augmented and original samples to mitigate incomplete causal learning. Extensive experiments across multiple ImageNet variants show that SS-CA improves generalization on in-distribution (ID) test data and achieves superior performance on out-of-distribution (OOD) benchmarks such as ImageNet-R and ImageNet-S. Under perturbations including noise, models trained with SS-CA also exhibit enhanced generalization, demonstrating that our approach effectively uses interpretability insights to correct model deficiencies and improve both performance and robustness.
PhaseWin Search Framework Enable Efficient Object-Level Interpretation
Nov 14, 2025Attribution is essential for interpreting object-level foundation models. Recent methods based on submodular subset selection have achieved high faithfulness, but their efficiency limitations hinder practical deployment in real-world scenarios. To address this, we propose PhaseWin, a novel phase-window search algorithm that enables faithful region attribution with near-linear complexity. PhaseWin replaces traditional quadratic-cost greedy selection with a phased coarse-to-fine search, combining adaptive pruning, windowed fine-grained selection, and dynamic supervision mechanisms to closely approximate greedy behavior while dramatically reducing model evaluations. Theoretically, PhaseWin retains near-greedy approximation guarantees under mild monotone submodular assumptions. Empirically, PhaseWin achieves over 95% of greedy attribution faithfulness using only 20% of the computational budget, and consistently outperforms other attribution baselines across object detection and visual grounding tasks with Grounding DINO and Florence-2. PhaseWin establishes a new state of the art in scalable, high-faithfulness attribution for object-level multimodal models.
Where MLLMs Attend and What They Rely On: Explaining Autoregressive Token Generation
Sep 26, 2025Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in aligning visual inputs with natural language outputs. Yet, the extent to which generated tokens depend on visual modalities remains poorly understood, limiting interpretability and reliability. In this work, we present EAGLE, a lightweight black-box framework for explaining autoregressive token generation in MLLMs. EAGLE attributes any selected tokens to compact perceptual regions while quantifying the relative influence of language priors and perceptual evidence. The framework introduces an objective function that unifies sufficiency (insight score) and indispensability (necessity score), optimized via greedy search over sparsified image regions for faithful and efficient attribution. Beyond spatial attribution, EAGLE performs modality-aware analysis that disentangles what tokens rely on, providing fine-grained interpretability of model decisions. Extensive experiments across open-source MLLMs show that EAGLE consistently outperforms existing methods in faithfulness, localization, and hallucination diagnosis, while requiring substantially less GPU memory. These results highlight its effectiveness and practicality for advancing the interpretability of MLLMs. The code is available at https://github.com/RuoyuChen10/EAGLE.
Explaining multimodal LLMs via intra-modal token interactions
Sep 26, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse vision-language tasks, yet their internal decision-making mechanisms remain insufficiently understood. Existing interpretability research has primarily focused on cross-modal attribution, identifying which image regions the model attends to during output generation. However, these approaches often overlook intra-modal dependencies. In the visual modality, attributing importance to isolated image patches ignores spatial context due to limited receptive fields, resulting in fragmented and noisy explanations. In the textual modality, reliance on preceding tokens introduces spurious activations. Failing to effectively mitigate these interference compromises attribution fidelity. To address these limitations, we propose enhancing interpretability by leveraging intra-modal interaction. For the visual branch, we introduce \textit{Multi-Scale Explanation Aggregation} (MSEA), which aggregates attributions over multi-scale inputs to dynamically adjust receptive fields, producing more holistic and spatially coherent visual explanations. For the textual branch, we propose \textit{Activation Ranking Correlation} (ARC), which measures the relevance of contextual tokens to the current token via alignment of their top-$k$ prediction rankings. ARC leverages this relevance to suppress spurious activations from irrelevant contexts while preserving semantically coherent ones. Extensive experiments across state-of-the-art MLLMs and benchmark datasets demonstrate that our approach consistently outperforms existing interpretability methods, yielding more faithful and fine-grained explanations of model behavior.
SMA: Who Said That? Auditing Membership Leakage in Semi-Black-box RAG Controlling
Aug 12, 2025Retrieval-Augmented Generation (RAG) and its Multimodal Retrieval-Augmented Generation (MRAG) significantly improve the knowledge coverage and contextual understanding of Large Language Models (LLMs) by introducing external knowledge sources. However, retrieval and multimodal fusion obscure content provenance, rendering existing membership inference methods unable to reliably attribute generated outputs to pre-training, external retrieval, or user input, thus undermining privacy leakage accountability To address these challenges, we propose the first Source-aware Membership Audit (SMA) that enables fine-grained source attribution of generated content in a semi-black-box setting with retrieval control capabilities.To address the environmental constraints of semi-black-box auditing, we further design an attribution estimation mechanism based on zero-order optimization, which robustly approximates the true influence of input tokens on the output through large-scale perturbation sampling and ridge regression modeling. In addition, SMA introduces a cross-modal attribution technique that projects image inputs into textual descriptions via MLLMs, enabling token-level attribution in the text modality, which for the first time facilitates membership inference on image retrieval traces in MRAG systems. This work shifts the focus of membership inference from 'whether the data has been memorized' to 'where the content is sourced from', offering a novel perspective for auditing data provenance in complex generative systems.
