 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoCar: Localization-Aware Evaluation of In-Vehicle Assistants through Fine-Grained Sociolinguistic Control
May 20, 2026While Large Language Models (LLMs) are increasingly integrated into in-vehicle conversational systems, identifying the optimal model remains challenging due to the lack of domain-specific evaluation standards tailored to real-world deployment requirements. In this paper, we propose a novel evaluation framework for in-vehicle assistants, with a particular focus on Korean-language localization. Our empirical analysis reveals notable patterns in model behavior. First, fine-grained Korean honorific control remains unstable in current LLMs, indicating that precise speech-level realization must be explicitly evaluated in localization settings. Second, models exhibit weaker performance in strategic conversational metrics like clarification and proactivity. Our analysis suggests this stems from the inherent subjective complexity of these tasks, where our framework adopts a conservative evaluation stance to prioritize reliability. Together, our findings underscore that automotive AI must move beyond general competence toward precise linguistic tailoring and reliable, safety-oriented interaction management.
Are they lovers or friends? Evaluating LLMs' Social Reasoning in English and Korean Dialogues
Oct 21, 2025As large language models (LLMs) are increasingly used in human-AI interactions, their social reasoning capabilities in interpersonal contexts are critical. We introduce SCRIPTS, a 1k-dialogue dataset in English and Korean, sourced from movie scripts. The task involves evaluating models' social reasoning capability to infer the interpersonal relationships (e.g., friends, sisters, lovers) between speakers in each dialogue. Each dialogue is annotated with probabilistic relational labels (Highly Likely, Less Likely, Unlikely) by native (or equivalent) Korean and English speakers from Korea and the U.S. Evaluating nine models on our task, current proprietary LLMs achieve around 75-80% on the English dataset, whereas their performance on Korean drops to 58-69%. More strikingly, models select Unlikely relationships in 10-25% of their responses. Furthermore, we find that thinking models and chain-of-thought prompting, effective for general reasoning, provide minimal benefits for social reasoning and occasionally amplify social biases. Our findings reveal significant limitations in current LLMs' social reasoning capabilities, highlighting the need for efforts to develop socially-aware language models.
