 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumber-Adaptive Prototype Learning for 3D Point Cloud Semantic Segmentation
Oct 18, 2022


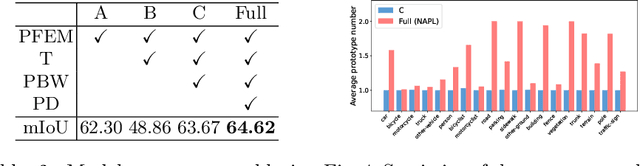
3D point cloud semantic segmentation is one of the fundamental tasks for 3D scene understanding and has been widely used in the metaverse applications. Many recent 3D semantic segmentation methods learn a single prototype (classifier weights) for each semantic class, and classify 3D points according to their nearest prototype. However, learning only one prototype for each class limits the model's ability to describe the high variance patterns within a class. Instead of learning a single prototype for each class, in this paper, we propose to use an adaptive number of prototypes to dynamically describe the different point patterns within a semantic class. With the powerful capability of vision transformer, we design a Number-Adaptive Prototype Learning (NAPL) model for point cloud semantic segmentation. To train our NAPL model, we propose a simple yet effective prototype dropout training strategy, which enables our model to adaptively produce prototypes for each class. The experimental results on SemanticKITTI dataset demonstrate that our method achieves 2.3% mIoU improvement over the baseline model based on the point-wise classification paradigm.
A 3D Mesh-based Lifting-and-Projection Network for Human Pose Transfer
Sep 24, 2021

