 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace2Scene: Using Facial Degradation as an Oracle for Diffusion-Based Scene Restoration
Mar 17, 2026Recent advances in image restoration have enabled high-fidelity recovery of faces from degraded inputs using reference-based face restoration models (Ref-FR). However, such methods focus solely on facial regions, neglecting degradation across the full scene, including body and background, which limits practical usability. Meanwhile, full-scene restorers often ignore degradation cues entirely, leading to underdetermined predictions and visual artifacts. In this work, we propose Face2Scene, a two-stage restoration framework that leverages the face as a perceptual oracle to estimate degradation and guide the restoration of the entire image. Given a degraded image and one or more identity references, we first apply a Ref-FR model to reconstruct high-quality facial details. From the restored-degraded face pair, we extract a face-derived degradation code that captures degradation attributes (e.g., noise, blur, compression), which is then transformed into multi-scale degradation-aware tokens. These tokens condition a diffusion model to restore the full scene in a single step, including the body and background. Extensive experiments demonstrate the superior effectiveness of the proposed method compared to state-of-the-art methods.
Towards Unsupervised Blind Face Restoration using Diffusion Prior
Oct 06, 2024Blind face restoration methods have shown remarkable performance, particularly when trained on large-scale synthetic datasets with supervised learning. These datasets are often generated by simulating low-quality face images with a handcrafted image degradation pipeline. The models trained on such synthetic degradations, however, cannot deal with inputs of unseen degradations. In this paper, we address this issue by using only a set of input images, with unknown degradations and without ground truth targets, to fine-tune a restoration model that learns to map them to clean and contextually consistent outputs. We utilize a pre-trained diffusion model as a generative prior through which we generate high quality images from the natural image distribution while maintaining the input image content through consistency constraints. These generated images are then used as pseudo targets to fine-tune a pre-trained restoration model. Unlike many recent approaches that employ diffusion models at test time, we only do so during training and thus maintain an efficient inference-time performance. Extensive experiments show that the proposed approach can consistently improve the perceptual quality of pre-trained blind face restoration models while maintaining great consistency with the input contents. Our best model also achieves the state-of-the-art results on both synthetic and real-world datasets.
Occlusion Resilient 3D Human Pose Estimation
Feb 16, 2024



Occlusions remain one of the key challenges in 3D body pose estimation from single-camera video sequences. Temporal consistency has been extensively used to mitigate their impact but the existing algorithms in the literature do not explicitly model them. Here, we apply this by representing the deforming body as a spatio-temporal graph. We then introduce a refinement network that performs graph convolutions over this graph to output 3D poses. To ensure robustness to occlusions, we train this network with a set of binary masks that we use to disable some of the edges as in drop-out techniques. In effect, we simulate the fact that some joints can be hidden for periods of time and train the network to be immune to that. We demonstrate the effectiveness of this approach compared to state-of-the-art techniques that infer poses from single-camera sequences.
AttEntropy: Segmenting Unknown Objects in Complex Scenes using the Spatial Attention Entropy of Semantic Segmentation Transformers
Dec 29, 2022Vision transformers have emerged as powerful tools for many computer vision tasks. It has been shown that their features and class tokens can be used for salient object segmentation. However, the properties of segmentation transformers remain largely unstudied. In this work we conduct an in-depth study of the spatial attentions of different backbone layers of semantic segmentation transformers and uncover interesting properties. The spatial attentions of a patch intersecting with an object tend to concentrate within the object, whereas the attentions of larger, more uniform image areas rather follow a diffusive behavior. In other words, vision transformers trained to segment a fixed set of object classes generalize to objects well beyond this set. We exploit this by extracting heatmaps that can be used to segment unknown objects within diverse backgrounds, such as obstacles in traffic scenes. Our method is training-free and its computational overhead negligible. We use off-the-shelf transformers trained for street-scene segmentation to process other scene types.
Visual Question Answering From Another Perspective: CLEVR Mental Rotation Tests
Dec 03, 2022



Different types of mental rotation tests have been used extensively in psychology to understand human visual reasoning and perception. Understanding what an object or visual scene would look like from another viewpoint is a challenging problem that is made even harder if it must be performed from a single image. We explore a controlled setting whereby questions are posed about the properties of a scene if that scene was observed from another viewpoint. To do this we have created a new version of the CLEVR dataset that we call CLEVR Mental Rotation Tests (CLEVR-MRT). Using CLEVR-MRT we examine standard methods, show how they fall short, then explore novel neural architectures that involve inferring volumetric representations of a scene. These volumes can be manipulated via camera-conditioned transformations to answer the question. We examine the efficacy of different model variants through rigorous ablations and demonstrate the efficacy of volumetric representations.
