 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Object-level Foundation Models via Visual Precision Search
Nov 25, 2024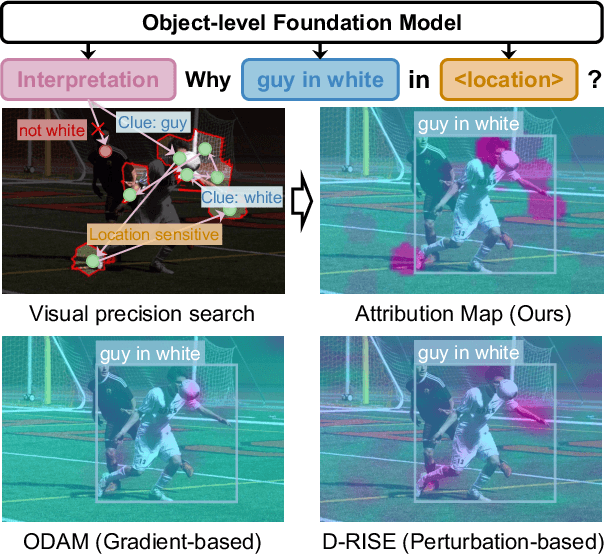
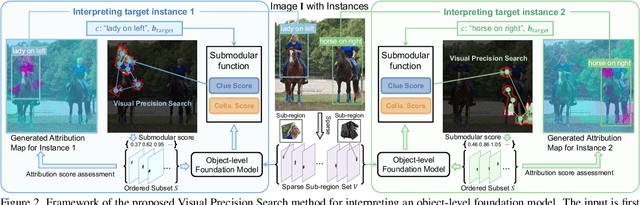
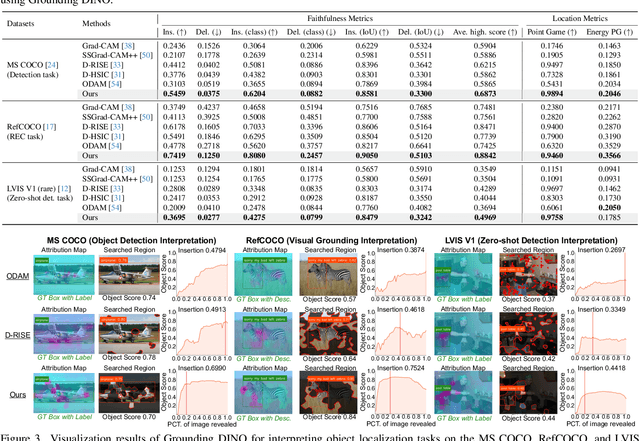
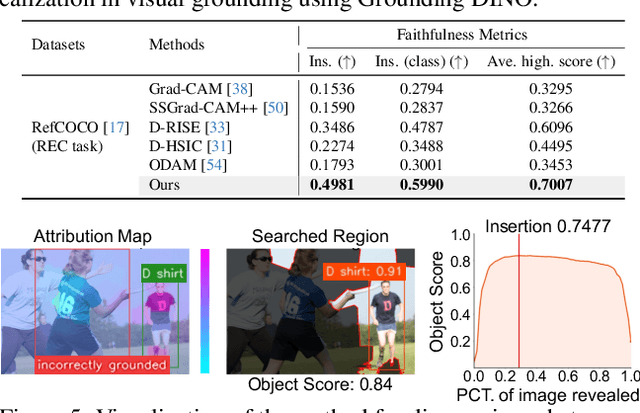
Advances in multimodal pre-training have propelled object-level foundation models, such as Grounding DINO and Florence-2, in tasks like visual grounding and object detection. However, interpreting these models\' decisions has grown increasingly challenging. Existing interpretable attribution methods for object-level task interpretation have notable limitations: (1) gradient-based methods lack precise localization due to visual-textual fusion in foundation models, and (2) perturbation-based methods produce noisy saliency maps, limiting fine-grained interpretability. To address these, we propose a Visual Precision Search method that generates accurate attribution maps with fewer regions. Our method bypasses internal model parameters to overcome attribution issues from multimodal fusion, dividing inputs into sparse sub-regions and using consistency and collaboration scores to accurately identify critical decision-making regions. We also conducted a theoretical analysis of the boundary guarantees and scope of applicability of our method. Experiments on RefCOCO, MS COCO, and LVIS show our approach enhances object-level task interpretability over SOTA for Grounding DINO and Florence-2 across various evaluation metrics, with faithfulness gains of 23.7\%, 31.6\%, and 20.1\% on MS COCO, LVIS, and RefCOCO for Grounding DINO, and 102.9\% and 66.9\% on MS COCO and RefCOCO for Florence-2. Additionally, our method can interpret failures in visual grounding and object detection tasks, surpassing existing methods across multiple evaluation metrics. The code will be released at \url{https://github.com/RuoyuChen10/VPS}.
