 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Not to Learn: Prior-Aligned Training with Subset-based Attribution Constraints for Reliable Decision-Making
Jan 30, 2026Reliable models should not only predict correctly, but also justify decisions with acceptable evidence. Yet conventional supervised learning typically provides only class-level labels, allowing models to achieve high accuracy through shortcut correlations rather than the intended evidence. Human priors can help constrain such behavior, but aligning models to these priors remains challenging because learned representations often diverge from human perception. To address this challenge, we propose an attribution-based human prior alignment method. We encode human priors as input regions that the model is expected to rely on (e.g., bounding boxes), and leverage a highly faithful subset-selection-based attribution approach to expose the model's decision evidence during training. When the attribution region deviates substantially from the prior regions, we penalize reliance on off-prior evidence, encouraging the model to shift its attribution toward the intended regions. This is achieved through a training objective that imposes attribution constraints induced by the human prior. We validate our method on both image classification and click decision tasks in MLLM-based GUI agent models. Across conventional classification and autoregressive generation settings, human prior alignment consistently improves task accuracy while also enhancing the model's decision reasonability.
Did Models Sufficient Learn? Attribution-Guided Training via Subset-Selected Counterfactual Augmentation
Nov 15, 2025In current visual model training, models often rely on only limited sufficient causes for their predictions, which makes them sensitive to distribution shifts or the absence of key features. Attribution methods can accurately identify a model's critical regions. However, masking these areas to create counterfactuals often causes the model to misclassify the target, while humans can still easily recognize it. This divergence highlights that the model's learned dependencies may not be sufficiently causal. To address this issue, we propose Subset-Selected Counterfactual Augmentation (SS-CA), which integrates counterfactual explanations directly into the training process for targeted intervention. Building on the subset-selection-based LIMA attribution method, we develop Counterfactual LIMA to identify minimal spatial region sets whose removal can selectively alter model predictions. Leveraging these attributions, we introduce a data augmentation strategy that replaces the identified regions with natural background, and we train the model jointly on both augmented and original samples to mitigate incomplete causal learning. Extensive experiments across multiple ImageNet variants show that SS-CA improves generalization on in-distribution (ID) test data and achieves superior performance on out-of-distribution (OOD) benchmarks such as ImageNet-R and ImageNet-S. Under perturbations including noise, models trained with SS-CA also exhibit enhanced generalization, demonstrating that our approach effectively uses interpretability insights to correct model deficiencies and improve both performance and robustness.
Where MLLMs Attend and What They Rely On: Explaining Autoregressive Token Generation
Sep 26, 2025Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in aligning visual inputs with natural language outputs. Yet, the extent to which generated tokens depend on visual modalities remains poorly understood, limiting interpretability and reliability. In this work, we present EAGLE, a lightweight black-box framework for explaining autoregressive token generation in MLLMs. EAGLE attributes any selected tokens to compact perceptual regions while quantifying the relative influence of language priors and perceptual evidence. The framework introduces an objective function that unifies sufficiency (insight score) and indispensability (necessity score), optimized via greedy search over sparsified image regions for faithful and efficient attribution. Beyond spatial attribution, EAGLE performs modality-aware analysis that disentangles what tokens rely on, providing fine-grained interpretability of model decisions. Extensive experiments across open-source MLLMs show that EAGLE consistently outperforms existing methods in faithfulness, localization, and hallucination diagnosis, while requiring substantially less GPU memory. These results highlight its effectiveness and practicality for advancing the interpretability of MLLMs. The code is available at https://github.com/RuoyuChen10/EAGLE.
Explaining multimodal LLMs via intra-modal token interactions
Sep 26, 2025Multimodal Large Language Models (MLLMs) have achieved remarkable success across diverse vision-language tasks, yet their internal decision-making mechanisms remain insufficiently understood. Existing interpretability research has primarily focused on cross-modal attribution, identifying which image regions the model attends to during output generation. However, these approaches often overlook intra-modal dependencies. In the visual modality, attributing importance to isolated image patches ignores spatial context due to limited receptive fields, resulting in fragmented and noisy explanations. In the textual modality, reliance on preceding tokens introduces spurious activations. Failing to effectively mitigate these interference compromises attribution fidelity. To address these limitations, we propose enhancing interpretability by leveraging intra-modal interaction. For the visual branch, we introduce \textit{Multi-Scale Explanation Aggregation} (MSEA), which aggregates attributions over multi-scale inputs to dynamically adjust receptive fields, producing more holistic and spatially coherent visual explanations. For the textual branch, we propose \textit{Activation Ranking Correlation} (ARC), which measures the relevance of contextual tokens to the current token via alignment of their top-$k$ prediction rankings. ARC leverages this relevance to suppress spurious activations from irrelevant contexts while preserving semantically coherent ones. Extensive experiments across state-of-the-art MLLMs and benchmark datasets demonstrate that our approach consistently outperforms existing interpretability methods, yielding more faithful and fine-grained explanations of model behavior.