Unsupervised 3D Keypoint Estimation with Multi-View Geometry
Nov 23, 2022Given enough annotated training data, 3D human pose estimation models can achieve high accuracy. However, annotations are not always available, especially for people performing unusual activities. In this paper, we propose an algorithm that learns to detect 3D keypoints on human bodies from multiple-views without any supervision other than the constraints multiple-view geometry provides. To ensure that the estimated 3D keypoints are meaningful, they are re-projected to each view to estimate the person's mask that the model itself has initially estimated. Our approach outperforms other state-of-the-art unsupervised 3D human pose estimation methods on the Human3.6M and MPI-INF-3DHP benchmark datasets.
Perspective Aware Road Obstacle Detection
Oct 04, 2022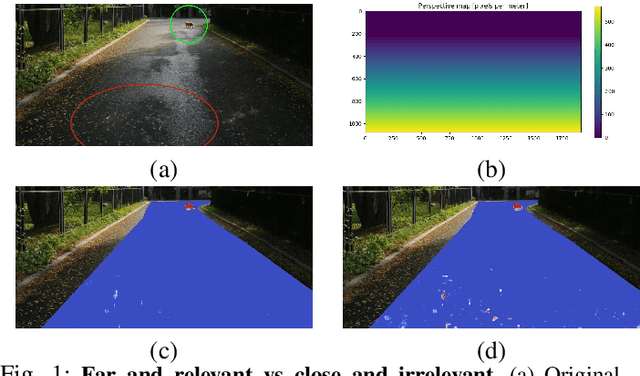

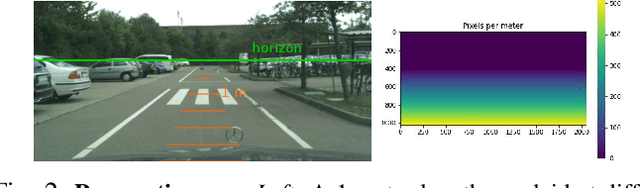

While road obstacle detection techniques have become increasingly effective, they typically ignore the fact that, in practice, the apparent size of the obstacles decreases as their distance to the vehicle increases. In this paper, we account for this by computing a scale map encoding the apparent size of a hypothetical object at every image location. We then leverage this perspective map to (i) generate training data by injecting synthetic objects onto the road in a more realistic fashion than existing methods; and (ii) incorporate perspective information in the decoding part of the detection network to guide the obstacle detector. Our results on standard benchmarks show that, together, these two strategies significantly boost the obstacle detection performance, allowing our approach to consistently outperform state-of-the-art methods in terms of instance-level obstacle detection.
On Triangulation as a Form of Self-Supervision for 3D Human Pose Estimation
Mar 29, 2022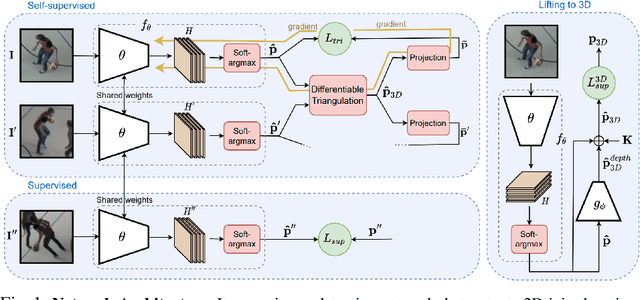

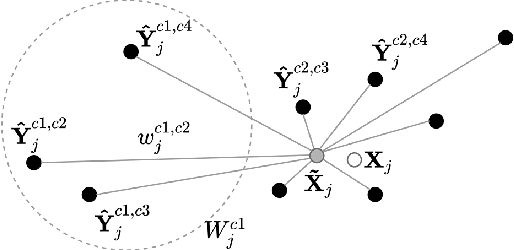
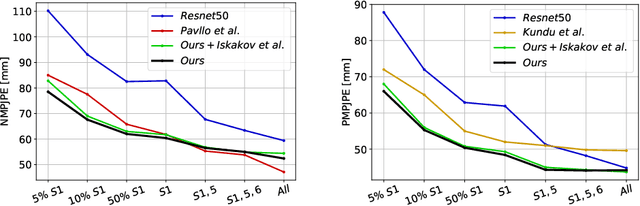
Supervised approaches to 3D pose estimation from single images are remarkably effective when labeled data is abundant. Therefore, much of the recent attention has shifted towards semi and (or) weakly supervised learning. Generating an effective form of supervision with little annotations still poses major challenges in crowded scenes. However, since it is easy to observe a scene from multiple cameras, we propose to impose multi-view geometrical constraints by means of a differentiable triangulation and to use it as form of self-supervision during training when no labels are available. We therefore train a 2D pose estimator in such a way that its predictions correspond to the re-projection of the triangulated 3D one and train an auxiliary network on them to produce the final 3D poses. We complement the triangulation with a weighting mechanism that nullify the impact of noisy predictions caused by self-occlusion or occlusion from other subjects. Our experimental results on Human3.6M and MPI-INF-3DHP substantiate the significance of our weighting strategy where we obtain state-of-the-art results in the semi and weakly supervised learning setup. We also contribute a new multi-player sports dataset that features occlusion, and show the effectiveness of our algorithm over baseline triangulation methods.