Skeleton-Parted Graph Scattering Networks for 3D Human Motion Prediction
Jul 31, 2022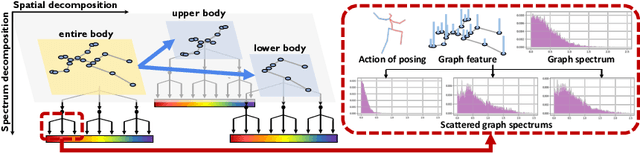
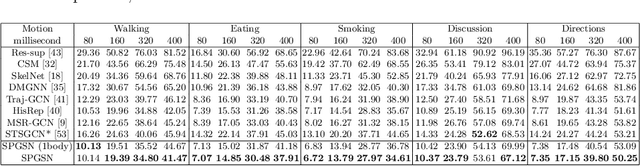
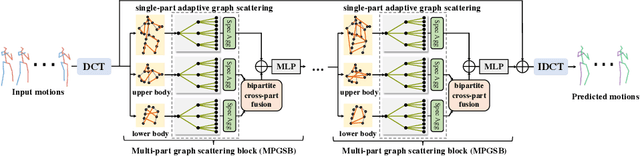

Graph convolutional network based methods that model the body-joints' relations, have recently shown great promise in 3D skeleton-based human motion prediction. However, these methods have two critical issues: first, deep graph convolutions filter features within only limited graph spectrums, losing sufficient information in the full band; second, using a single graph to model the whole body underestimates the diverse patterns on various body-parts. To address the first issue, we propose adaptive graph scattering, which leverages multiple trainable band-pass graph filters to decompose pose features into richer graph spectrum bands. To address the second issue, body-parts are modeled separately to learn diverse dynamics, which enables finer feature extraction along the spatial dimensions. Integrating the above two designs, we propose a novel skeleton-parted graph scattering network (SPGSN). The cores of the model are cascaded multi-part graph scattering blocks (MPGSBs), building adaptive graph scattering on diverse body-parts, as well as fusing the decomposed features based on the inferred spectrum importance and body-part interactions. Extensive experiments have shown that SPGSN outperforms state-of-the-art methods by remarkable margins of 13.8%, 9.3% and 2.7% in terms of 3D mean per joint position error (MPJPE) on Human3.6M, CMU Mocap and 3DPW datasets, respectively.
GroupNet: Multiscale Hypergraph Neural Networks for Trajectory Prediction with Relational Reasoning
Apr 20, 2022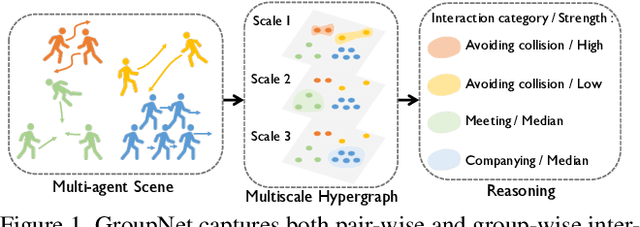

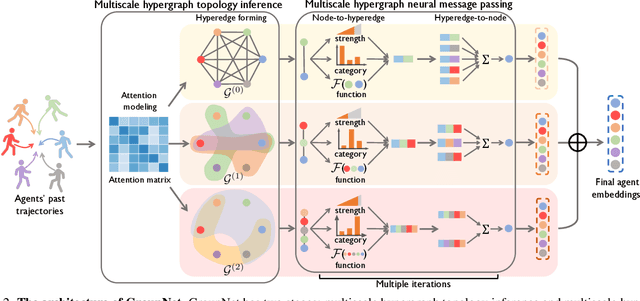
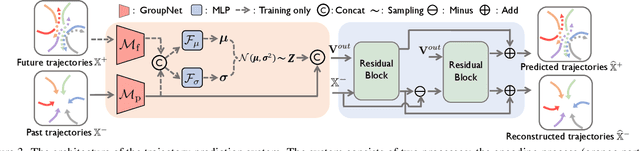
Demystifying the interactions among multiple agents from their past trajectories is fundamental to precise and interpretable trajectory prediction. However, previous works only consider pair-wise interactions with limited relational reasoning. To promote more comprehensive interaction modeling for relational reasoning, we propose GroupNet, a multiscale hypergraph neural network, which is novel in terms of both interaction capturing and representation