 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Flow Dynamics of Test Risk and its Exact Solution for Weak Features
Feb 12, 2024



We investigate the test risk of continuous-time stochastic gradient flow dynamics in learning theory. Using a path integral formulation we provide, in the regime of a small learning rate, a general formula for computing the difference between test risk curves of pure gradient and stochastic gradient flows. We apply the general theory to a simple model of weak features, which displays the double descent phenomenon, and explicitly compute the corrections brought about by the added stochastic term in the dynamics, as a function of time and model parameters. The analytical results are compared to simulations of discrete-time stochastic gradient descent and show good agreement.
Adversarial Parametric Pose Prior
Dec 08, 2021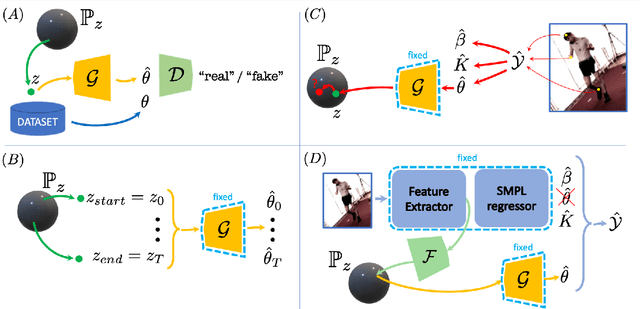
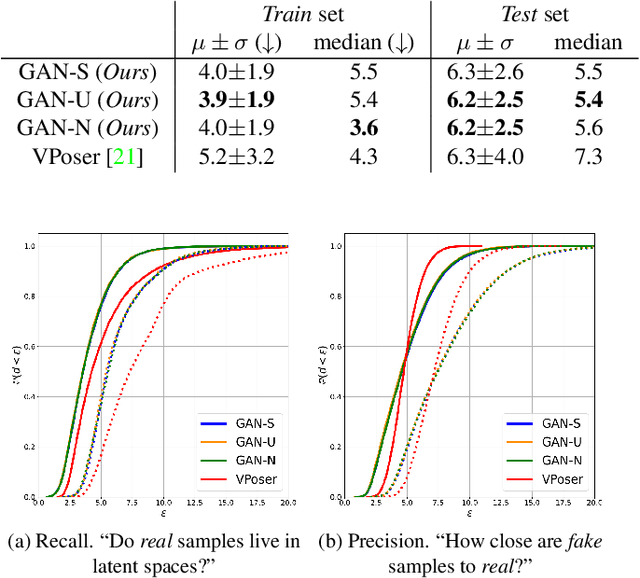
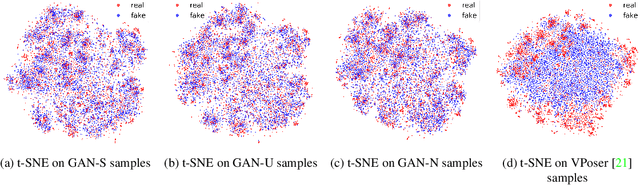
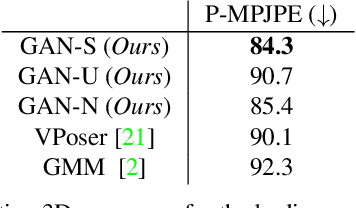
The Skinned Multi-Person Linear (SMPL) model can represent a human body by mapping pose and shape parameters to body meshes. This has been shown to facilitate inferring 3D human pose and shape from images via different learning models. However, not all pose and shape parameter values yield physically-plausible or even realistic body meshes. In other words, SMPL is under-constrained and may thus lead to invalid results when used to reconstruct humans from images, either by directly optimizing its parameters, or by learning a mapping from the image to these parameters. In this paper, we therefore learn a prior that restricts the SMPL parameters to values that produce realistic poses via adversarial training. We show that our learned prior covers the diversity of the real-data distribution, facilitates optimization for 3D reconstruction from 2D keypoints, and yields better pose estimates when used for regression from images. We found that the prior based on spherical distribution gets the best results. Furthermore, in all these tasks, it outperforms the state-of-the-art VAE-based approach to constraining the SMPL parameters.
Resolution-robust Large Mask Inpainting with Fourier Convolutions
Sep 15, 2021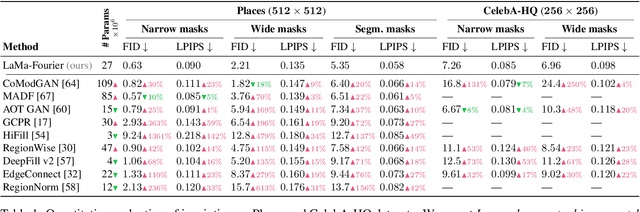
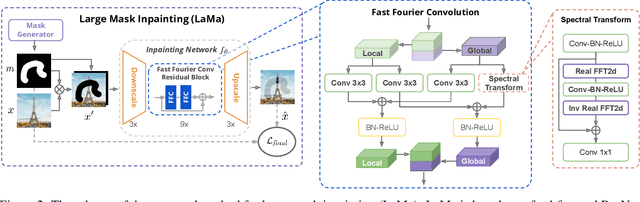
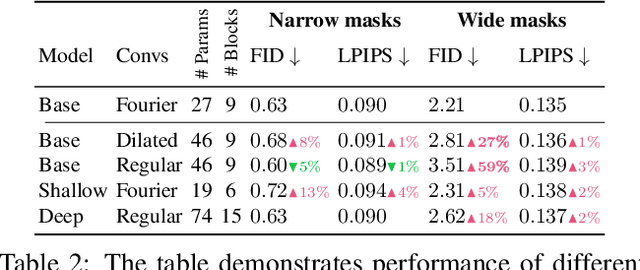

Modern image inpainting systems, despite the significant progress, often struggle with large missing areas, complex geometric structures, and high-resolution images. We find that one of the main reasons for that is the lack of an effective receptive field in both the inpainting network and the loss function. To alleviate this issue, we propose a new method called large mask inpainting (LaMa). LaMa is based on i) a new inpainting network architecture that uses fast Fourier convolutions, which have the image-wide receptive field; ii) a high receptive field perceptual loss; and iii) large training masks, which unlocks the potential of the first two components. Our inpainting network improves the state-of-the-art across a range of datasets and achieves excellent performance even in challenging scenarios, e.g. completion of periodic structures. Our model generalizes surprisingly well to resolutions that are higher than those seen at train time, and achieves this at lower parameter&compute costs than the competitive baselines. The code is available at https://github.com/saic-mdal/lama.