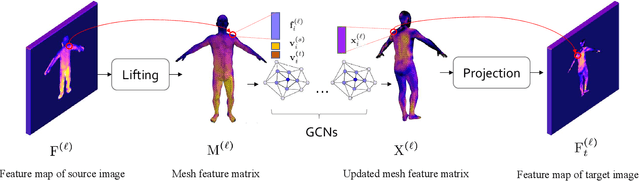

Human pose transfer has typically been modeled as a 2D image-to-image translation problem. This formulation ignores the human body shape prior in 3D space and inevitably causes implausible artifacts, especially when facing occlusion. To address this issue, we propose a lifting-and-projection framework to perform pose transfer in the 3D mesh space. The core of our framework is a foreground generation module, that consists of two novel networks: a lifting-and-projection network (LPNet) and an appearance detail compensating network (ADCNet). To leverage the human body shape prior, LPNet exploits the topological information of the body mesh to learn an expressive visual representation for the target person in the 3D mesh space. To preserve texture details, ADCNet is further introduced to enhance the feature produced by LPNet with the source foreground image. Such design of the foreground generation module enables the model to better handle difficult cases such as those with occlusions. Experiments on the iPER and Fashion datasets empirically demonstrate that the proposed lifting-and-projection framework is effective and outperforms the existing image-to-image-based and mesh-based methods on human pose transfer task in both self-transfer and cross-transfer settings.
Multiscale Spatio-Temporal Graph Neural Networks for 3D Skeleton-Based Motion Prediction
Aug 25, 2021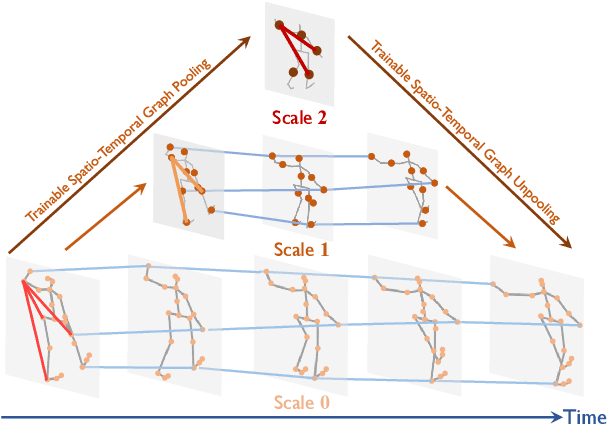
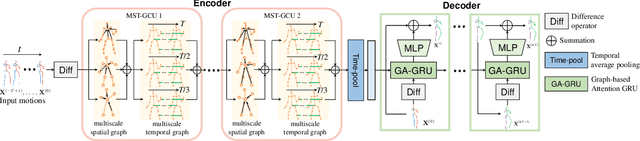
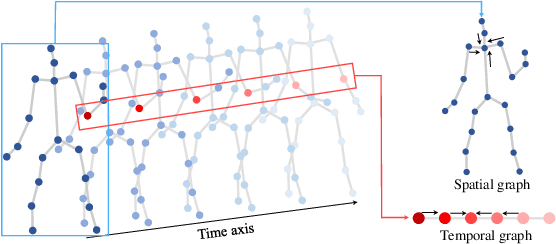
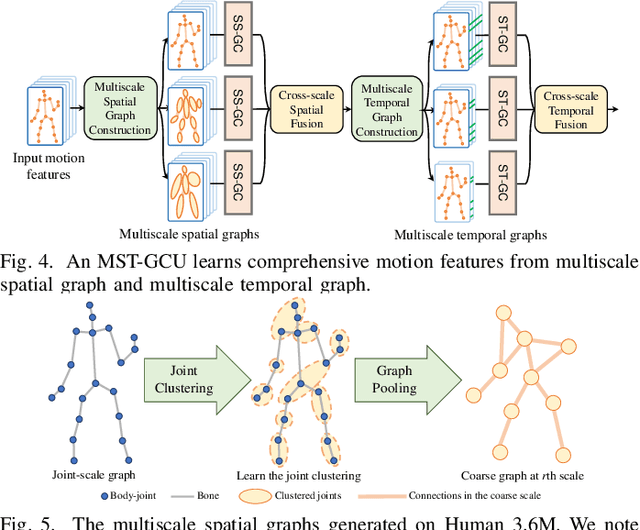
We propose a multiscale spatio-temporal graph neural network (MST-GNN) to predict the future 3D skeleton-based human poses in an action-category-agnostic manner. The core of MST-GNN is a multiscale spatio-temporal graph that explicitly models the relations in motions at various spatial and temporal scales. Different from many previous hierarchical structures, our multiscale spatio-temporal graph is built in a data-adaptive fashion, which captures nonphysical, yet motion-based relations. The key module of MST-GNN is a multiscale spatio-temporal graph computational unit (MST-GCU) based on the trainable graph structure. MST-GCU embeds underlying features at individual scales and then fuses features across scales to obtain a comprehensive representation. The overall architecture of MST-GNN follows an encoder-decoder framework, where the encoder consists of a sequence of MST-GCUs to learn the spatial and temporal features of motions, and the decoder uses a graph-based attention gate recurrent unit (GA-GRU) to generate future poses. Extensive experiments are conducted to show that the proposed MST-GNN outperforms state-of-the-art methods in both short and long-term motion prediction on the datasets of Human 3.6M, CMU Mocap and 3DPW, where MST-GNN outperforms previous works by 5.33% and 3.67% of mean angle errors in average for short-term and long-term prediction on Human 3.6M, and by 11.84% and 4.71% of mean angle errors for short-term and long-term prediction on CMU Mocap, and by 1.13% of mean angle errors on 3DPW in average, respectively. We further investigate the learned multiscale graphs for interpretability.
Dynamic Multiscale Graph Neural Networks for 3D Skeleton-Based Human Motion Prediction
Mar 17, 2020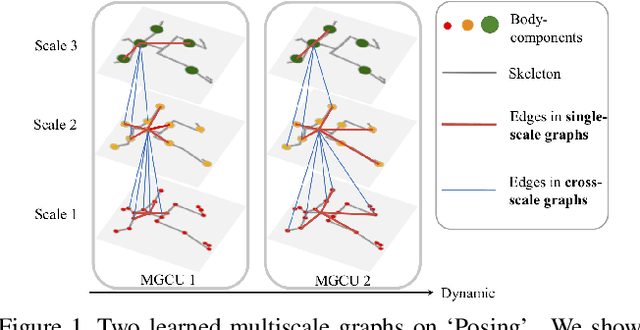

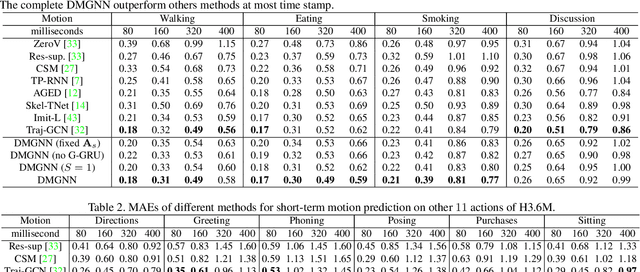
We propose novel dynamic multiscale graph neural networks (DMGNN) to predict 3D skeleton-based human motions. The core idea of DMGNN is to use a multiscale graph to comprehensively model the internal relations of a human body for motion feature learning. This multiscale graph is adaptive during training and dynamic across network layers. Based on this graph, we propose a multiscale graph computational unit (MGCU) to extract features at individual scales and fuse features across scales. The entire model is action-category-agnostic and follows an encoder-decoder framework. The encoder consists of a sequence of MGCUs to learn motion features. The decoder uses a proposed graph-based gate recurrent unit to generate future poses. Extensive experiments show that the proposed DMGNN outperforms state-of-the-art methods in both short and long-term predictions on the datasets of Human 3.6M and CMU Mocap. We further investigate the learned multiscale graphs for the interpretability. The codes could be downloaded from https://github.com/limaosen0/DMGNN.