learning. From the aspect of interaction capturing, we propose a trainable multiscale hypergraph to capture both pair-wise and group-wise interactions at multiple group sizes. From the aspect of interaction representation learning, we propose a three-element format that can be learnt end-to-end and explicitly reason some relational factors including the interaction strength and category. We apply GroupNet into both CVAE-based prediction system and previous state-of-the-art prediction systems for predicting socially plausible trajectories with relational reasoning. To validate the ability of relational reasoning, we experiment with synthetic physics simulations to reflect the ability to capture group behaviors, reason interaction strength and interaction category. To validate the effectiveness of prediction, we conduct extensive experiments on three real-world trajectory prediction datasets, including NBA, SDD and ETH-UCY; and we show that with GroupNet, the CVAE-based prediction system outperforms state-of-the-art methods. We also show that adding GroupNet will further improve the performance of previous state-of-the-art prediction systems.
Multiscale Spatio-Temporal Graph Neural Networks for 3D Skeleton-Based Motion Prediction
Aug 25, 2021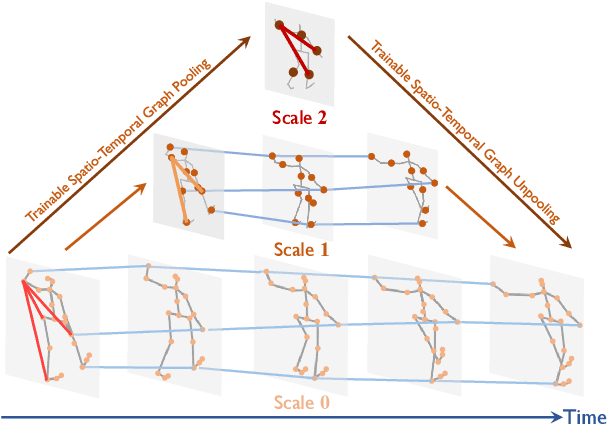
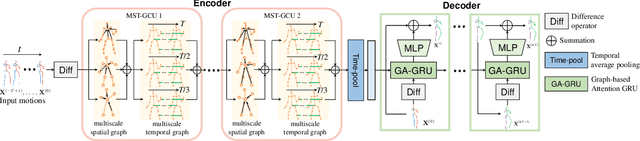
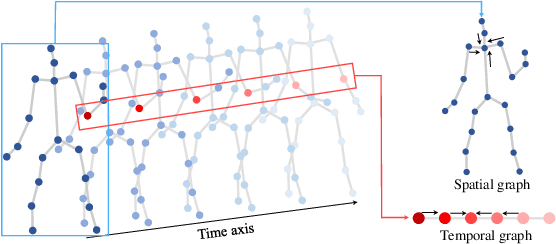
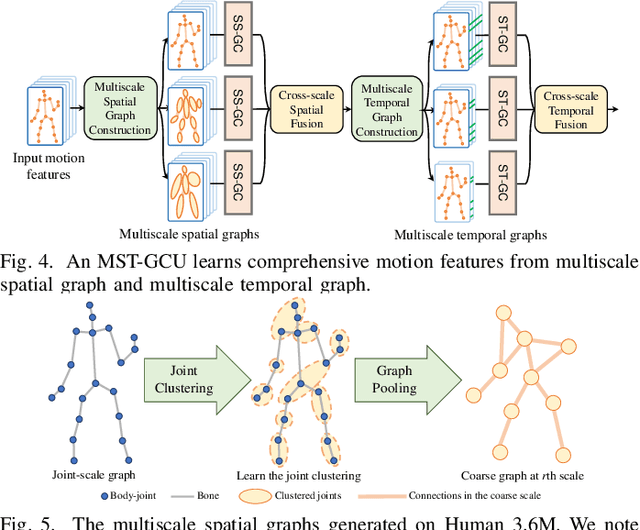
We propose a multiscale spatio-temporal graph neural network (MST-GNN) to predict the future 3D skeleton-based human poses in an action-category-agnostic manner. The core of MST-GNN is a multiscale spatio-temporal graph that explicitly models the relations in motions at various spatial and temporal scales. Different from many previous hierarchical structures, our multiscale spatio-temporal graph is built in a data-adaptive fashion, which captures nonphysical, yet motion-based relations. The key module of MST-GNN is a multiscale spatio-temporal graph computational unit (MST-GCU) based on the trainable graph structure. MST-GCU embeds underlying features at individual scales and then fuses features across scales to obtain a comprehensive representation. The overall architecture of MST-GNN follows an encoder-decoder framework, where the encoder consists of a sequence