 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReMAP-DP: Reprojected Multi-view Aligned PointMaps for Diffusion Policy
Mar 16, 2026Generalist robot policies built upon 2D visual representations excel at semantic reasoning but inherently lack the explicit 3D spatial awareness required for high-precision tasks. Existing 3D integration methods struggle to bridge this gap due to the structural irregularity of sparse point clouds and the geometric distortion introduced by multi-view orthographic rendering. To overcome these barriers, we present ReMAP-DP, a novel framework synergizing standardized perspective reprojection with a structure-aware dual-stream diffusion policy. By coupling the re-projected views with pixel-aligned PointMaps, our dual-stream architecture leverages learnable modality embeddings to fuse frozen semantic features and explicit geometric descriptors, ensuring precise implicit patch-level alignment. Extensive experiments across simulation and real-world environments demonstrate ReMAP-DP's superior performance in diverse manipulation tasks. On RoboTwin 2.0, it attains a 59.3% average success rate, outperforming the DP3 baseline by +6.6%. On ManiSkill 3, our method yields a 28% improvement over DP3 on the geometrically challenging Stack Cube task. Furthermore, ReMAP-DP exhibits remarkable real-world robustness, executing high-precision and dynamic manipulations with superior data efficiency from only a handful of demonstrations. Project page is available at: https://icr-lab.github.io/ReMAP-DP/
A Kung Fu Athlete Bot That Can Do It All Day: Highly Dynamic, Balance-Challenging Motion Dataset and Autonomous Fall-Resilient Tracking
Feb 14, 2026Current humanoid motion tracking systems can execute routine and moderately dynamic behaviors, yet significant gaps remain near hardware performance limits and algorithmic robustness boundaries. Martial arts represent an extreme case of highly dynamic human motion, characterized by rapid center-of-mass shifts, complex coordination, and abrupt posture transitions. However, datasets tailored to such high-intensity scenarios remain scarce. To address this gap, we construct KungFuAthlete, a high-dynamic martial arts motion dataset derived from professional athletes' daily training videos. The dataset includes ground and jump subsets covering representative complex motion patterns. The jump subset exhibits substantially higher joint, linear, and angular velocities compared to commonly used datasets such as LAFAN1, PHUMA, and AMASS, indicating significantly increased motion intensity and complexity. Importantly, even professional athletes may fail during highly dynamic movements. Similarly, humanoid robots are prone to instability and falls under external disturbances or execution errors. Most prior work assumes motion execution remains within safe states and lacks a unified strategy for modeling unsafe states and enabling reliable autonomous recovery. We propose a novel training paradigm that enables a single policy to jointly learn high-dynamic motion tracking and fall recovery, unifying agile execution and stabilization within one framework. This framework expands robotic capability from pure motion tracking to recovery-enabled execution, promoting more robust and autonomous humanoid performance in real-world high-dynamic scenarios.
Understanding the Impact of Differentially Private Training on Memorization of Long-Tailed Data
Feb 01, 2026Recent research shows that modern deep learning models achieve high predictive accuracy partly by memorizing individual training samples. Such memorization raises serious privacy concerns, motivating the widespread adoption of differentially private training algorithms such as DP-SGD. However, a growing body of empirical work shows that DP-SGD often leads to suboptimal generalization performance, particularly on long-tailed data that contain a large number of rare or atypical samples. Despite these observations, a theoretical understanding of this phenomenon remains largely unexplored, and existing differential privacy analysis are difficult to extend to the nonconvex and nonsmooth neural networks commonly used in practice. In this work, we develop the first theoretical framework for analyzing DP-SGD on long-tailed data from a feature learning perspective. We show that the test error of DP-SGD-trained models on the long-tailed subpopulation is significantly larger than the overall test error over the entire dataset. Our analysis further characterizes the training dynamics of DP-SGD, demonstrating how gradient clipping and noise injection jointly adversely affect the model's ability to memorize informative but underrepresented samples. Finally, we validate our theoretical findings through extensive experiments on both synthetic and real-world datasets.
