 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-organized MT Direction Maps Emerge from Spatiotemporal Contrastive Optimization
May 12, 2026The spatial and functional organization of the primate visual cortex is a fundamental problem in neuroscience. While recent computational frameworks like the Topographic Deep Artificial Neural Network (TDANN) have successfully modeled spatial organization in the ventral stream, the computational origins of the dorsal stream's distinct topographies, such as direction-selective maps in the middle temporal (MT) area, remain largely unresolved. In this work, we present a spatiotemporal TDANN to investigate whether MT topography is governed by the same universal principles. By training a 3D ResNet on naturalistic videos via a Momentum Contrast (MoCo) self-supervised paradigm alongside a biologically inspired spatial loss, we demonstrate the spontaneous emergence of brain-like direction maps and topological pinwheel structures. Crucially, we reveal that MT tuning properties, characterized by strong direction selectivity paired with a residual axial component, arise from a strict optimization trade-off between task-driven discriminative pressure and spatial regularization. The model's representations quantitatively match in vivo macaque MT physiological baselines, including direction selectivity index, circular variance, and pinwheel density. These findings unify the computational origins of the ventral and dorsal streams, establishing a general mechanism for cortical self-organization.
A Kung Fu Athlete Bot That Can Do It All Day: Highly Dynamic, Balance-Challenging Motion Dataset and Autonomous Fall-Resilient Tracking
