 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Attention-guided Adaptive Subsampling
Oct 14, 2025Although deep neural networks have provided impressive gains in performance, these improvements often come at the cost of increased computational complexity and expense. In many cases, such as 3D volume or video classification tasks, not all slices or frames are necessary due to inherent redundancies. To address this issue, we propose a novel learnable subsampling framework that can be integrated into any neural network architecture. Subsampling, being a nondifferentiable operation, poses significant challenges for direct adaptation into deep learning models. While some works, have proposed solutions using the Gumbel-max trick to overcome the problem of non-differentiability, they fall short in a crucial aspect: they are only task-adaptive and not inputadaptive. Once the sampling mechanism is learned, it remains static and does not adjust to different inputs, making it unsuitable for real-world applications. To this end, we propose an attention-guided sampling module that adapts to inputs even during inference. This dynamic adaptation results in performance gains and reduces complexity in deep neural network models. We demonstrate the effectiveness of our method on 3D medical imaging datasets from MedMNIST3D as well as two ultrasound video datasets for classification tasks, one of them being a challenging in-house dataset collected under real-world clinical conditions.
Learning from Noisy Labels with Contrastive Co-Transformer
Mar 04, 2025



Deep learning with noisy labels is an interesting challenge in weakly supervised learning. Despite their significant learning capacity, CNNs have a tendency to overfit in the presence of samples with noisy labels. Alleviating this issue, the well known Co-Training framework is used as a fundamental basis for our work. In this paper, we introduce a Contrastive Co-Transformer framework, which is simple and fast, yet able to improve the performance by a large margin compared to the state-of-the-art approaches. We argue the robustness of transformers when dealing with label noise. Our Contrastive Co-Transformer approach is able to utilize all samples in the dataset, irrespective of whether they are clean or noisy. Transformers are trained by a combination of contrastive loss and classification loss. Extensive experimental results on corrupted data from six standard benchmark datasets including Clothing1M, demonstrate that our Contrastive Co-Transformer is superior to existing state-of-the-art methods.
Vision-Based Power Line Cables and Pylons Detection for Low Flying Aircrafts
Jul 19, 2024



Power lines are dangerous for low-flying aircrafts, especially in low-visibility conditions. Thus, a vision-based system able to analyze the aircraft's surroundings and to provide the pilots with a "second pair of eyes" can contribute to enhancing their safety. To this end, we have developed a deep learning approach to jointly detect power line cables and pylons from images captured at distances of several hundred meters by aircraft-mounted cameras. In doing so, we have combined a modern convolutional architecture with transfer learning and a loss function adapted to curvilinear structure delineation. We use a single network for both detection tasks and demonstrated its performance on two benchmarking datasets. We have integrated it within an onboard system and run it in flight, and have demonstrated with our experiments that it outperforms the prior distant cable detection method on both datasets, while also successfully detecting pylons, given their annotations are available for the data.
FORML: A Riemannian Hessian-free Method for Meta-learning with Orthogonality Constraint
Feb 28, 2024



Meta-learning problem is usually formulated as a bi-level optimization in which the task-specific and the meta-parameters are updated in the inner and outer loops of optimization, respectively. However, performing the optimization in the Riemannian space, where the parameters and meta-parameters are located on Riemannian manifolds is computationally intensive. Unlike the Euclidean methods, the Riemannian backpropagation needs computing the second-order derivatives that include backward computations through the Riemannian operators such as retraction and orthogonal projection. This paper introduces a Hessian-free approach that uses a first-order approximation of derivatives on the Stiefel manifold. Our method significantly reduces the computational load and memory footprint. We show how using a Stiefel fully-connected layer that enforces orthogonality constraint on the parameters of the last classification layer as the head of the backbone network, strengthens the representation reuse of the gradient-based meta-learning methods. Our experimental results across various few-shot learning datasets, demonstrate the superiority of our proposed method compared to the state-of-the-art methods, especially MAML, its Euclidean counterpart.
Occlusion Resilient 3D Human Pose Estimation
Feb 16, 2024



