 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 3D Mesh-based Lifting-and-Projection Network for Human Pose Transfer
Paper and Code
Sep 24, 2021

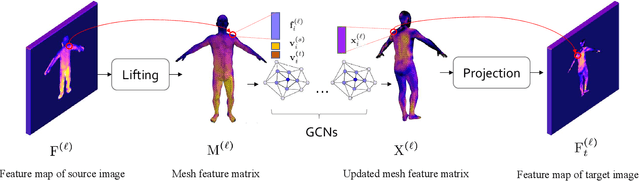

Human pose transfer has typically been modeled as a 2D image-to-image translation problem. This formulation ignores the human body shape prior in 3D space and inevitably causes implausible artifacts, especially when facing occlusion. To address this issue, we propose a lifting-and-projection framework to perform pose transfer in the 3D mesh space. The core of our framework is a foreground generation module, that consists of two novel networks: a lifting-and-projection network (LPNet) and an appearance detail compensating network (ADCNet). To leverage the human body shape prior, LPNet exploits the topological information of the body mesh to learn an expressive visual representation for the target person in the 3D mesh space. To preserve texture details, ADCNet is further introduced to enhance the feature produced by LPNet with the source foreground image. Such design of the foreground generation module enables the model to better handle difficult cases such as those with occlusions. Experiments on the iPER and Fashion datasets empirically demonstrate that the proposed lifting-and-projection framework is effective and outperforms the existing image-to-image-based and mesh-based methods on human pose transfer task in both self-transfer and cross-transfer settings.