 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Set Label Shift with Test Time Out-of-Distribution Reference
May 09, 2025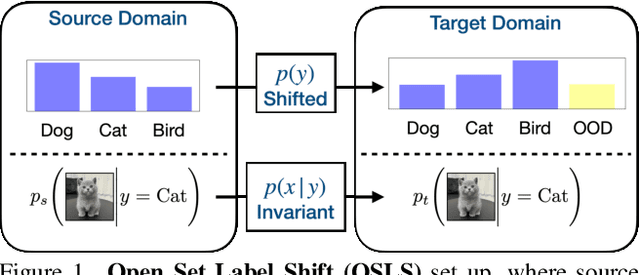
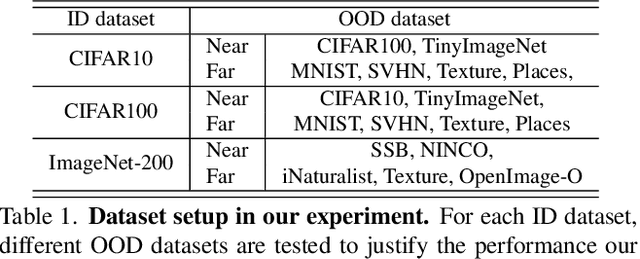
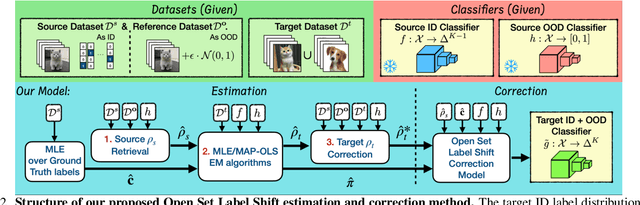

Open set label shift (OSLS) occurs when label distributions change from a source to a target distribution, and the target distribution has an additional out-of-distribution (OOD) class. In this work, we build estimators for both source and target open set label distributions using a source domain in-distribution (ID) classifier and an ID/OOD classifier. With reasonable assumptions on the ID/OOD classifier, the estimators are assembled into a sequence of three stages: 1) an estimate of the source label distribution of the OOD class, 2) an EM algorithm for Maximum Likelihood estimates (MLE) of the target label distribution, and 3) an estimate of the target label distribution of OOD class under relaxed assumptions on the OOD classifier. The sampling errors of estimates in 1) and 3) are quantified with a concentration inequality. The estimation result allows us to correct the ID classifier trained on the source distribution to the target distribution without retraining. Experiments on a variety of open set label shift settings demonstrate the effectiveness of our model. Our code is available at https://github.com/ChangkunYe/OpenSetLabelShift.
Enhancing Features in Long-tailed Data Using Large Vision Mode
Apr 15, 2025Language-based foundation models, such as large language models (LLMs) or large vision-language models (LVLMs), have been widely studied in long-tailed recognition. However, the need for linguistic data is not applicable to all practical tasks. In this study, we aim to explore using large vision models (LVMs) or visual foundation models (VFMs) to enhance long-tailed data features without any language information. Specifically, we extract features from the LVM and fuse them with features in the baseline network's map and latent space to obtain the augmented features. Moreover, we design several prototype-based losses in the latent space to further exploit the potential of the augmented features. In the experimental section, we validate our approach on two benchmark datasets: ImageNet-LT and iNaturalist2018.
Latent-based Diffusion Model for Long-tailed Recognition
Apr 06, 2024Long-tailed imbalance distribution is a common issue in practical computer vision applications. Previous works proposed methods to address this problem, which can be categorized into several classes: re-sampling, re-weighting, transfer learning, and feature augmentation. In recent years, diffusion models have shown an impressive generation ability in many sub-problems of deep computer vision. However, its powerful generation has not been explored in long-tailed problems. We propose a new approach, the Latent-based Diffusion Model for Long-tailed Recognition (LDMLR), as a feature augmentation method to tackle the issue. First, we encode the imbalanced dataset into features using the baseline model. Then, we train a Denoising Diffusion Implicit Model (DDIM) using these encoded features to generate pseudo-features. Finally, we train the classifier using the encoded and pseudo-features from the previous two steps. The model's accuracy shows an improvement on the CIFAR-LT and ImageNet-LT datasets by using the proposed method.
