 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNumber-Adaptive Prototype Learning for 3D Point Cloud Semantic Segmentation
Paper and Code
Oct 18, 2022


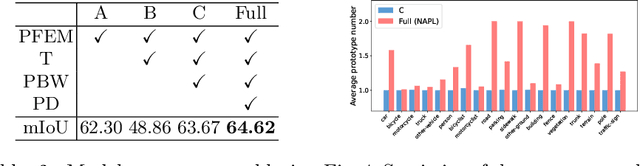
3D point cloud semantic segmentation is one of the fundamental tasks for 3D scene understanding and has been widely used in the metaverse applications. Many recent 3D semantic segmentation methods learn a single prototype (classifier weights) for each semantic class, and classify 3D points according to their nearest prototype. However, learning only one prototype for each class limits the model's ability to describe the high variance patterns within a class. Instead of learning a single prototype for each class, in this paper, we propose to use an adaptive number of prototypes to dynamically describe the different point patterns within a semantic class. With the powerful capability of vision transformer, we design a Number-Adaptive Prototype Learning (NAPL) model for point cloud semantic segmentation. To train our NAPL model, we propose a simple yet effective prototype dropout training strategy, which enables our model to adaptively produce prototypes for each class. The experimental results on SemanticKITTI dataset demonstrate that our method achieves 2.3% mIoU improvement over the baseline model based on the point-wise classification paradigm.