BLEnD: A Benchmark for LLMs on Everyday Knowledge in Diverse Cultures and Languages
Jun 14, 2024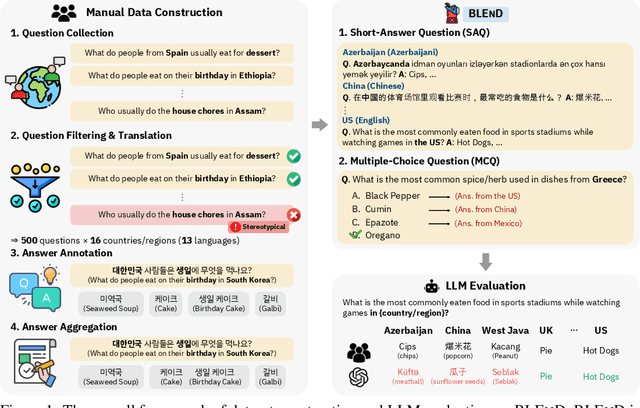
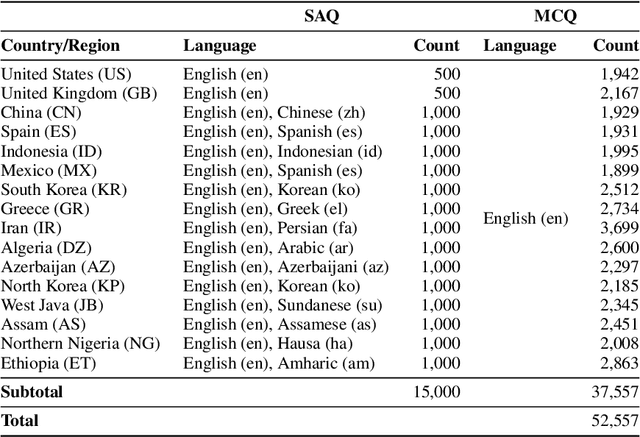
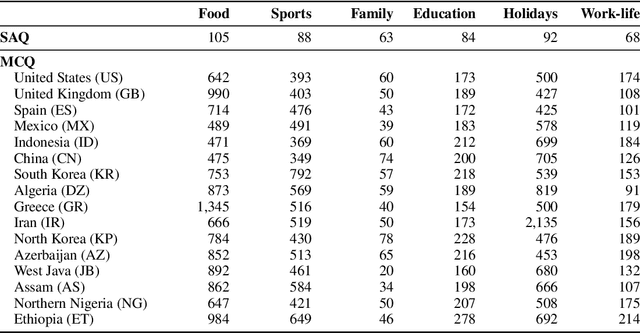
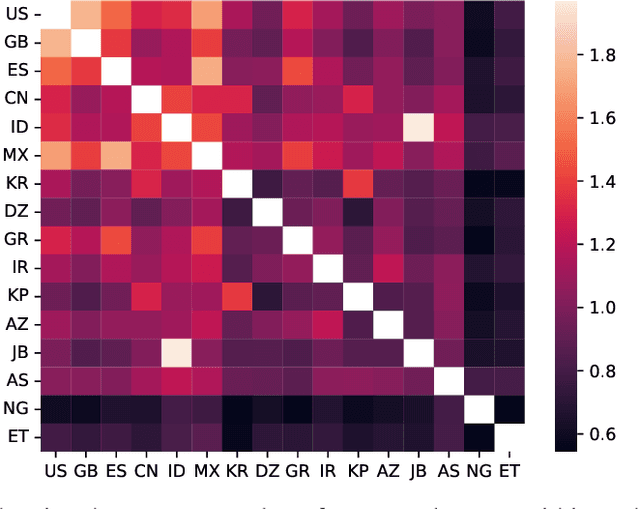
Large language models (LLMs) often lack culture-specific knowledge of daily life, especially across diverse regions and non-English languages. Existing benchmarks for evaluating LLMs' cultural sensitivities are limited to a single language or collected from online sources such as Wikipedia, which do not reflect the mundane everyday lifestyles of diverse regions. That is, information about the food people eat for their birthday celebrations, spices they typically use, musical instruments youngsters play, or the sports they practice in school is common cultural knowledge but uncommon in easily collected online sources, especially for underrepresented cultures. To address this issue, we introduce BLEnD, a hand-crafted benchmark designed to evaluate LLMs' everyday knowledge across diverse cultures and languages. BLEnD comprises 52.6k question-answer pairs from 16 countries/regions, in 13 different languages, including low-resource ones such as Amharic, Assamese, Azerbaijani, Hausa, and Sundanese. We construct the benchmark to include two formats of questions: short-answer and multiple-choice. We show that LLMs perform better for cultures that are highly represented online, with a maximum 57.34% difference in GPT-4, the best-performing model, in the short-answer format. For cultures represented by mid-to-high-resource languages, LLMs perform better in their local languages, but for cultures represented by low-resource languages, LLMs perform better in English than the local languages. We make our dataset publicly available at: https://github.com/nlee0212/BLEnD.
Hole-robust Wireframe Detection
Nov 30, 2021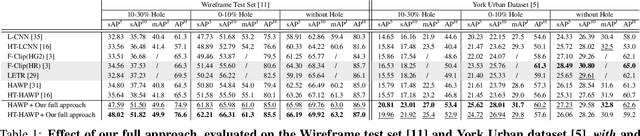
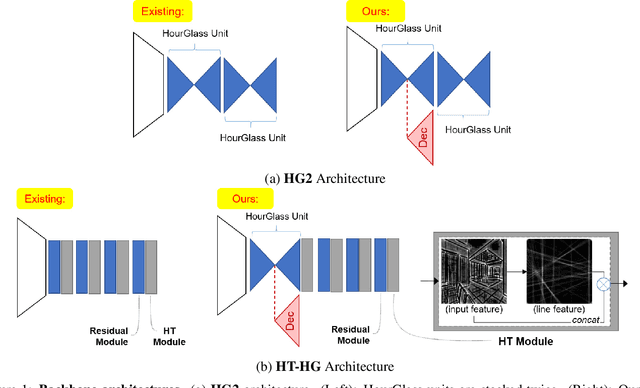
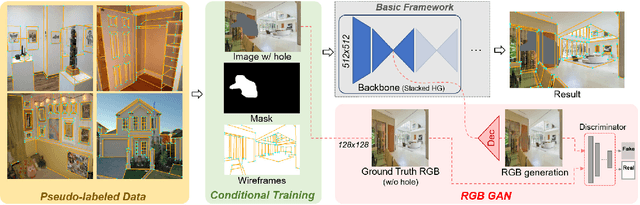
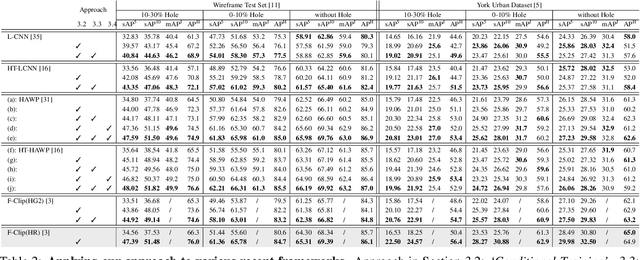