Evaluating the Challenges of LLMs in Real-world Medical Follow-up: A Comparative Study and An Optimized Framework
Dec 22, 2025When applied directly in an end-to-end manner to medical follow-up tasks, Large Language Models (LLMs) often suffer from uncontrolled dialog flow and inaccurate information extraction due to the complexity of follow-up forms. To address this limitation, we designed and compared two follow-up chatbot systems: an end-to-end LLM-based system (control group) and a modular pipeline with structured process control (experimental group). Experimental results show that while the end-to-end approach frequently fails on lengthy and complex forms, our modular method-built on task decomposition, semantic clustering, and flow management-substantially improves dialog stability and extraction accuracy. Moreover, it reduces the number of dialogue turns by 46.73% and lowers token consumption by 80% to 87.5%. These findings highlight the necessity of integrating external control mechanisms when deploying LLMs in high-stakes medical follow-up scenarios.
Prompt-Guided Dual-Path UNet with Mamba for Medical Image Segmentation
Mar 25, 2025Convolutional neural networks (CNNs) and transformers are widely employed in constructing UNet architectures for medical image segmentation tasks. However, CNNs struggle to model long-range dependencies, while transformers suffer from quadratic computational complexity. Recently, Mamba, a type of State Space Models, has gained attention for its exceptional ability to model long-range interactions while maintaining linear computational complexity. Despite the emergence of several Mamba-based methods, they still present the following limitations: first, their network designs generally lack perceptual capabilities for the original input data; second, they primarily focus on capturing global information, while often neglecting local details. To address these challenges, we propose a prompt-guided CNN-Mamba dual-path UNet, termed PGM-UNet, for medical image segmentation. Specifically, we introduce a prompt-guided residual Mamba module that adaptively extracts dynamic visual prompts from the original input data, effectively guiding Mamba in capturing global information. Additionally, we design a local-global information fusion network, comprising a local information extraction module, a prompt-guided residual Mamba module, and a multi-focus attention fusion module, which effectively integrates local and global information. Furthermore, inspired by Kolmogorov-Arnold Networks (KANs), we develop a multi-scale information extraction module to capture richer contextual information without altering the resolution. We conduct extensive experiments on the ISIC-2017, ISIC-2018, DIAS, and DRIVE. The results demonstrate that the proposed method significantly outperforms state-of-the-art approaches in multiple medical image segmentation tasks.
Deep Contrastive Multi-view Clustering under Semantic Feature Guidance
Mar 09, 2024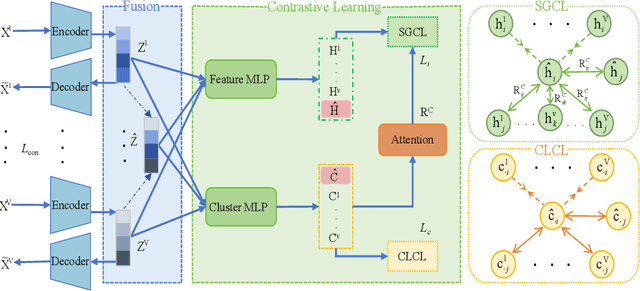
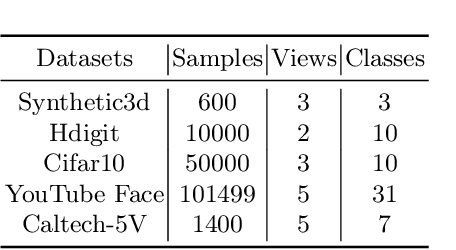
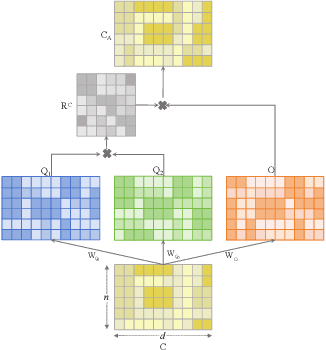
Contrastive learning has achieved promising performance in the field of multi-view clustering recently. However, the positive and negative sample construction mechanisms ignoring semantic consistency lead to false negative pairs, limiting the performance of existing algorithms from further improvement. To solve this problem, we propose a multi-view clustering framework named Deep Contrastive Multi-view Clustering under Semantic feature guidance (DCMCS) to alleviate the influence of false negative pairs. Specifically, view-specific features are firstly extracted from raw features and fused to obtain fusion view features according to view importance. To mitigate the interference of view-private information, specific view and fusion view semantic features are learned by cluster-level contrastive learning and concatenated to measure the semantic similarity of instances. By minimizing instance-level contrastive loss weighted by semantic similarity, DCMCS adaptively weakens contrastive leaning between false negative pairs. Experimental results on several public datasets demonstrate the proposed framework outperforms the state-of-the-art methods.