Feb 14, 2026Current humanoid motion tracking systems can execute routine and moderately dynamic behaviors, yet significant gaps remain near hardware performance limits and algorithmic robustness boundaries. Martial arts represent an extreme case of highly dynamic human motion, characterized by rapid center-of-mass shifts, complex coordination, and abrupt posture transitions. However, datasets tailored to such high-intensity scenarios remain scarce. To address this gap, we construct KungFuAthlete, a high-dynamic martial arts motion dataset derived from professional athletes' daily training videos. The dataset includes ground and jump subsets covering representative complex motion patterns. The jump subset exhibits substantially higher joint, linear, and angular velocities compared to commonly used datasets such as LAFAN1, PHUMA, and AMASS, indicating significantly increased motion intensity and complexity. Importantly, even professional athletes may fail during highly dynamic movements. Similarly, humanoid robots are prone to instability and falls under external disturbances or execution errors. Most prior work assumes motion execution remains within safe states and lacks a unified strategy for modeling unsafe states and enabling reliable autonomous recovery. We propose a novel training paradigm that enables a single policy to jointly learn high-dynamic motion tracking and fall recovery, unifying agile execution and stabilization within one framework. This framework expands robotic capability from pure motion tracking to recovery-enabled execution, promoting more robust and autonomous humanoid performance in real-world high-dynamic scenarios.
Venus: An Efficient Edge Memory-and-Retrieval System for VLM-based Online Video Understanding
Dec 08, 2025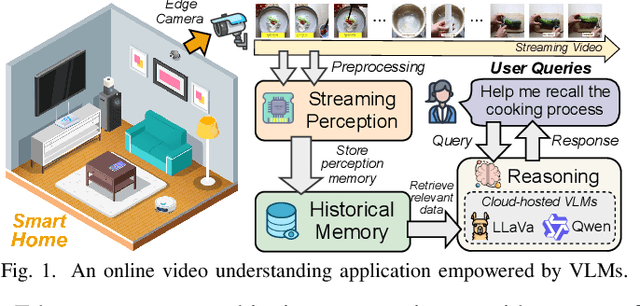
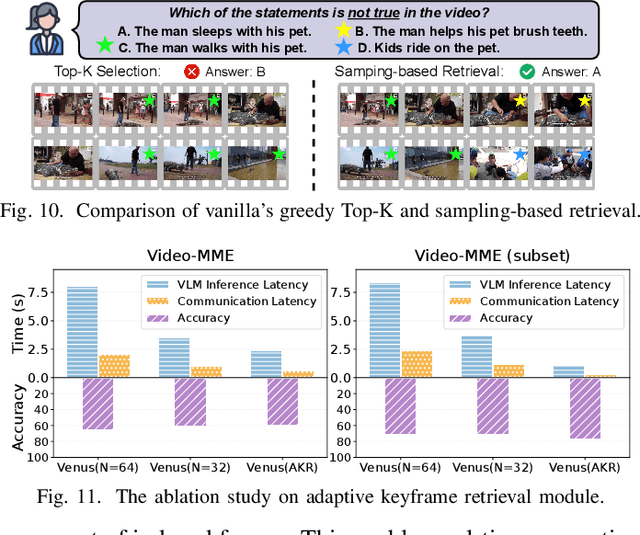
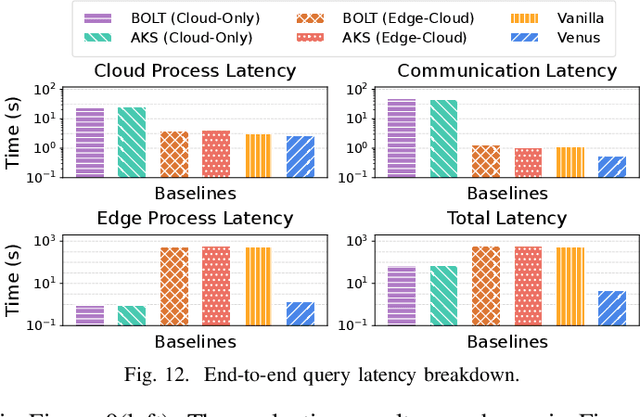
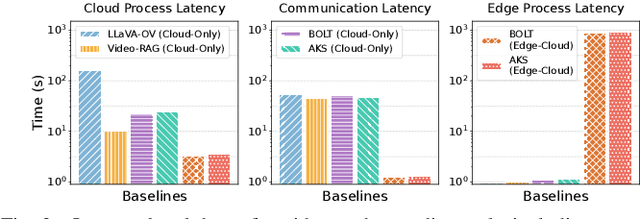
Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.
Jupiter: Fast and Resource-Efficient Collaborative Inference of Generative LLMs on Edge Devices
Apr 11, 2025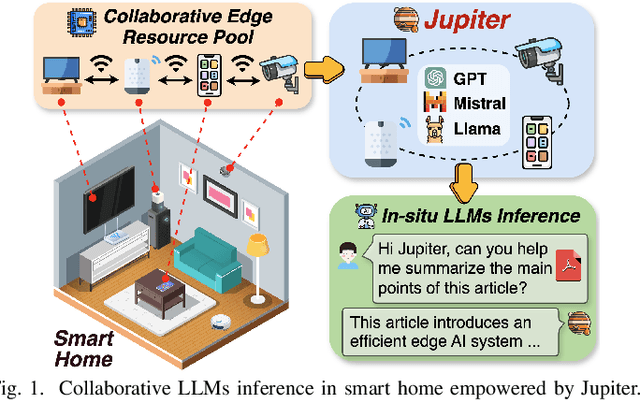
