 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent-based Diffusion Model for Long-tailed Recognition
Apr 06, 2024Long-tailed imbalance distribution is a common issue in practical computer vision applications. Previous works proposed methods to address this problem, which can be categorized into several classes: re-sampling, re-weighting, transfer learning, and feature augmentation. In recent years, diffusion models have shown an impressive generation ability in many sub-problems of deep computer vision. However, its powerful generation has not been explored in long-tailed problems. We propose a new approach, the Latent-based Diffusion Model for Long-tailed Recognition (LDMLR), as a feature augmentation method to tackle the issue. First, we encode the imbalanced dataset into features using the baseline model. Then, we train a Denoising Diffusion Implicit Model (DDIM) using these encoded features to generate pseudo-features. Finally, we train the classifier using the encoded and pseudo-features from the previous two steps. The model's accuracy shows an improvement on the CIFAR-LT and ImageNet-LT datasets by using the proposed method.
Feature Correlation Aggregation: on the Path to Better Graph Neural Networks
Sep 20, 2021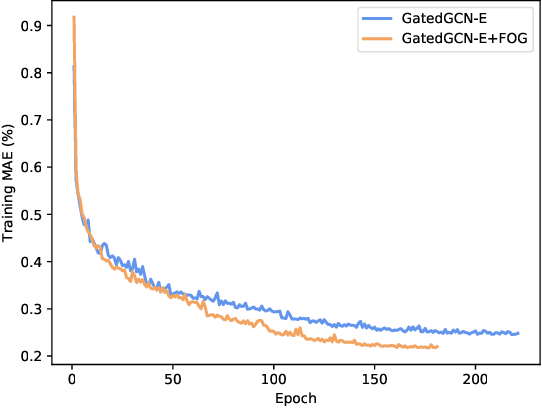

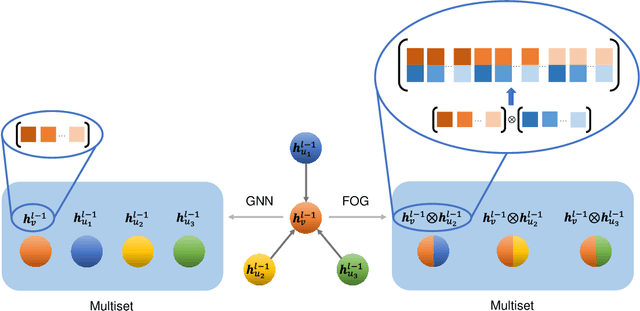
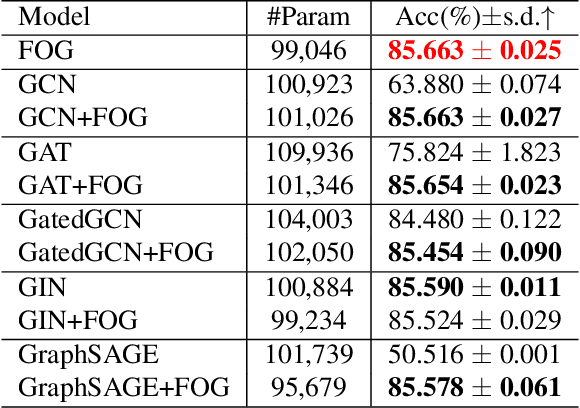
Prior to the introduction of Graph Neural Networks (GNNs), modeling and analyzing irregular data, particularly graphs, was thought to be the Achilles' heel of deep learning. The core concept of GNNs is to find a representation by recursively aggregating the representations of a central node and those of its neighbors. The core concept of GNNs is to find a representation by recursively aggregating the representations of a central node and those of its neighbor, and its success has been demonstrated by many GNNs' designs. However, most of them only focus on using the first-order information between a node and its neighbors. In this paper, we introduce a central node permutation variant function through a frustratingly simple and innocent-looking modification to the core operation of a GNN, namely the Feature cOrrelation aGgregation (FOG) module which learns the second-order information from feature correlation between a node and its neighbors in the pipeline. By adding FOG into existing variants of GNNs, we empirically verify this second-order information complements the features generated by original GNNs across a broad set of benchmarks. A tangible boost in performance of the model is observed where the model surpasses previous state-of-the-art results by a significant margin while employing fewer parameters. (e.g., 33.116% improvement on a real-world molecular dataset using graph convolutional networks).
Channel Recurrent Attention Networks for Video Pedestrian Retrieval
Oct 07, 2020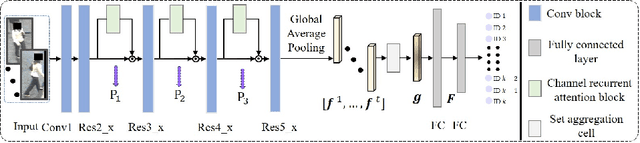
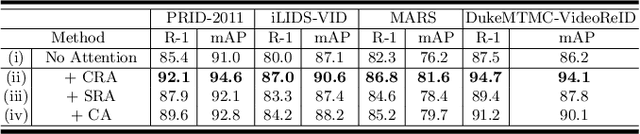

