 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoSelf: From Memory to Personalized Egocentric Assistant
Apr 22, 2026Egocentric assistants often rely on first-person view data to capture user behavior and context for personalized services. Since different users exhibit distinct habits, preferences, and routines, such personalization is essential for truly effective assistance. However, effectively integrating long-term user data for personalization remains a key challenge. To address this, we introduce EgoSelf, a system that includes a graph-based interaction memory constructed from past observations and a dedicated learning task for personalization. The memory captures temporal and semantic relationships among interaction events and entities, from which user-specific profiles are derived. The personalized learning task is formulated as a prediction problem where the model predicts possible future interactions from individual user's historical behavior recorded in the graph. Extensive experiments demonstrate the effectiveness of EgoSelf as a personalized egocentric assistant. Code is available at https://abie-e.github.io/EgoSelf/.
MVHOI: Bridge Multi-view Condition to Complex Human-Object Interaction Video Reenactment via 3D Foundation Model
Mar 16, 2026Human-Object Interaction (HOI) video reenactment with realistic motion remains a frontier in expressive digital human creation. Existing approaches primarily handle simple image-plane motion (e.g., in-plane translations), struggling with complex non-planar manipulations like out-of-plane reorientation. In this paper, we propose MVHOI, a two-stage HOI video reenactment framework that bridges multi-view reference conditions and video foundation models via a 3D Foundation Model (3DFM). The 3DFM first produces view-consistent object priors conditioned on implicit motion dynamics across novel viewpoints. A controllable video generation model then synthesizes high-fidelity object texture by incorporating multi-view reference images, ensuring appearance consistency via a reasonable retrieval mechanism. By enabling these two stages to mutually reinforce one another during the inference phase, our framework shows superior performance in generating long-duration HOI videos with intricate object manipulations. Extensive experiments show substantial improvements over prior approaches, especially for HOI with complex 3D object manipulations.
ReMAP-DP: Reprojected Multi-view Aligned PointMaps for Diffusion Policy
Mar 16, 2026Generalist robot policies built upon 2D visual representations excel at semantic reasoning but inherently lack the explicit 3D spatial awareness required for high-precision tasks. Existing 3D integration methods struggle to bridge this gap due to the structural irregularity of sparse point clouds and the geometric distortion introduced by multi-view orthographic rendering. To overcome these barriers, we present ReMAP-DP, a novel framework synergizing standardized perspective reprojection with a structure-aware dual-stream diffusion policy. By coupling the re-projected views with pixel-aligned PointMaps, our dual-stream architecture leverages learnable modality embeddings to fuse frozen semantic features and explicit geometric descriptors, ensuring precise implicit patch-level alignment. Extensive experiments across simulation and real-world environments demonstrate ReMAP-DP's superior performance in diverse manipulation tasks. On RoboTwin 2.0, it attains a 59.3% average success rate, outperforming the DP3 baseline by +6.6%. On ManiSkill 3, our method yields a 28% improvement over DP3 on the geometrically challenging Stack Cube task. Furthermore, ReMAP-DP exhibits remarkable real-world robustness, executing high-precision and dynamic manipulations with superior data efficiency from only a handful of demonstrations. Project page is available at: https://icr-lab.github.io/ReMAP-DP/
RnG: A Unified Transformer for Complete 3D Modeling from Partial Observations
Mar 01, 2026Human perceive the 3D world through 2D observations from limited viewpoints. While recent feed-forward generalizable 3D reconstruction models excel at recovering 3D structures from sparse images, their representations are often confined to observed regions, leaving unseen geometry un-modeled. This raises a key, fundamental challenge: Can we infer a complete 3D structure from partial 2D observations? We present RnG (Reconstruction and Generation), a novel feed-forward Transformer that unifies these two tasks by predicting an implicit, complete 3D representation. At the core of RnG, we propose a reconstruction-guided causal attention mechanism that separates reconstruction and generation at the attention level, and treats the KV-cache as an implicit 3D representation. Then, arbitrary poses can efficiently query this cache to render high-fidelity, novel-view RGBD outputs. As a result, RnG not only accurately reconstructs visible geometry but also generates plausible, coherent unseen geometry and appearance. Our method achieves state-of-the-art performance in both generalizable 3D reconstruction and novel view generation, while operating efficiently enough for real-time interactive applications. Project page: https://npucvr.github.io/RnG
Probing and Bridging Geometry-Interaction Cues for Affordance Reasoning in Vision Foundation Models
Feb 24, 2026What does it mean for a visual system to truly understand affordance? We argue that this understanding hinges on two complementary capacities: geometric perception, which identifies the structural parts of objects that enable interaction, and interaction perception, which models how an agent's actions engage with those parts. To test this hypothesis, we conduct a systematic probing of Visual Foundation Models (VFMs). We find that models like DINO inherently encode part-level geometric structures, while generative models like Flux contain rich, verb-conditioned spatial attention maps that serve as implicit interaction priors. Crucially, we demonstrate that these two dimensions are not merely correlated but are composable elements of affordance. By simply fusing DINO's geometric prototypes with Flux's interaction maps in a training-free and zero-shot manner, we achieve affordance estimation competitive with weakly-supervised methods. This final fusion experiment confirms that geometric and interaction perception are the fundamental building blocks of affordance understanding in VFMs, providing a mechanistic account of how perception grounds action.