Occlusions remain one of the key challenges in 3D body pose estimation from single-camera video sequences. Temporal consistency has been extensively used to mitigate their impact but the existing algorithms in the literature do not explicitly model them. Here, we apply this by representing the deforming body as a spatio-temporal graph. We then introduce a refinement network that performs graph convolutions over this graph to output 3D poses. To ensure robustness to occlusions, we train this network with a set of binary masks that we use to disable some of the edges as in drop-out techniques. In effect, we simulate the fact that some joints can be hidden for periods of time and train the network to be immune to that. We demonstrate the effectiveness of this approach compared to state-of-the-art techniques that infer poses from single-camera sequences.
Learning Deep Optimal Embeddings with Sinkhorn Divergences
Sep 14, 2022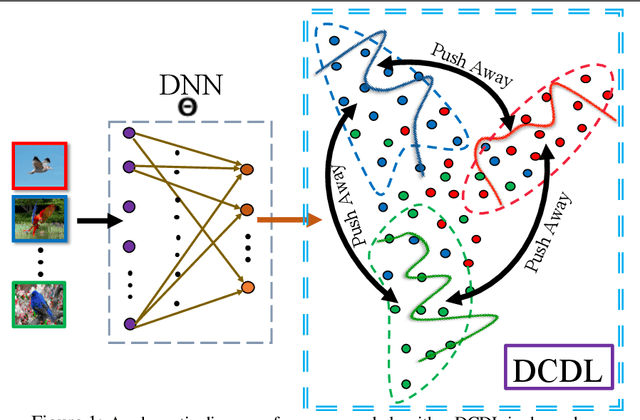
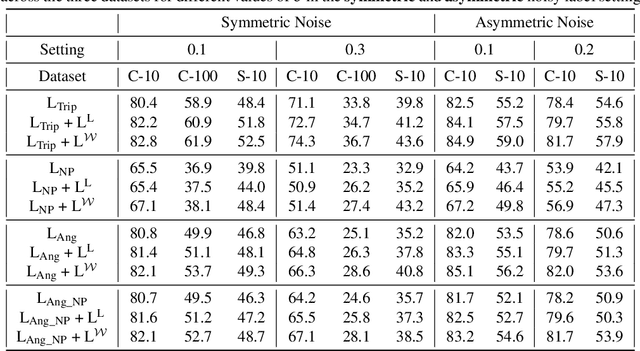
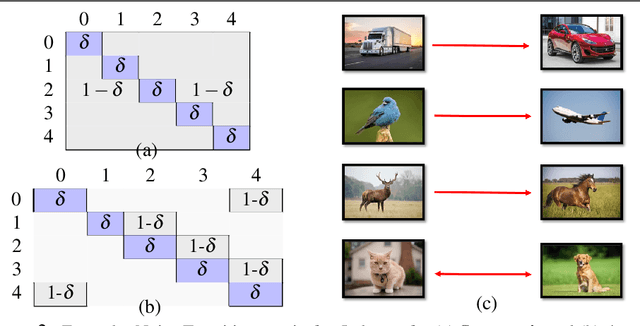
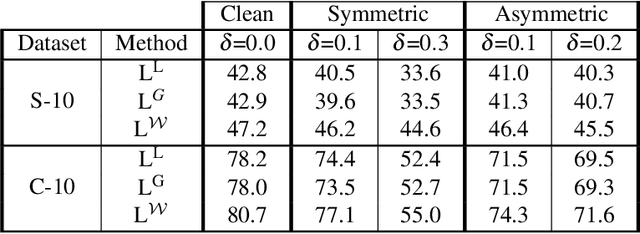
Deep Metric Learning algorithms aim to learn an efficient embedding space to preserve the similarity relationships among the input data. Whilst these algorithms have achieved significant performance gains across a wide plethora of tasks, they have also failed to consider and increase comprehensive similarity constraints; thus learning a sub-optimal metric in the embedding space. Moreover, up until now; there have been few studies with respect to their performance in the presence of noisy labels. Here, we address the concern of learning a discriminative deep embedding space by designing a novel, yet effective Deep Class-wise Discrepancy Loss (DCDL) function that segregates the underlying similarity distributions (thus introducing class-wise discrepancy) of the embedding points between each and every class. Our empirical results across three standard image classification datasets and two fine-grained image recognition datasets in the presence and absence of noise clearly demonstrate the need for incorporating such class-wise similarity relationships along with traditional algorithms while learning a discriminative embedding space.
On Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation
Mar 29, 2022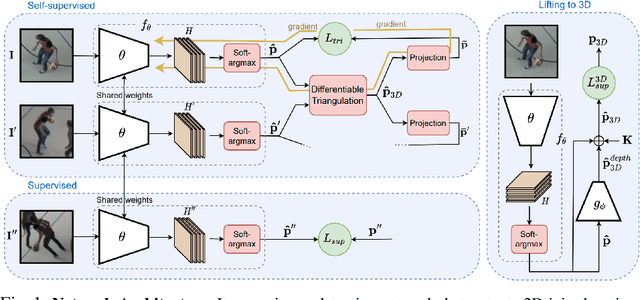

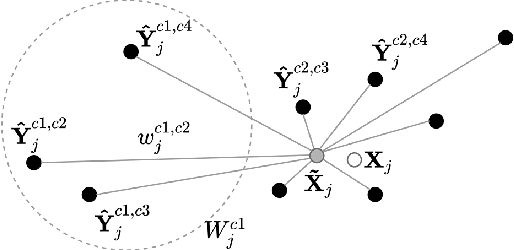
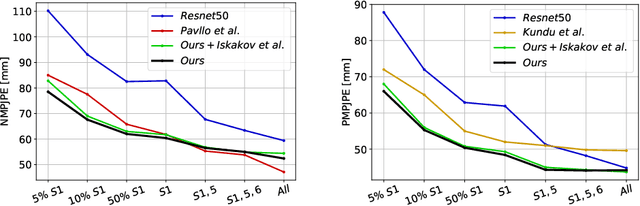
Supervised approaches to 3D pose estimation from single images are remarkably effective when labeled data is abundant. Therefore, much of the recent attention has shifted towards semi and (or) weakly supervised learning. Generating an effective form of supervision with little annotations still poses major challenges in crowded scenes. However, since it is easy to observe a scene from multiple cameras, we propose to impose multi-view geometrical constraints by means of a differentiable triangulation and to use it as form of self-supervision during training when no labels are available. We therefore train a 2D pose estimator in such a way that its predictions correspond to the re-projection of the triangulated 3D one and train an auxiliary network on them to produce the final 3D poses. We complement the triangulation with a weighting mechanism that nullify the impact of noisy predictions caused by self-occlusion or occlusion from other subjects. Our experimental results on Human3.6M and MPI-INF-3DHP substantiate the significance of our weighting strategy where we obtain state-of-the-art results in the semi and weakly supervised learning setup. We also contribute a new multi-player sports dataset that features occlusion, and show the effectiveness of our algorithm over baseline triangulation methods.
Semantic-aware Knowledge Distillation for Few-Shot Class-Incremental Learning
Mar 31, 2021