Model Calibration in Dense Classification with Adaptive Label Perturbation
Aug 03, 2023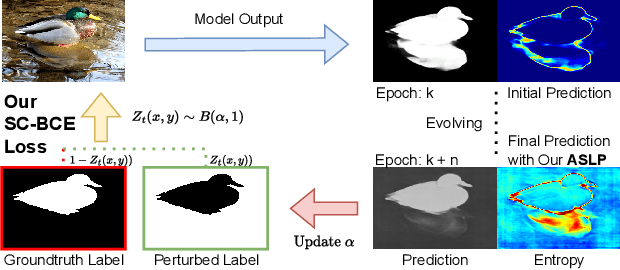
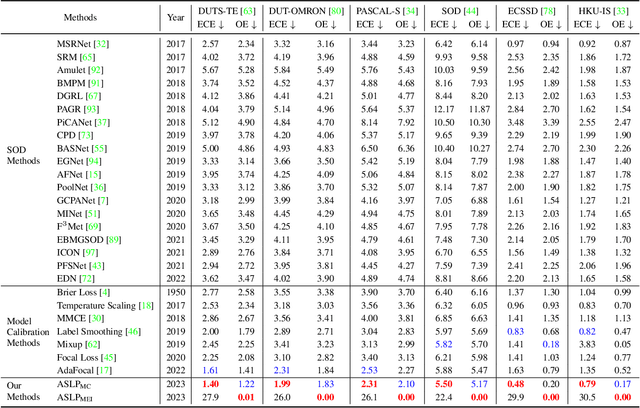
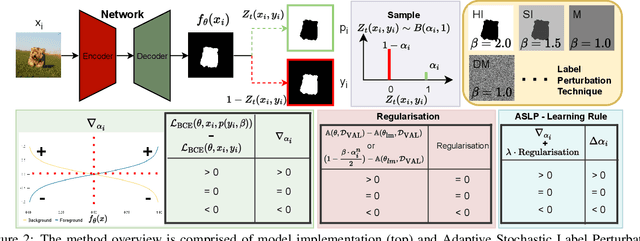
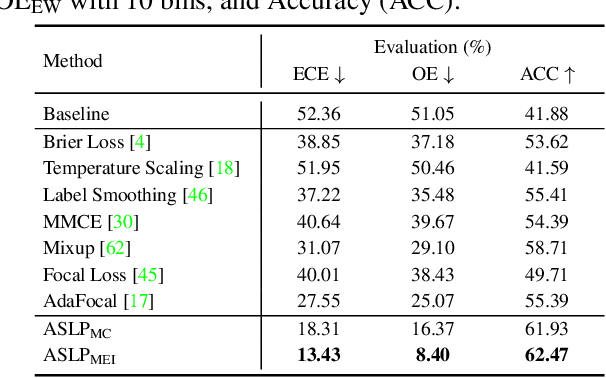
For safety-related applications, it is crucial to produce trustworthy deep neural networks whose prediction is associated with confidence that can represent the likelihood of correctness for subsequent decision-making. Existing dense binary classification models are prone to being over-confident. To improve model calibration, we propose Adaptive Stochastic Label Perturbation (ASLP) which learns a unique label perturbation level for each training image. ASLP employs our proposed Self-Calibrating Binary Cross Entropy (SC-BCE) loss, which unifies label perturbation processes including stochastic approaches (like DisturbLabel), and label smoothing, to correct calibration while maintaining classification rates. ASLP follows Maximum Entropy Inference of classic statistical mechanics to maximise prediction entropy with respect to missing information. It performs this while: (1) preserving classification accuracy on known data as a conservative solution, or (2) specifically improves model calibration degree by minimising the gap between the prediction accuracy and expected confidence of the target training label. Extensive results demonstrate that ASLP can significantly improve calibration degrees of dense binary classification models on both in-distribution and out-of-distribution data. The code is available on https://github.com/Carlisle-Liu/ASLP.