"Wireframe" is a line segment based representation designed to well capture large-scale visual properties of regular, structural shaped man-made scenes surrounding us. Unlike the wireframes, conventional edges or line segments focus on all visible edges and lines without particularly distinguishing which of them are more salient to man-made structural information. Existing wireframe detection models rely on supervising the annotated data but do not explicitly pay attention to understand how to compose the structural shapes of the scene. In addition, we often face that many foreground objects occluding the background scene interfere with proper inference of the full scene structure behind them. To resolve these problems, we first time in the field, propose new conditional data generation and training that help the model understand how to ignore occlusion indicated by holes, such as foreground object regions masked out on the image. In addition, we first time combine GAN in the model to let the model better predict underlying scene structure even beyond large holes. We also introduce pseudo labeling to further enlarge the model capacity to overcome small-scale labeled data. We show qualitatively and quantitatively that our approach significantly outperforms previous works unable to handle holes, as well as improves ordinary detection without holes given.
Resolution-robust Large Mask Inpainting with Fourier Convolutions
Sep 15, 2021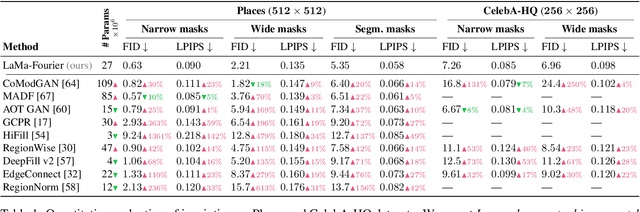
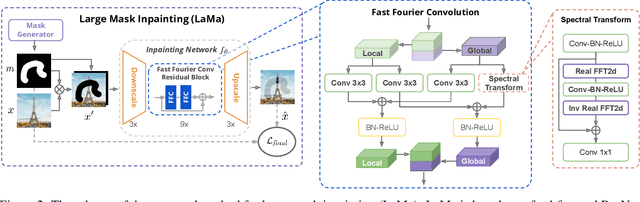
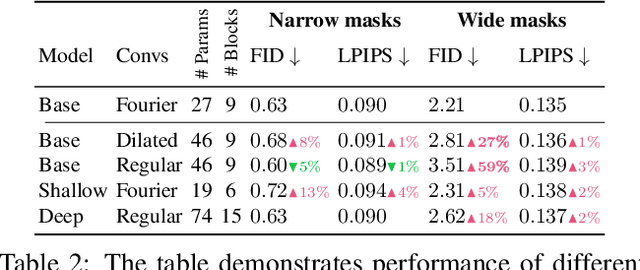

Modern image inpainting systems, despite the significant progress, often struggle with large missing areas, complex geometric structures, and high-resolution images. We find that one of the main reasons for that is the lack of an effective receptive field in both the inpainting network and the loss function. To alleviate this issue, we propose a new method called large mask inpainting (LaMa). LaMa is based on i) a new inpainting network architecture that uses fast Fourier convolutions, which have the image-wide receptive field; ii) a high receptive field perceptual loss; and iii) large training masks, which unlocks the potential of the first two components. Our inpainting network improves the state-of-the-art across a range of datasets and achieves excellent performance even in challenging scenarios, e.g. completion of periodic structures. Our model generalizes surprisingly well to resolutions that are higher than those seen at train time, and achieves this at lower parameter&compute costs than the competitive baselines. The code is available at https://github.com/saic-mdal/lama.