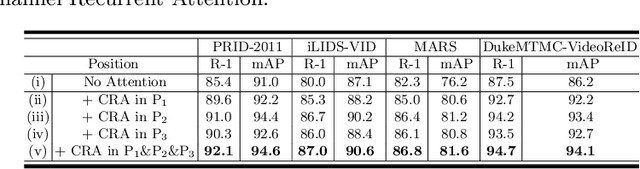
Full attention, which generates an attention value per element of the input feature maps, has been successfully demonstrated to be beneficial in visual tasks. In this work, we propose a fully attentional network, termed {\it channel recurrent attention network}, for the task of video pedestrian retrieval. The main attention unit, \textit{channel recurrent attention}, identifies attention maps at the frame level by jointly leveraging spatial and channel patterns via a recurrent neural network. This channel recurrent attention is designed to build a global receptive field by recurrently receiving and learning the spatial vectors. Then, a \textit{set aggregation} cell is employed to generate a compact video representation. Empirical experimental results demonstrate the superior performance of the proposed deep network, outperforming current state-of-the-art results across standard video person retrieval benchmarks, and a thorough ablation study shows the effectiveness of the proposed units.
Cross-Correlated Attention Networks for Person Re-Identification
Jun 17, 2020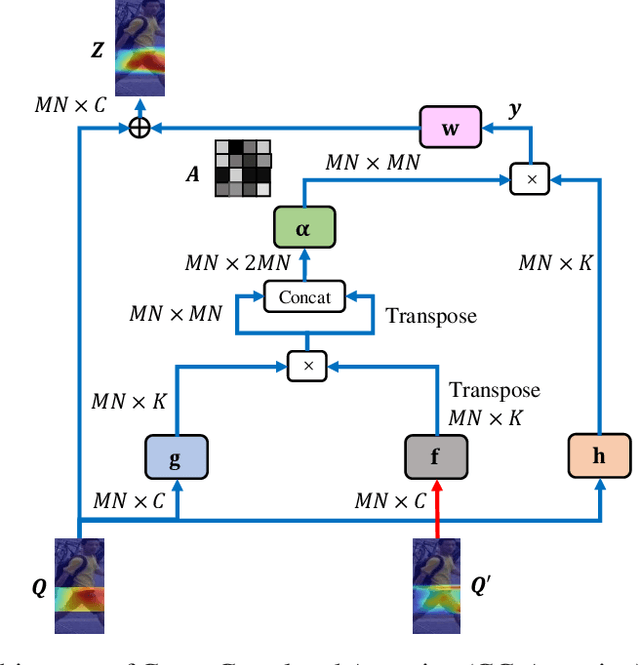

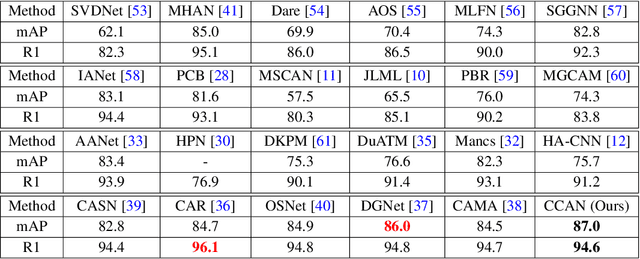
Deep neural networks need to make robust inference in the presence of occlusion, background clutter, pose and viewpoint variations -- to name a few -- when the task of person re-identification is considered. Attention mechanisms have recently proven to be successful in handling the aforementioned challenges to some degree. However previous designs fail to capture inherent inter-dependencies between the attended features; leading to restricted interactions between the attention blocks. In this paper, we propose a new attention module called Cross-Correlated Attention (CCA); which aims to overcome such limitations by maximizing the information gain between different attended regions. Moreover, we also propose a novel deep network that makes use of different attention mechanisms to learn robust and discriminative representations of person images. The resulting model is called the Cross-Correlated Attention Network (CCAN). Extensive experiments demonstrate that the CCAN comfortably outperforms current state-of-the-art algorithms by a tangible margin.
* Accepted by Image and Vision Computing