Understanding and Benchmarking the Trustworthiness in Multimodal LLMs for Video Understanding
Jun 14, 2025Recent advancements in multimodal large language models for video understanding (videoLLMs) have improved their ability to process dynamic multimodal data. However, trustworthiness challenges factual inaccuracies, harmful content, biases, hallucinations, and privacy risks, undermine reliability due to video data's spatiotemporal complexities. This study introduces Trust-videoLLMs, a comprehensive benchmark evaluating videoLLMs across five dimensions: truthfulness, safety, robustness, fairness, and privacy. Comprising 30 tasks with adapted, synthetic, and annotated videos, the framework assesses dynamic visual scenarios, cross-modal interactions, and real-world safety concerns. Our evaluation of 23 state-of-the-art videoLLMs (5 commercial,18 open-source) reveals significant limitations in dynamic visual scene understanding and cross-modal perturbation resilience. Open-source videoLLMs show occasional truthfulness advantages but inferior overall credibility compared to commercial models, with data diversity outperforming scale effects. These findings highlight the need for advanced safety alignment to enhance capabilities. Trust-videoLLMs provides a publicly available, extensible toolbox for standardized trustworthiness assessments, bridging the gap between accuracy-focused benchmarks and critical demands for robustness, safety, fairness, and privacy.
APTOS-2024 challenge report: Generation of synthetic 3D OCT images from fundus photographs
Jun 09, 2025Optical Coherence Tomography (OCT) provides high-resolution, 3D, and non-invasive visualization of retinal layers in vivo, serving as a critical tool for lesion localization and disease diagnosis. However, its widespread adoption is limited by equipment costs and the need for specialized operators. In comparison, 2D color fundus photography offers faster acquisition and greater accessibility with less dependence on expensive devices. Although generative artificial intelligence has demonstrated promising results in medical image synthesis, translating 2D fundus images into 3D OCT images presents unique challenges due to inherent differences in data dimensionality and biological information between modalities. To advance generative models in the fundus-to-3D-OCT setting, the Asia Pacific Tele-Ophthalmology Society (APTOS-2024) organized a challenge titled Artificial Intelligence-based OCT Generation from Fundus Images. This paper details the challenge framework (referred to as APTOS-2024 Challenge), including: the benchmark dataset, evaluation methodology featuring two fidelity metrics-image-based distance (pixel-level OCT B-scan similarity) and video-based distance (semantic-level volumetric consistency), and analysis of top-performing solutions. The challenge attracted 342 participating teams, with 42 preliminary submissions and 9 finalists. Leading methodologies incorporated innovations in hybrid data preprocessing or augmentation (cross-modality collaborative paradigms), pre-training on external ophthalmic imaging datasets, integration of vision foundation models, and model architecture improvement. The APTOS-2024 Challenge is the first benchmark demonstrating the feasibility of fundus-to-3D-OCT synthesis as a potential solution for improving ophthalmic care accessibility in under-resourced healthcare settings, while helping to expedite medical research and clinical applications.
Unpacking Positional Encoding in Transformers: A Spectral Analysis of Content-Position Coupling
May 19, 2025Positional encoding (PE) is essential for enabling Transformers to model sequential structure. However, the mechanisms by which different PE schemes couple token content and positional information-and how these mechanisms influence model dynamics-remain theoretically underexplored. In this work, we present a unified framework that analyzes PE through the spectral properties of Toeplitz and related matrices derived from attention logits. We show that multiplicative content-position coupling-exemplified by Rotary Positional Encoding (RoPE) via a Hadamard product with a Toeplitz matrix-induces spectral contraction, which theoretically improves optimization stability and efficiency. Guided by this theory, we construct synthetic tasks that contrast content-position dependent and content-position independent settings, and evaluate a range of PE methods. Our experiments reveal strong alignment with theory: RoPE consistently outperforms other methods on position-sensitive tasks and induces "single-head deposit" patterns in early layers, indicating localized positional processing. Further analyses show that modifying the method and timing of PE coupling, such as MLA in Deepseek-V3, can effectively mitigate this concentration. These results establish explicit content-relative mixing with relative-position Toeplitz signals as a key principle for effective PE design and provide new insight into how positional structure is integrated in Transformer architectures.