of MST-GCUs to learn the spatial and temporal features of motions, and the decoder uses a graph-based attention gate recurrent unit (GA-GRU) to generate future poses. Extensive experiments are conducted to show that the proposed MST-GNN outperforms state-of-the-art methods in both short and long-term motion prediction on the datasets of Human 3.6M, CMU Mocap and 3DPW, where MST-GNN outperforms previous works by 5.33% and 3.67% of mean angle errors in average for short-term and long-term prediction on Human 3.6M, and by 11.84% and 4.71% of mean angle errors for short-term and long-term prediction on CMU Mocap, and by 1.13% of mean angle errors on 3DPW in average, respectively. We further investigate the learned multiscale graphs for interpretability.
Online Multi-Agent Forecasting with Interpretable Collaborative Graph Neural Network
Jul 02, 2021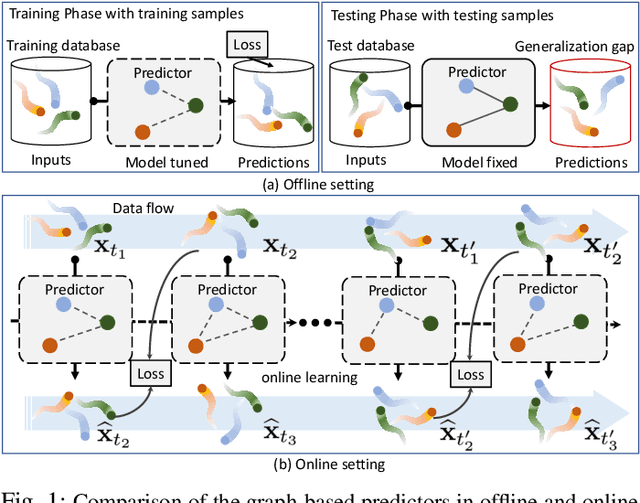
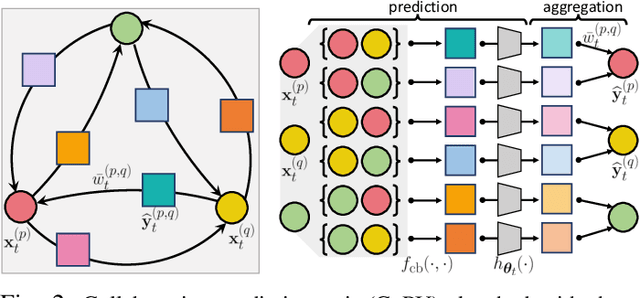

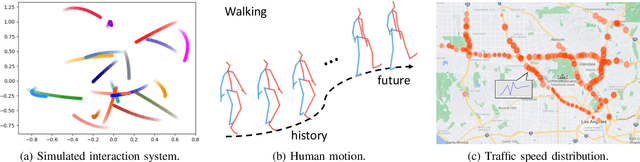
This paper considers predicting future statuses of multiple agents in an online fashion by exploiting dynamic interactions in the system. We propose a novel collaborative prediction unit (CoPU), which aggregates the predictions from multiple collaborative predictors according to a collaborative graph. Each collaborative predictor is trained to predict the status of an agent by considering the impact of another agent. The edge weights of the collaborative graph reflect the importance of each predictor. The collaborative graph is adjusted online by multiplicative update, which can be motivated by minimizing an explicit objective. With this objective, we also conduct regret analysis to indicate that, along with training, our CoPU achieves similar performance with the best individual collaborative predictor in hindsight. This theoretical interpretability distinguishes our method from many other graph networks. To progressively refine predictions, multiple CoPUs are stacked to form a collaborative graph neural network. Extensive experiments are conducted on three tasks: online simulated trajectory prediction, online human motion prediction and online traffic speed prediction, and our methods outperform state-of-the-art works on the three tasks by 28.6%, 17.4% and 21.0% on average, respectively.