A Coarse to Fine Framework for Object Detection in High Resolution Image
Mar 02, 2023Object detection is a fundamental problem in computer vision, aiming at locating and classifying objects in image. Although current devices can easily take very high-resolution images, current approaches of object detection seldom consider detecting tiny object or the large scale variance problem in high resolution images. In this paper, we introduce a simple yet efficient approach that improves accuracy of object detection especially for small objects and large scale variance scene while reducing the computational cost in high resolution image. Inspired by observing that overall detection accuracy is reduced if the image is properly down-sampled but the recall rate is not significantly reduced. Besides, small objects can be better detected by inputting high-resolution images even if using lightweight detector. We propose a cluster-based coarse-to-fine object detection framework to enhance the performance for detecting small objects while ensure the accuracy of large objects in high-resolution images. For the first stage, we perform coarse detection on the down-sampled image and center localization of small objects by lightweight detector on high-resolution image, and then obtains image chips based on cluster region generation method by coarse detection and center localization results, and further sends chips to the second stage detector for fine detection. Finally, we merge the coarse detection and fine detection results. Our approach can make good use of the sparsity of the objects and the information in high-resolution image, thereby making the detection more efficient. Experiment results show that our proposed approach achieves promising performance compared with other state-of-the-art detectors.
Truthful Generalized Linear Models
Sep 16, 2022In this paper we study estimating Generalized Linear Models (GLMs) in the case where the agents (individuals) are strategic or self-interested and they concern about their privacy when reporting data. Compared with the classical setting, here we aim to design mechanisms that can both incentivize most agents to truthfully report their data and preserve the privacy of individuals' reports, while their outputs should also close to the underlying parameter. In the first part of the paper, we consider the case where the covariates are sub-Gaussian and the responses are heavy-tailed where they only have the finite fourth moments. First, motivated by the stationary condition of the maximizer of the likelihood function, we derive a novel private and closed form estimator. Based on the estimator, we propose a mechanism which has the following properties via some appropriate design of the computation and payment scheme for several canonical models such as linear regression, logistic regression and Poisson regression: (1) the mechanism is $o(1)$-jointly differentially private (with probability at least $1-o(1)$); (2) it is an $o(\frac{1}{n})$-approximate Bayes Nash equilibrium for a $(1-o(1))$-fraction of agents to truthfully report their data, where $n$ is the number of agents; (3) the output could achieve an error of $o(1)$ to the underlying parameter; (4) it is individually rational for a $(1-o(1))$ fraction of agents in the mechanism ; (5) the payment budget required from the analyst to run the mechanism is $o(1)$. In the second part, we consider the linear regression model under more general setting where both covariates and responses are heavy-tailed and only have finite fourth moments. By using an $\ell_4$-norm shrinkage operator, we propose a private estimator and payment scheme which have similar properties as in the sub-Gaussian case.