Less is More: Efficient Black-box Attribution via Minimal Interpretable Subset Selection
Apr 01, 2025To develop a trustworthy AI system, which aim to identify the input regions that most influence the models decisions. The primary task of existing attribution methods lies in efficiently and accurately identifying the relationships among input-prediction interactions. Particularly when the input data is discrete, such as images, analyzing the relationship between inputs and outputs poses a significant challenge due to the combinatorial explosion. In this paper, we propose a novel and efficient black-box attribution mechanism, LiMA (Less input is More faithful for Attribution), which reformulates the attribution of important regions as an optimization problem for submodular subset selection. First, to accurately assess interactions, we design a submodular function that quantifies subset importance and effectively captures their impact on decision outcomes. Then, efficiently ranking input sub-regions by their importance for attribution, we improve optimization efficiency through a novel bidirectional greedy search algorithm. LiMA identifies both the most and least important samples while ensuring an optimal attribution boundary that minimizes errors. Extensive experiments on eight foundation models demonstrate that our method provides faithful interpretations with fewer regions and exhibits strong generalization, shows an average improvement of 36.3% in Insertion and 39.6% in Deletion. Our method also outperforms the naive greedy search in attribution efficiency, being 1.6 times faster. Furthermore, when explaining the reasons behind model prediction errors, the average highest confidence achieved by our method is, on average, 86.1% higher than that of state-of-the-art attribution algorithms. The code is available at https://github.com/RuoyuChen10/LIMA.
Interpreting Object-level Foundation Models via Visual Precision Search
Nov 25, 2024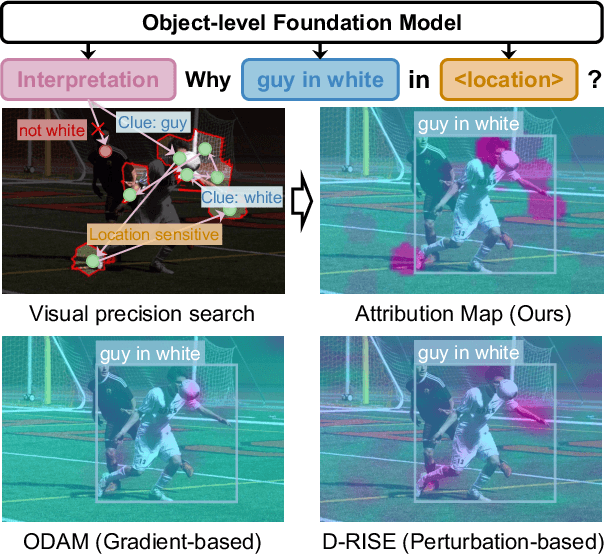
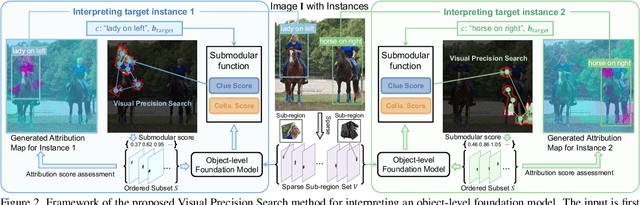
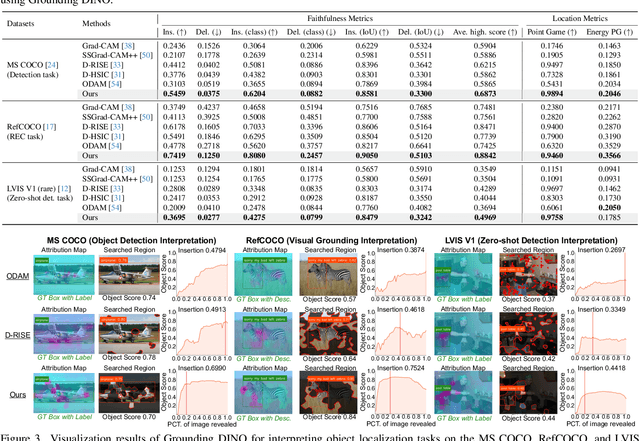
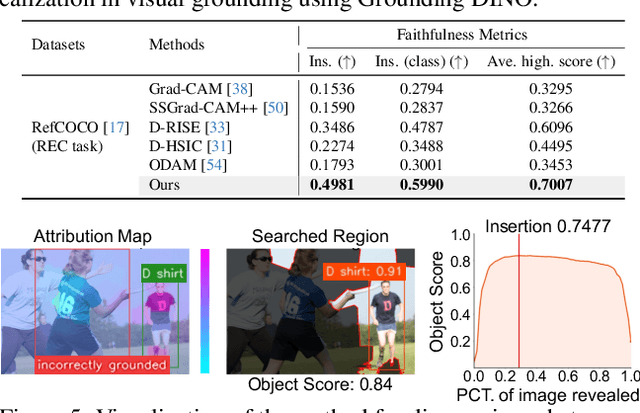
Advances in multimodal pre-training have propelled object-level foundation models, such as Grounding DINO and Florence-2, in tasks like visual grounding and object detection. However, interpreting these models\' decisions has grown increasingly challenging. Existing interpretable attribution methods for object-level task interpretation have notable limitations: (1) gradient-based methods lack precise localization due to visual-textual fusion in foundation models, and (2) perturbation-based methods produce noisy saliency maps, limiting fine-grained interpretability. To address these, we propose a Visual Precision Search method that generates accurate attribution maps with fewer regions. Our method bypasses internal model parameters to overcome attribution issues from multimodal fusion, dividing inputs into sparse sub-regions and using consistency and collaboration scores to accurately identify critical decision-making regions. We also conducted a theoretical analysis of the boundary guarantees and scope of applicability of our method. Experiments on RefCOCO, MS COCO, and LVIS show our approach enhances object-level task interpretability over SOTA for Grounding DINO and Florence-2 across various evaluation metrics, with faithfulness gains of 23.7\%, 31.6\%, and 20.1\% on MS COCO, LVIS, and RefCOCO for Grounding DINO, and 102.9\% and 66.9\% on MS COCO and RefCOCO for Florence-2. Additionally, our method can interpret failures in visual grounding and object detection tasks, surpassing existing methods across multiple evaluation metrics. The code will be released at \url{https://github.com/RuoyuChen10/VPS}.