Incremental Embedding Learning via Zero-Shot Translation
Dec 31, 2020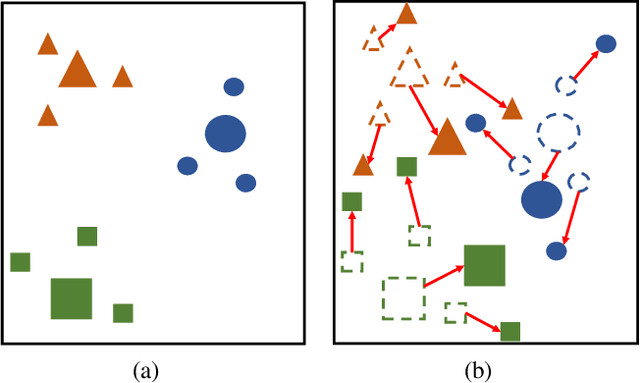
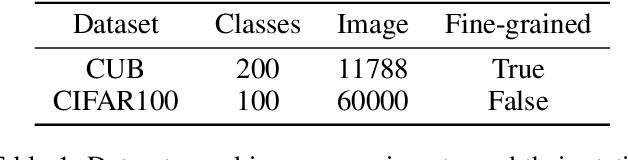

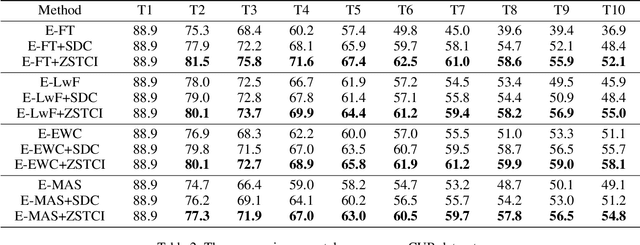
Modern deep learning methods have achieved great success in machine learning and computer vision fields by learning a set of pre-defined datasets. Howerver, these methods perform unsatisfactorily when applied into real-world situations. The reason of this phenomenon is that learning new tasks leads the trained model quickly forget the knowledge of old tasks, which is referred to as catastrophic forgetting. Current state-of-the-art incremental learning methods tackle catastrophic forgetting problem in traditional classification networks and ignore the problem existing in embedding networks, which are the basic networks for image retrieval, face recognition, zero-shot learning, etc. Different from traditional incremental classification networks, the semantic gap between the embedding spaces of two adjacent tasks is the main challenge for embedding networks under incremental learning setting. Thus, we propose a novel class-incremental method for embedding network, named as zero-shot translation class-incremental method (ZSTCI), which leverages zero-shot translation to estimate and compensate the semantic gap without any exemplars. Then, we try to learn a unified representation for two adjacent tasks in sequential learning process, which captures the relationships of previous classes and current classes precisely. In addition, ZSTCI can easily be combined with existing regularization-based incremental learning methods to further improve performance of embedding networks. We conduct extensive experiments on CUB-200-2011 and CIFAR100, and the experiment results prove the effectiveness of our method. The code of our method has been released.