Privacy-preserving Crowd-guided AI Decision-making in Ethical Dilemmas
Jun 04, 2019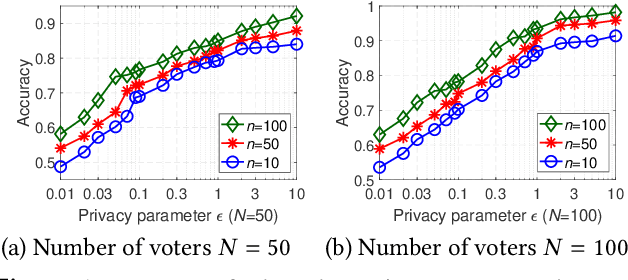
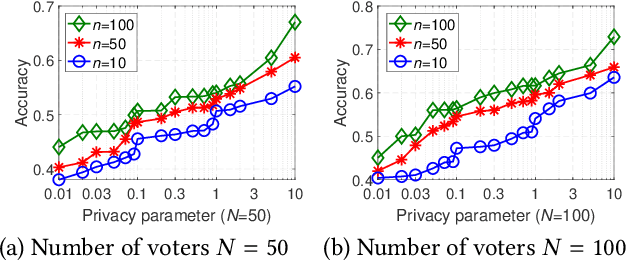
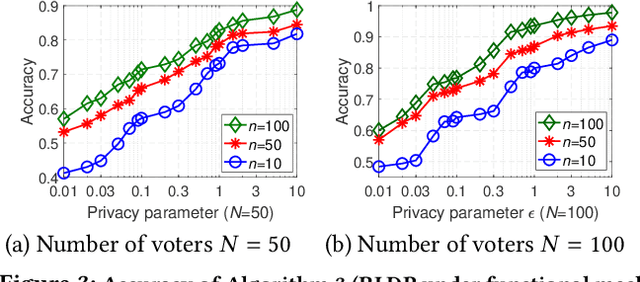
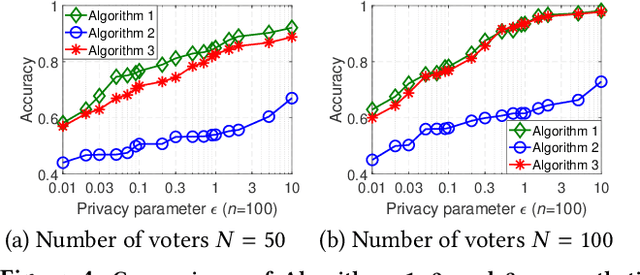
With the rapid development of artificial intelligence (AI), ethical issues surrounding AI have attracted increasing attention. In particular, autonomous vehicles may face moral dilemmas in accident scenarios, such as staying the course resulting in hurting pedestrians or swerving leading to hurting passengers. To investigate such ethical dilemmas, recent studies have adopted preference aggregation, in which each voter expresses her/his preferences over decisions for the possible ethical dilemma scenarios, and a centralized system aggregates these preferences to obtain the winning decision. Although a useful methodology for building ethical AI systems, such an approach can potentially violate the privacy of voters since moral preferences are sensitive information and their disclosure can be exploited by malicious parties. In this paper, we report a first-of-its-kind privacy-preserving crowd-guided AI decision-making approach in ethical dilemmas. We adopt the notion of differential privacy to quantify privacy and consider four granularities of privacy protection by taking voter-/record-level privacy protection and centralized/distributed perturbation into account, resulting in four approaches VLCP, RLCP, VLDP, and RLDP. Moreover, we propose different algorithms to achieve these privacy protection granularities, while retaining the accuracy of the learned moral preference model. Specifically, VLCP and RLCP are implemented with the data aggregator setting a universal privacy parameter and perturbing the averaged moral preference to protect the privacy of voters' data. VLDP and RLDP are implemented in such a way that each voter perturbs her/his local moral preference with a personalized privacy parameter. Extensive experiments on both synthetic and real data demonstrate that the proposed approach can achieve high accuracy of preference aggregation while protecting individual voter's privacy.
Robust Kernelized Multi-View Self-Representations for Clustering by Tensor Multi-Rank Minimization
Sep 15, 2017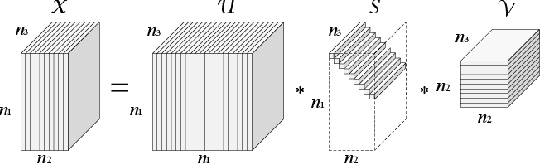

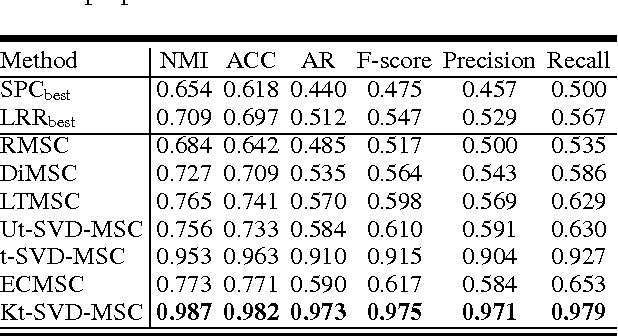
Most recently, tensor-SVD is implemented on multi-view self-representation clustering and has achieved the promising results in many real-world applications such as face clustering, scene clustering and generic object clustering. However, tensor-SVD based multi-view self-representation clustering is proposed originally to solve the clustering problem in the multiple linear subspaces, leading to unsatisfactory results when dealing with the case of non-linear subspaces. To handle data clustering from the non-linear subspaces, a kernelization method is designed by mapping the data from the original input space to a new feature space in which the transformed data can be clustered by a multiple linear clustering method. In this paper, we make an optimization model for the kernelized multi-view self-representation clustering problem. We also develop a new efficient algorithm based on the alternation direction method and infer a closed-form solution. Since all the subproblems can be solved exactly, the proposed optimization algorithm is guaranteed to obtain the optimal solution. In particular, the original tensor-based multi-view self-representation clustering problem is a special case of our approach and can be solved by our algorithm. Experimental results on several popular real-world clustering datasets demonstrate that our approach achieves the state-of-the-art performance.