World Models: The Safety Perspective
Nov 12, 2024


With the proliferation of the Large Language Model (LLM), the concept of World Models (WM) has recently attracted a great deal of attention in the AI research community, especially in the context of AI agents. It is arguably evolving into an essential foundation for building AI agent systems. A WM is intended to help the agent predict the future evolution of environmental states or help the agent fill in missing information so that it can plan its actions and behave safely. The safety property of WM plays a key role in their effective use in critical applications. In this work, we review and analyze the impacts of the current state-of-the-art in WM technology from the point of view of trustworthiness and safety based on a comprehensive survey and the fields of application envisaged. We provide an in-depth analysis of state-of-the-art WMs and derive technical research challenges and their impact in order to call on the research community to collaborate on improving the safety and trustworthiness of WM.
NeFF-BioNet: Crop Biomass Prediction from Point Cloud to Drone Imagery
Oct 30, 2024Crop biomass offers crucial insights into plant health and yield, making it essential for crop science, farming systems, and agricultural research. However, current measurement methods, which are labor-intensive, destructive, and imprecise, hinder large-scale quantification of this trait. To address this limitation, we present a biomass prediction network (BioNet), designed for adaptation across different data modalities, including point clouds and drone imagery. Our BioNet, utilizing a sparse 3D convolutional neural network (CNN) and a transformer-based prediction module, processes point clouds and other 3D data representations to predict biomass. To further extend BioNet for drone imagery, we integrate a neural feature field (NeFF) module, enabling 3D structure reconstruction and the transformation of 2D semantic features from vision foundation models into the corresponding 3D surfaces. For the point cloud modality, BioNet demonstrates superior performance on two public datasets, with an approximate 6.1% relative improvement (RI) over the state-of-the-art. In the RGB image modality, the combination of BioNet and NeFF achieves a 7.9% RI. Additionally, the NeFF-based approach utilizes inexpensive, portable drone-mounted cameras, providing a scalable solution for large field applications.
MMCBE: Multi-modality Dataset for Crop Biomass Estimation and Beyond
Apr 17, 2024Crop biomass, a critical indicator of plant growth, health, and productivity, is invaluable for crop breeding programs and agronomic research. However, the accurate and scalable quantification of crop biomass remains inaccessible due to limitations in existing measurement methods. One of the obstacles impeding the advancement of current crop biomass prediction methodologies is the scarcity of publicly available datasets. Addressing this gap, we introduce a new dataset in this domain, i.e. Multi-modality dataset for crop biomass estimation (MMCBE). Comprising 216 sets of multi-view drone images, coupled with LiDAR point clouds, and hand-labelled ground truth, MMCBE represents the first multi-modality one in the field. This dataset aims to establish benchmark methods for crop biomass quantification and foster the development of vision-based approaches. We have rigorously evaluated state-of-the-art crop biomass estimation methods using MMCBE and ventured into additional potential applications, such as 3D crop reconstruction from drone imagery and novel-view rendering. With this publication, we are making our comprehensive dataset available to the broader community.