Invariant Teacher and Equivariant Student for Unsupervised 3D Human Pose Estimation
Dec 17, 2020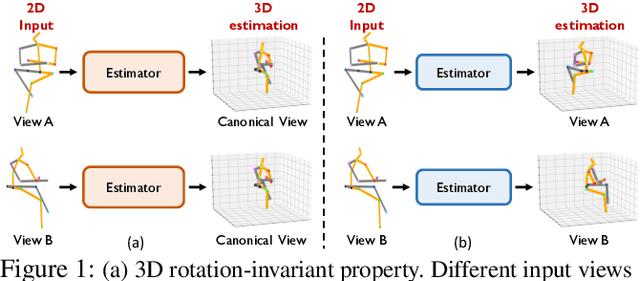
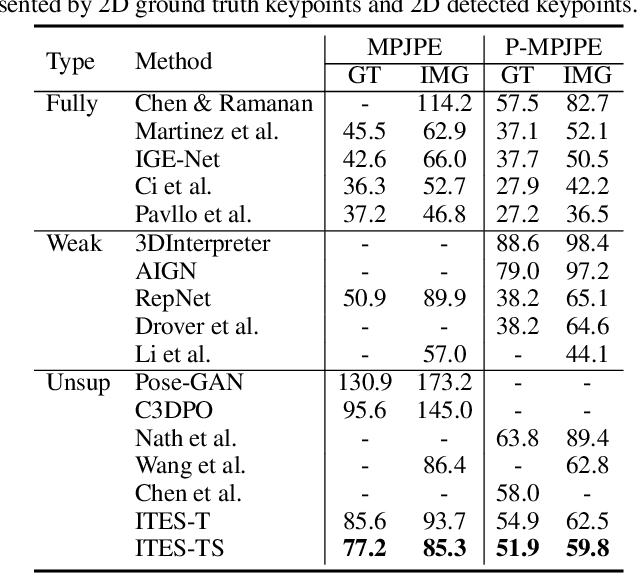
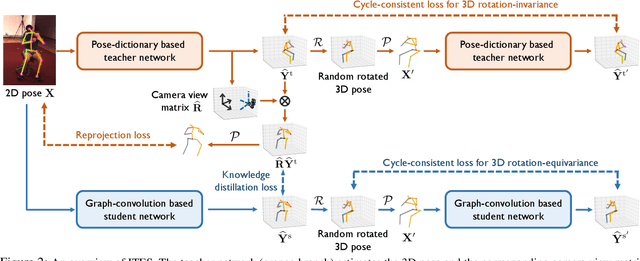
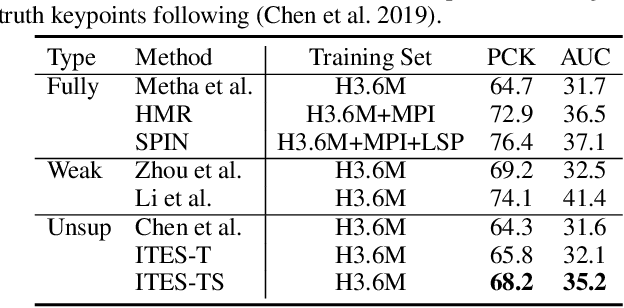
We propose a novel method based on teacher-student learning framework for 3D human pose estimation without any 3D annotation or side information. To solve this unsupervised-learning problem, the teacher network adopts pose-dictionary-based modeling for regularization to estimate a physically plausible 3D pose. To handle the decomposition ambiguity in the teacher network, we propose a cycle-consistent architecture promoting a 3D rotation-invariant property to train the teacher network. To further improve the estimation accuracy, the student network adopts a novel graph convolution network for flexibility to directly estimate the 3D coordinates. Another cycle-consistent architecture promoting 3D rotation-equivariant property is adopted to exploit geometry consistency, together with knowledge distillation from the teacher network to improve the pose estimation performance. We conduct extensive experiments on Human3.6M and MPI-INF-3DHP. Our method reduces the 3D joint prediction error by 11.4% compared to state-of-the-art unsupervised methods and also outperforms many weakly-supervised methods that use side information on Human3.6M. Code will be available at https://github.com/sjtuxcx/ITES.