Few-shot class incremental learning (FSCIL) portrays the problem of learning new concepts gradually, where only a few examples per concept are available to the learner. Due to the limited number of examples for training, the techniques developed for standard incremental learning cannot be applied verbatim to FSCIL. In this work, we introduce a distillation algorithm to address the problem of FSCIL and propose to make use of semantic information during training. To this end, we make use of word embeddings as semantic information which is cheap to obtain and which facilitate the distillation process. Furthermore, we propose a method based on an attention mechanism on multiple parallel embeddings of visual data to align visual and semantic vectors, which reduces issues related to catastrophic forgetting. Via experiments on MiniImageNet, CUB200, and CIFAR100 dataset, we establish new state-of-the-art results by outperforming existing approaches.
Cross-Correlated Attention Networks for Person Re-Identification
Jun 17, 2020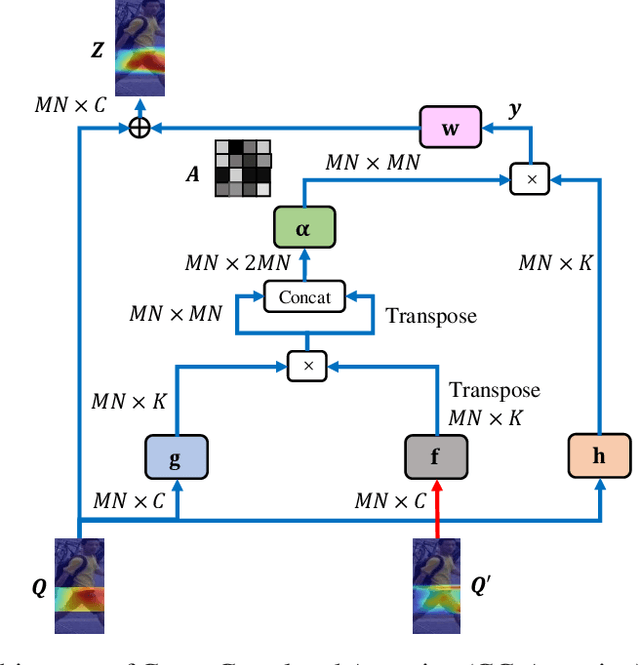
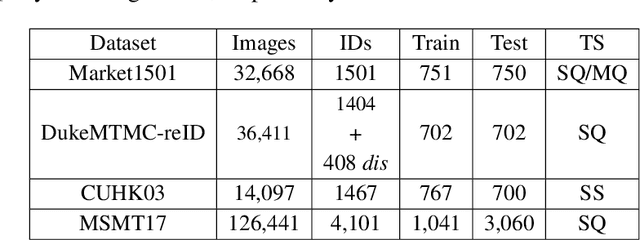

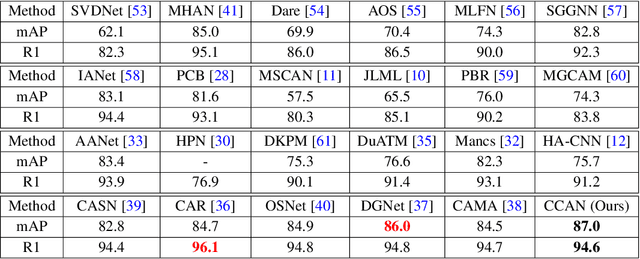
Deep neural networks need to make robust inference in the presence of occlusion, background clutter, pose and viewpoint variations -- to name a few -- when the task of person re-identification is considered. Attention mechanisms have recently proven to be successful in handling the aforementioned challenges to some degree. However previous designs fail to capture inherent inter-dependencies between the attended features; leading to restricted interactions between the attention blocks. In this paper, we propose a new attention module called Cross-Correlated Attention (CCA); which aims to overcome such limitations by maximizing the information gain between different attended regions. Moreover, we also propose a novel deep network that makes use of different attention mechanisms to learn robust and discriminative representations of person images. The resulting model is called the Cross-Correlated Attention Network (CCAN). Extensive experiments demonstrate that the CCAN comfortably outperforms current state-of-the-art algorithms by a tangible margin.
* Accepted by Image and Vision Computing