Efficient Gaussian Process Model on Class-Imbalanced Datasets for Generalized Zero-Shot Learning
Oct 11, 2022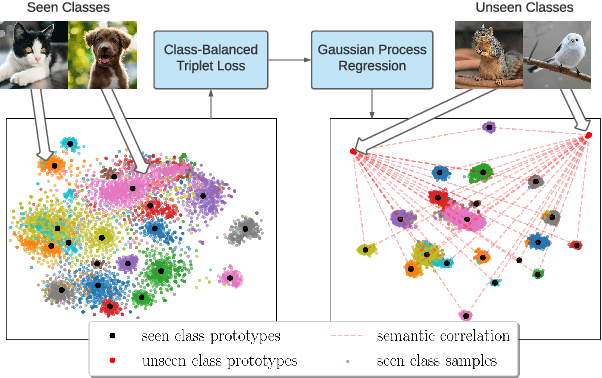
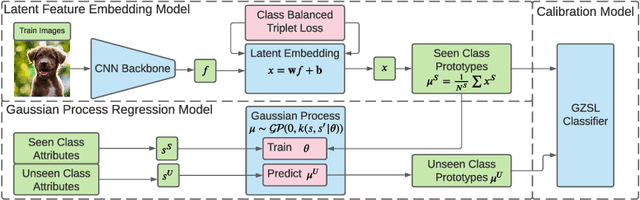
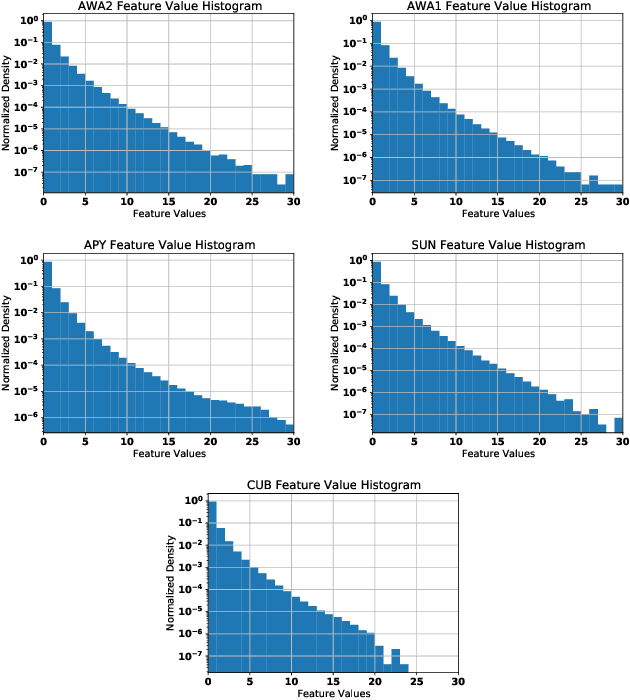
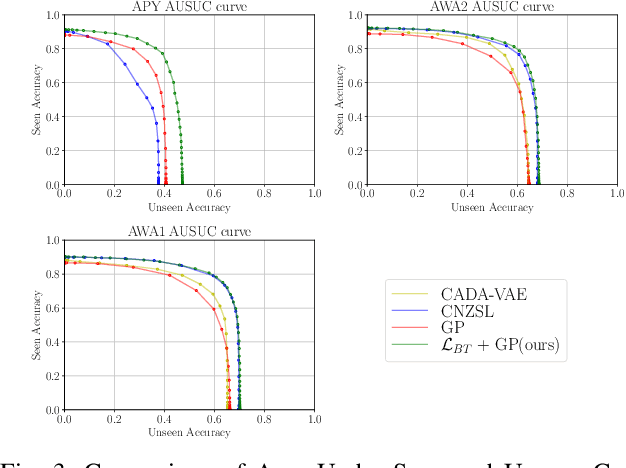
Zero-Shot Learning (ZSL) models aim to classify object classes that are not seen during the training process. However, the problem of class imbalance is rarely discussed, despite its presence in several ZSL datasets. In this paper, we propose a Neural Network model that learns a latent feature embedding and a Gaussian Process (GP) regression model that predicts latent feature prototypes of unseen classes. A calibrated classifier is then constructed for ZSL and Generalized ZSL tasks. Our Neural Network model is trained efficiently with a simple training strategy that mitigates the impact of class-imbalanced training data. The model has an average training time of 5 minutes and can achieve state-of-the-art (SOTA) performance on imbalanced ZSL benchmark datasets like AWA2, AWA1 and APY, while having relatively good performance on the SUN and CUB datasets.