Sampling and Recovery of Graph Signals based on Graph Neural Networks
Nov 03, 2020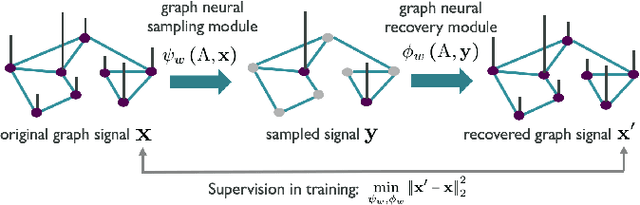
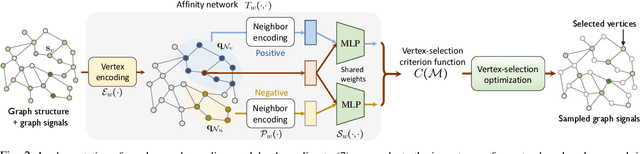
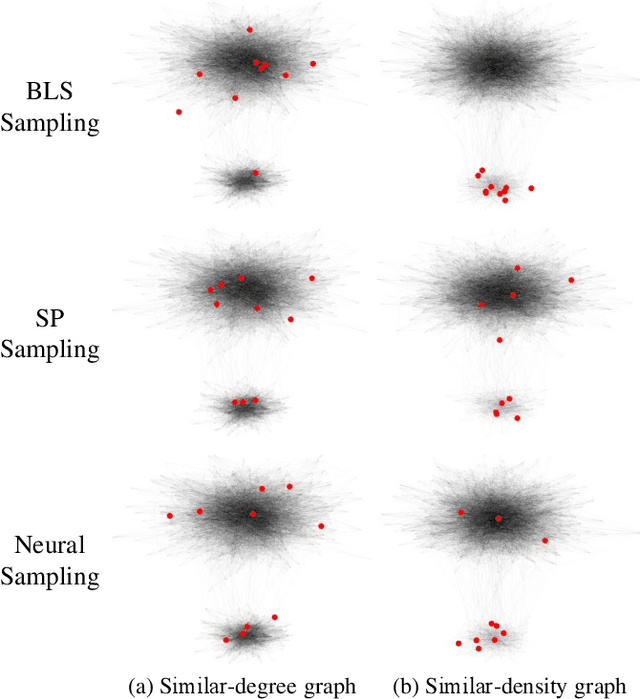
We propose interpretable graph neural networks for sampling and recovery of graph signals, respectively. To take informative measurements, we propose a new graph neural sampling module, which aims to select those vertices that maximally express their corresponding neighborhoods. Such expressiveness can be quantified by the mutual information between vertices' features and neighborhoods' features, which are estimated via a graph neural network. To reconstruct an original graph signal from the sampled measurements, we propose a graph neural recovery module based on the algorithm-unrolling technique. Compared to previous analytical sampling and recovery, the proposed methods are able to flexibly learn a variety of graph signal models from data by leveraging the learning ability of neural networks; compared to previous neural-network-based sampling and recovery, the proposed methods are designed through exploiting specific graph properties and provide interpretability. We further design a new multiscale graph neural network, which is a trainable multiscale graph filter bank and can handle various graph-related learning tasks. The multiscale network leverages the proposed graph neural sampling and recovery modules to achieve multiscale representations of a graph. In the experiments, we illustrate the effects of the proposed graph neural sampling and recovery modules and find that the modules can flexibly adapt to various graph structures and graph signals. In the task of active-sampling-based semi-supervised learning, the graph neural sampling module improves the classification accuracy over 10% in Cora dataset. We further validate the proposed multiscale graph neural network on several standard datasets for both vertex and graph classification. The results show that our method consistently improves the classification accuracies.