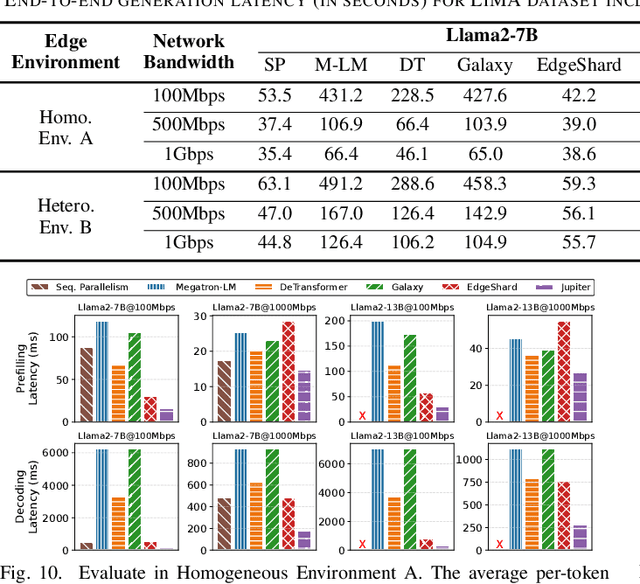
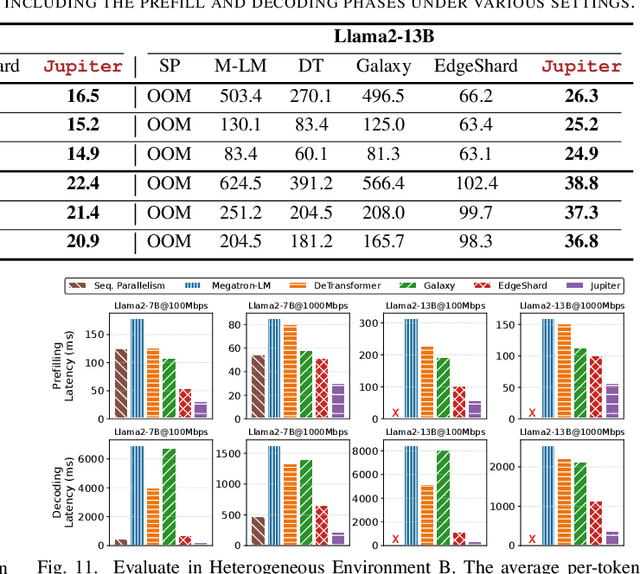
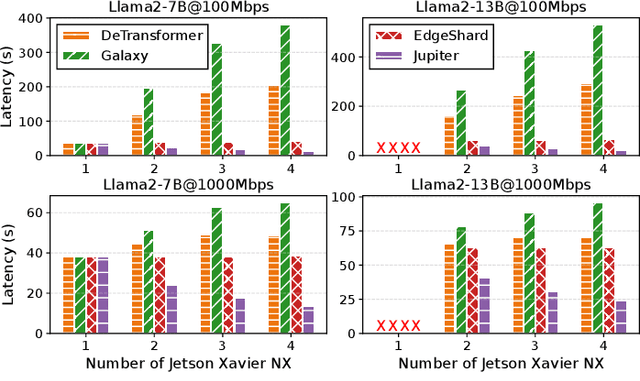
Generative large language models (LLMs) have garnered significant attention due to their exceptional capabilities in various AI tasks. Traditionally deployed in cloud datacenters, LLMs are now increasingly moving towards more accessible edge platforms to protect sensitive user data and ensure privacy preservation. The limited computational resources of individual edge devices, however, can result in excessively prolonged inference latency and overwhelmed memory usage. While existing research has explored collaborative edge computing to break the resource wall of individual devices, these solutions yet suffer from massive communication overhead and under-utilization of edge resources. Furthermore, they focus exclusively on optimizing the prefill phase, neglecting the crucial autoregressive decoding phase for generative LLMs. To address that, we propose Jupiter, a fast, scalable, and resource-efficient collaborative edge AI system for generative LLM inference. Jupiter introduces a flexible pipelined architecture as a principle and differentiates its system design according to the differentiated characteristics of the prefill and decoding phases. For prefill phase, Jupiter submits a novel intra-sequence pipeline parallelism and develops a meticulous parallelism planning strategy to maximize resource efficiency; For decoding, Jupiter devises an effective outline-based pipeline parallel decoding mechanism combined with speculative decoding, which further magnifies inference acceleration. Extensive evaluation based on realistic implementation demonstrates that Jupiter remarkably outperforms state-of-the-art approaches under various edge environment setups, achieving up to 26.1x end-to-end latency reduction while rendering on-par generation quality.