A Kung Fu Athlete Bot That Can Do It All Day: Highly Dynamic, Balance-Challenging Motion Dataset and Autonomous Fall-Resilient Tracking
Feb 14, 2026Current humanoid motion tracking systems can execute routine and moderately dynamic behaviors, yet significant gaps remain near hardware performance limits and algorithmic robustness boundaries. Martial arts represent an extreme case of highly dynamic human motion, characterized by rapid center-of-mass shifts, complex coordination, and abrupt posture transitions. However, datasets tailored to such high-intensity scenarios remain scarce. To address this gap, we construct KungFuAthlete, a high-dynamic martial arts motion dataset derived from professional athletes' daily training videos. The dataset includes ground and jump subsets covering representative complex motion patterns. The jump subset exhibits substantially higher joint, linear, and angular velocities compared to commonly used datasets such as LAFAN1, PHUMA, and AMASS, indicating significantly increased motion intensity and complexity. Importantly, even professional athletes may fail during highly dynamic movements. Similarly, humanoid robots are prone to instability and falls under external disturbances or execution errors. Most prior work assumes motion execution remains within safe states and lacks a unified strategy for modeling unsafe states and enabling reliable autonomous recovery. We propose a novel training paradigm that enables a single policy to jointly learn high-dynamic motion tracking and fall recovery, unifying agile execution and stabilization within one framework. This framework expands robotic capability from pure motion tracking to recovery-enabled execution, promoting more robust and autonomous humanoid performance in real-world high-dynamic scenarios.
Adaptive and Balanced Re-initialization for Long-timescale Continual Test-time Domain Adaptation
Feb 06, 2026Continual test-time domain adaptation (CTTA) aims to adjust models so that they can perform well over time across non-stationary environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: Can the model adapt to continually changing environments over a long time? In this work, we explore facilitating better CTTA in the long run using a re-initialization (or reset) based method. First, we observe that the long-term performance is associated with the trajectory pattern in label flip. Based on this observed correlation, we propose a simple yet effective policy, Adaptive-and-Balanced Re-initialization (ABR), towards preserving the model's long-term performance. In particular, ABR performs weight re-initialization using adaptive intervals. The adaptive interval is determined based on the change in label flip. The proposed method is validated on extensive CTTA benchmarks, achieving superior performance.
Quality-Driven and Diversity-Aware Sample Expansion for Robust Marine Obstacle Segmentation
Dec 16, 2025Marine obstacle detection demands robust segmentation under challenging conditions, such as sun glitter, fog, and rapidly changing wave patterns. These factors degrade image quality, while the scarcity and structural repetition of marine datasets limit the diversity of available training data. Although mask-conditioned diffusion models can synthesize layout-aligned samples, they often produce low-diversity outputs when conditioned on low-entropy masks and prompts, limiting their utility for improving robustness. In this paper, we propose a quality-driven and diversity-aware sample expansion pipeline that generates training data entirely at inference time, without retraining the diffusion model. The framework combines two key components:(i) a class-aware style bank that constructs high-entropy, semantically grounded prompts, and (ii) an adaptive annealing sampler that perturbs early conditioning, while a COD-guided proportional controller regulates this perturbation to boost diversity without compromising layout fidelity. Across marine obstacle benchmarks, augmenting training data with these controlled synthetic samples consistently improves segmentation performance across multiple backbones and increases visual variation in rare and texture-sensitive classes.