Overcoming the Domain Gap in Neural Action Representations
Dec 23, 2021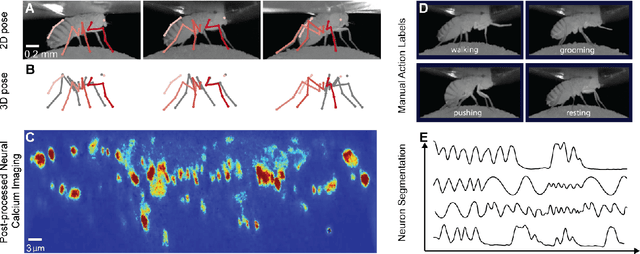
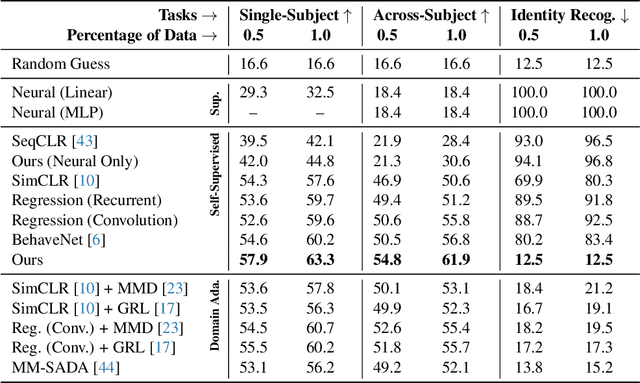
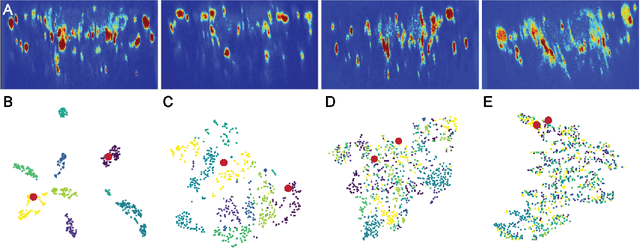
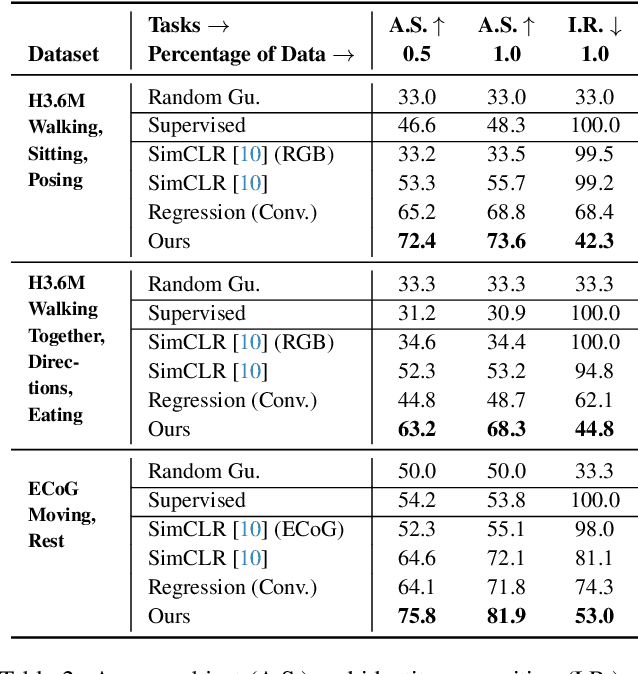
Relating animal behaviors to brain activity is a fundamental goal in neuroscience, with practical applications in building robust brain-machine interfaces. However, the domain gap between individuals is a major issue that prevents the training of general models that work on unlabeled subjects. Since 3D pose data can now be reliably extracted from multi-view video sequences without manual intervention, we propose to use it to guide the encoding of neural action representations together with a set of neural and behavioral augmentations exploiting the properties of microscopy imaging. To reduce the domain gap, during training, we swap neural and behavioral data across animals that seem to be performing similar actions. To demonstrate this, we test our methods on three very different multimodal datasets; one that features flies and their neural activity, one that contains human neural Electrocorticography (ECoG) data, and lastly the RGB video data of human activities from different viewpoints.