Prompt-Guided Dual-Path UNet with Mamba for Medical Image Segmentation
Mar 25, 2025Convolutional neural networks (CNNs) and transformers are widely employed in constructing UNet architectures for medical image segmentation tasks. However, CNNs struggle to model long-range dependencies, while transformers suffer from quadratic computational complexity. Recently, Mamba, a type of State Space Models, has gained attention for its exceptional ability to model long-range interactions while maintaining linear computational complexity. Despite the emergence of several Mamba-based methods, they still present the following limitations: first, their network designs generally lack perceptual capabilities for the original input data; second, they primarily focus on capturing global information, while often neglecting local details. To address these challenges, we propose a prompt-guided CNN-Mamba dual-path UNet, termed PGM-UNet, for medical image segmentation. Specifically, we introduce a prompt-guided residual Mamba module that adaptively extracts dynamic visual prompts from the original input data, effectively guiding Mamba in capturing global information. Additionally, we design a local-global information fusion network, comprising a local information extraction module, a prompt-guided residual Mamba module, and a multi-focus attention fusion module, which effectively integrates local and global information. Furthermore, inspired by Kolmogorov-Arnold Networks (KANs), we develop a multi-scale information extraction module to capture richer contextual information without altering the resolution. We conduct extensive experiments on the ISIC-2017, ISIC-2018, DIAS, and DRIVE. The results demonstrate that the proposed method significantly outperforms state-of-the-art approaches in multiple medical image segmentation tasks.
Pluto and Charon: A Time and Memory Efficient Collaborative Edge AI Framework for Personal LLMs Fine-Tuning
Aug 20, 2024Large language models (LLMs) have unlocked a plethora of powerful applications at the network edge, such as intelligent personal assistants. Data privacy and security concerns have prompted a shift towards edge-based fine-tuning of personal LLMs, away from cloud reliance. However, this raises issues of computational intensity and resource scarcity, hindering training efficiency and feasibility. While current studies investigate parameter-efficient fine-tuning (PEFT) techniques to mitigate resource constraints, our analysis indicates that these techniques are not sufficiently resource-efficient for edge devices. To tackle these challenges, we propose Pluto and Charon (PAC), a time and memory efficient collaborative edge AI framework for personal LLMs fine-tuning. PAC breaks the resource wall of personal LLMs fine-tuning with a sophisticated algorithm-system co-design. (1) Algorithmically, PAC implements a personal LLMs fine-tuning technique that is efficient in terms of parameters, time, and memory. It utilizes Parallel Adapters to circumvent the need for a full backward pass through the LLM backbone. Additionally, an activation cache mechanism further streamlining the process by negating the necessity for repeated forward passes across multiple epochs. (2) Systematically, PAC leverages edge devices in close proximity, pooling them as a collective resource for in-situ personal LLMs fine-tuning, utilizing a hybrid data and pipeline parallelism to orchestrate distributed training. The use of the activation cache eliminates the need for forward pass through the LLM backbone,enabling exclusive fine-tuning of the Parallel Adapters using data parallelism. Extensive evaluation based on prototype implementation demonstrates that PAC remarkably outperforms state-of-the-art approaches, achieving up to 8.64x end-to-end speedup and up to 88.16% reduction in memory footprint.
Deep Convolutional Neural Networks for Molecular Subtyping of Gliomas Using Magnetic Resonance Imaging
Mar 10, 2022Knowledge of molecular subtypes of gliomas can provide valuable information for tailored therapies. This study aimed to investigate the use of deep convolutional neural networks (DCNNs) for noninvasive glioma subtyping with radiological imaging data according to the new taxonomy announced by the World Health Organization in 2016. Methods: A DCNN model was developed for the prediction of the five glioma subtypes based on a hierarchical classification paradigm. This model used three parallel, weight-sharing, deep residual learning networks to process 2.5-dimensional input of trimodal MRI data, including T1-weighted, T1-weighted with contrast enhancement, and T2-weighted images. A data set comprising 1,016 real patients was collected for evaluation of the developed DCNN model. The predictive performance was evaluated via the area under the curve (AUC) from the receiver operating characteristic analysis. For comparison, the performance of a radiomics-based approach was also evaluated. Results: The AUCs of the DCNN model for the four classification tasks in the hierarchical classification paradigm were 0.89, 0.89, 0.85, and 0.66, respectively, as compared to 0.85, 0.75, 0.67, and 0.59 of the radiomics approach. Conclusion: The results showed that the developed DCNN model can predict glioma subtypes with promising performance, given sufficient, non-ill-balanced training data.