Structural Energy-Guided Sampling for View-Consistent Text-to-3D
Aug 23, 2025Text-to-3D generation often suffers from the Janus problem, where objects look correct from the front but collapse into duplicated or distorted geometry from other angles. We attribute this failure to viewpoint bias in 2D diffusion priors, which propagates into 3D optimization. To address this, we propose Structural Energy-Guided Sampling (SEGS), a training-free, plug-and-play framework that enforces multi-view consistency entirely at sampling time. SEGS defines a structural energy in a PCA subspace of intermediate U-Net features and injects its gradients into the denoising trajectory, steering geometry toward the intended viewpoint while preserving appearance fidelity. Integrated seamlessly into SDS/VSD pipelines, SEGS significantly reduces Janus artifacts, achieving improved geometric alignment and viewpoint consistency without retraining or weight modification.
3D Gaussian Representations with Motion Trajectory Field for Dynamic Scene Reconstruction
Aug 10, 2025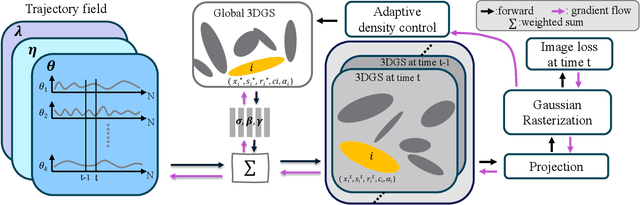
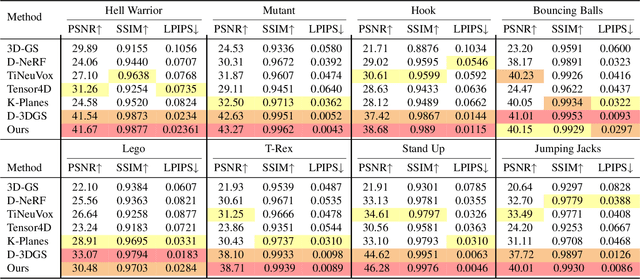
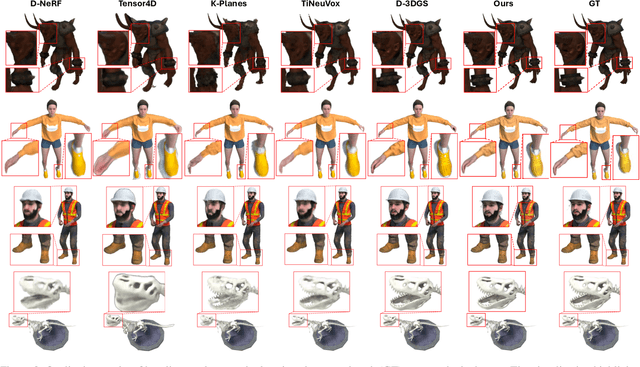

This paper addresses the challenge of novel-view synthesis and motion reconstruction of dynamic scenes from monocular video, which is critical for many robotic applications. Although Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have demonstrated remarkable success in rendering static scenes, extending them to reconstruct dynamic scenes remains challenging. In this work, we introduce a novel approach that combines 3DGS with a motion trajectory field, enabling precise handling of complex object motions and achieving physically plausible motion trajectories. By decoupling dynamic objects from static background, our method compactly optimizes the motion trajectory field. The approach incorporates time-invariant motion coefficients and shared motion trajectory bases to capture intricate motion patterns while minimizing optimization complexity. Extensive experiments demonstrate that our approach achieves state-of-the-art results in both novel-view synthesis and motion trajectory recovery from monocular video, advancing the capabilities of dynamic scene reconstruction.