Graph Cross Networks with Vertex Infomax Pooling
Oct 17, 2020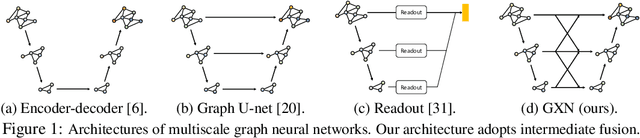
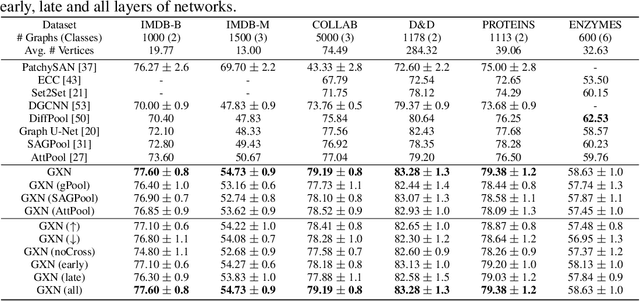

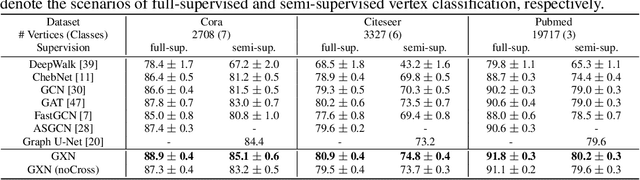
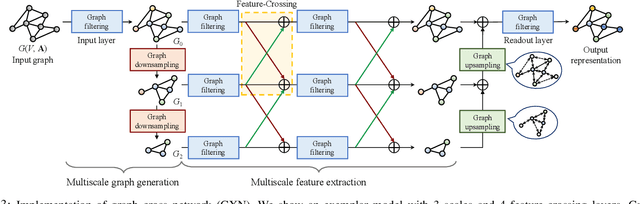
We propose a novel graph cross network (GXN) to achieve comprehensive feature learning from multiple scales of a graph. Based on trainable hierarchical representations of a graph, GXN enables the interchange of intermediate features across scales to promote information flow. Two key ingredients of GXN include a novel vertex infomax pooling (VIPool), which creates multiscale graphs in a trainable manner, and a novel feature-crossing layer, enabling feature interchange across scales. The proposed VIPool selects the most informative subset of vertices based on the neural estimation of mutual information between vertex features and neighborhood features. The intuition behind is that a vertex is informative when it can maximally reflect its neighboring information. The proposed feature-crossing layer fuses intermediate features between two scales for mutual enhancement by improving information flow and enriching multiscale features at hidden layers. The cross shape of the feature-crossing layer distinguishes GXN from many other multiscale architectures. Experimental results show that the proposed GXN improves the classification accuracy by 2.12% and 1.15% on average for graph classification and vertex classification, respectively. Based on the same network, the proposed VIPool consistently outperforms other graph-pooling methods.
Decoupled Variational Embedding for Signed Directed Networks
Aug 28, 2020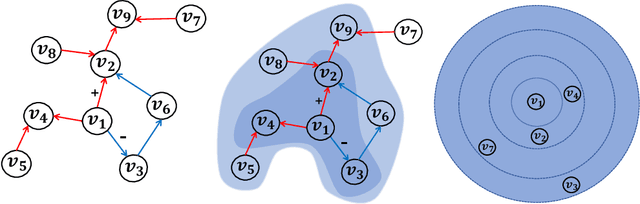

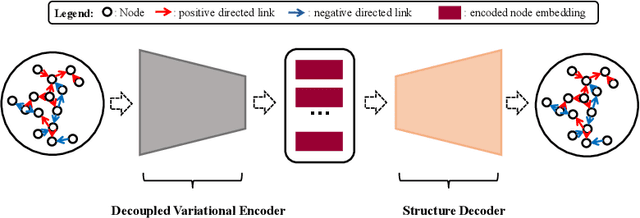
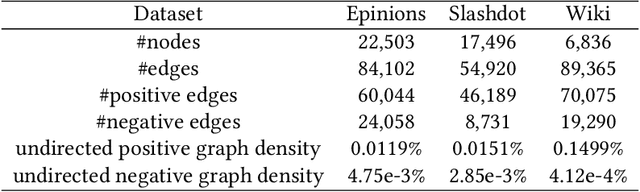
Node representation learning for signed directed networks has received considerable attention in many real-world applications such as link sign prediction, node classification and node recommendation. The challenge lies in how to adequately encode the complex topological information of the networks. Recent studies mainly focus on preserving the first-order network topology which indicates the closeness relationships of nodes. However, these methods generally fail to capture the high-order topology which indicates the local structures of nodes and serves as an essential characteristic of the network topology. In addition, for the first-order topology, the additional value of non-existent links is largely ignored. In this paper, we propose to learn more representative node embeddings by simultaneously capturing the first-order and high-order topology in signed directed networks. In particular, we reformulate the representation learning problem on signed directed networks from a variational auto-encoding perspective and further develop a decoupled variational embedding (DVE) method. DVE leverages a specially designed auto-encoder structure to capture both the first-order and high-order topology of signed directed networks, and thus learns more representative node embedding. Extensive experiments are conducted on three widely used real-world datasets. Comprehensive results on both link sign prediction and node recommendation task demonstrate the effectiveness of DVE. Qualitative results and analysis are also given to provide a better understanding of DVE.