FaceInsight: A Multimodal Large Language Model for Face Perception
Apr 22, 2025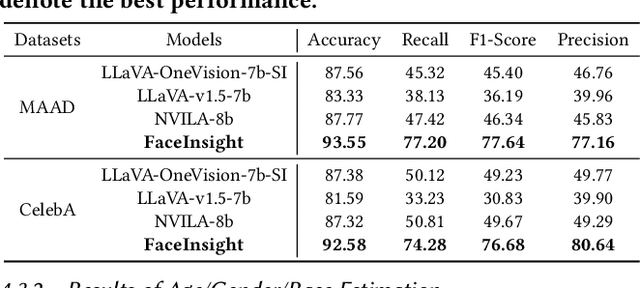
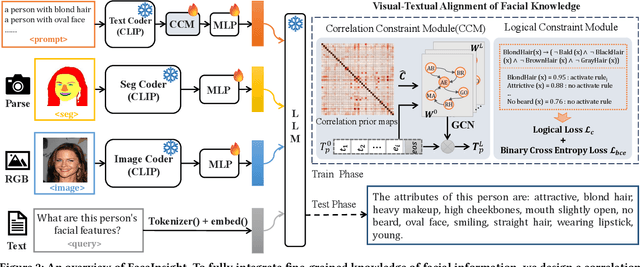
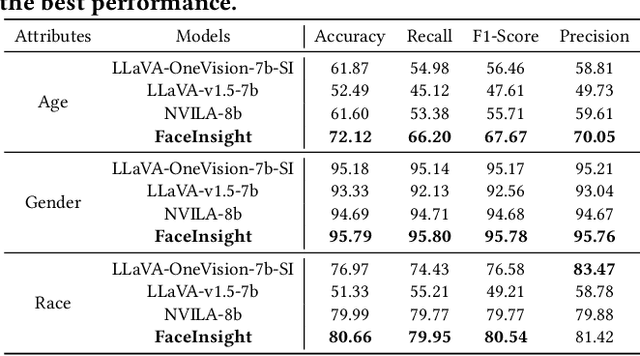
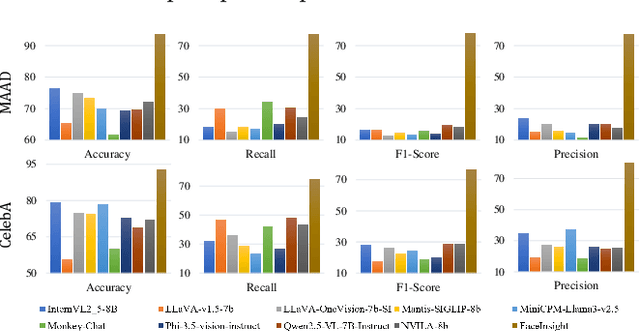
Recent advances in multimodal large language models (MLLMs) have demonstrated strong capabilities in understanding general visual content. However, these general-domain MLLMs perform poorly in face perception tasks, often producing inaccurate or misleading responses to face-specific queries. To address this gap, we propose FaceInsight, the versatile face perception MLLM that provides fine-grained facial information. Our approach introduces visual-textual alignment of facial knowledge to model both uncertain dependencies and deterministic relationships among facial information, mitigating the limitations of language-driven reasoning. Additionally, we incorporate face segmentation maps as an auxiliary perceptual modality, enriching the visual input with localized structural cues to enhance semantic understanding. Comprehensive experiments and analyses across three face perception tasks demonstrate that FaceInsight consistently outperforms nine compared MLLMs under both training-free and fine-tuned settings.
Generalized Semantic Contrastive Learning via Embedding Side Information for Few-Shot Object Detection
Apr 09, 2025The objective of few-shot object detection (FSOD) is to detect novel objects with few training samples. The core challenge of this task is how to construct a generalized feature space for novel categories with limited data on the basis of the base category space, which could adapt the learned detection model to unknown scenarios. However, limited by insufficient samples for novel categories, two issues still exist: (1) the features of the novel category are easily implicitly represented by the features of the base category, leading to inseparable classifier boundaries, (2) novel categories with fewer data are not enough to fully represent the distribution, where the model fine-tuning is prone to overfitting. To address these issues, we introduce the side information to alleviate the negative influences derived from the feature space and sample viewpoints and formulate a novel generalized feature representation learning method for FSOD. Specifically, we first utilize embedding side information to construct a knowledge matrix to quantify the semantic relationship between the base and novel categories. Then, to strengthen the discrimination between semantically similar categories, we further develop contextual semantic supervised contrastive learning which embeds side information. Furthermore, to prevent overfitting problems caused by sparse samples, a side-information guided region-aware masked module is introduced to augment the diversity of samples, which finds and abandons biased information that discriminates between similar categories via counterfactual explanation, and refines the discriminative representation space further. Extensive experiments using ResNet and ViT backbones on PASCAL VOC, MS COCO, LVIS V1, FSOD-1K, and FSVOD-500 benchmarks demonstrate that our model outperforms the previous state-of-the-art methods, significantly improving the ability of FSOD in most shots/splits.