Adversarial Parametric Pose Prior
Dec 08, 2021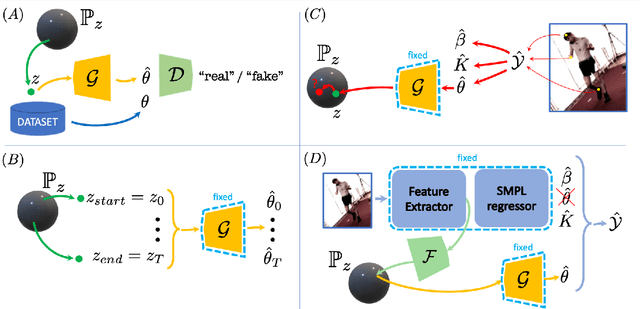
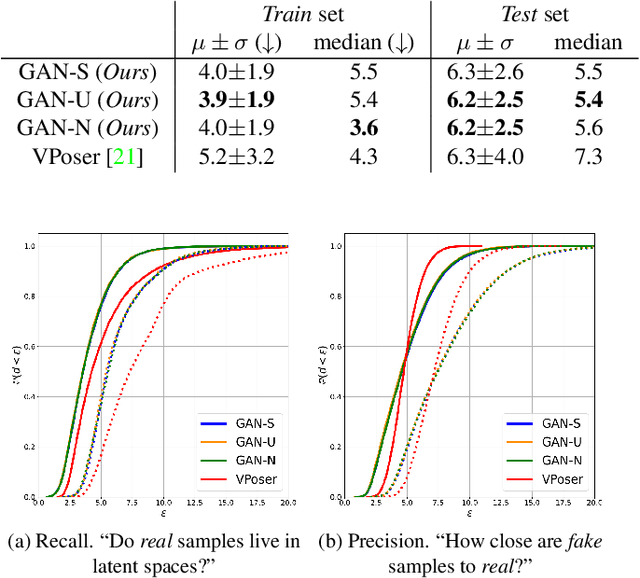
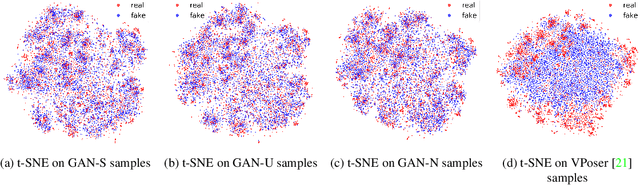
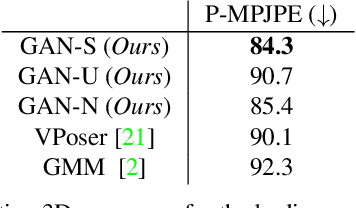
The Skinned Multi-Person Linear (SMPL) model can represent a human body by mapping pose and shape parameters to body meshes. This has been shown to facilitate inferring 3D human pose and shape from images via different learning models. However, not all pose and shape parameter values yield physically-plausible or even realistic body meshes. In other words, SMPL is under-constrained and may thus lead to invalid results when used to reconstruct humans from images, either by directly optimizing its parameters, or by learning a mapping from the image to these parameters. In this paper, we therefore learn a prior that restricts the SMPL parameters to values that produce realistic poses via adversarial training. We show that our learned prior covers the diversity of the real-data distribution, facilitates optimization for 3D reconstruction from 2D keypoints, and yields better pose estimates when used for regression from images. We found that the prior based on spherical distribution gets the best results. Furthermore, in all these tasks, it outperforms the state-of-the-art VAE-based approach to constraining the SMPL parameters.