 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Control of Overestimation Bias for Continuous Reinforcement Learning
Oct 26, 2021
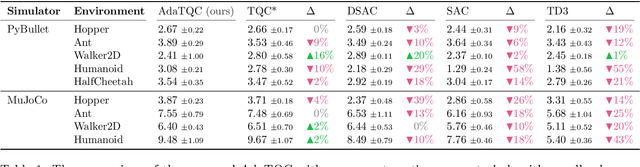
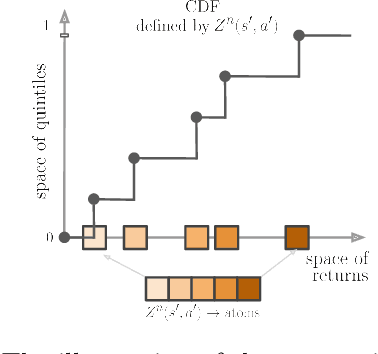

Bias correction techniques are used by most of the high-performing methods for off-policy reinforcement learning. However, these techniques rely on a pre-defined bias correction policy that is either not flexible enough or requires environment-specific tuning of hyperparameters. In this work, we present a simple data-driven approach for guiding bias correction. We demonstrate its effectiveness on the Truncated Quantile Critics -- a state-of-the-art continuous control algorithm. The proposed technique can adjust the bias correction across environments automatically. As a result, it eliminates the need for an extensive hyperparameter search, significantly reducing the actual number of interactions and computation.
Resolution-robust Large Mask Inpainting with Fourier Convolutions
Sep 15, 2021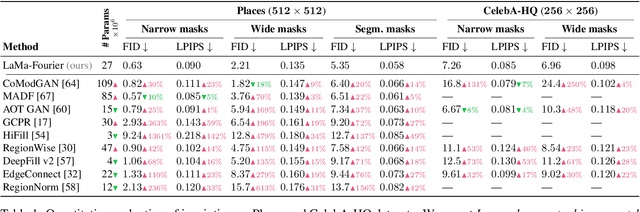
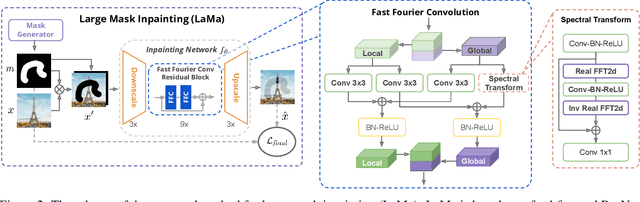
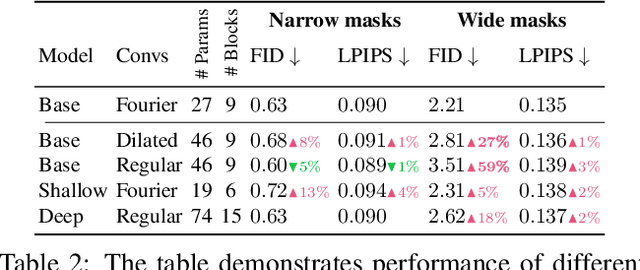

Modern image inpainting systems, despite the significant progress, often struggle with large missing areas, complex geometric structures, and high-resolution images. We find that one of the main reasons for that is the lack of an effective receptive field in both the inpainting network and the loss function. To alleviate this issue, we propose a new method called large mask inpainting (LaMa). LaMa is based on i) a new inpainting network architecture that uses fast Fourier convolutions, which have the image-wide receptive field; ii) a high receptive field perceptual loss; and iii) large training masks, which unlocks the potential of the first two components. Our inpainting network improves the state-of-the-art across a range of datasets and achieves excellent performance even in challenging scenarios, e.g. completion of periodic structures. Our model generalizes surprisingly well to resolutions that are higher than those seen at train time, and achieves this at lower parameter&compute costs than the competitive baselines. The code is available at https://github.com/saic-mdal/lama.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jul 14, 2021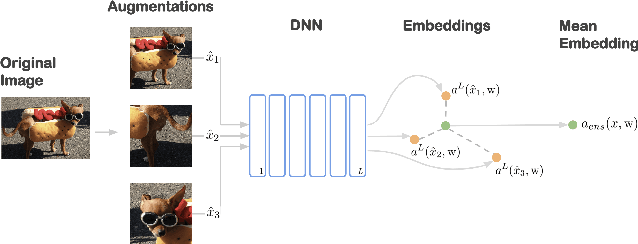
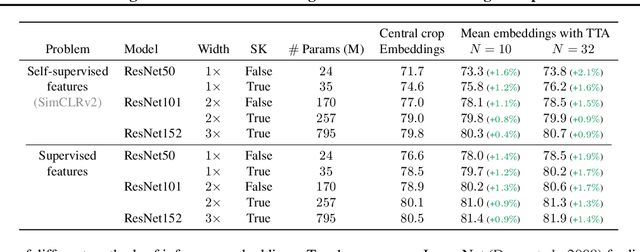
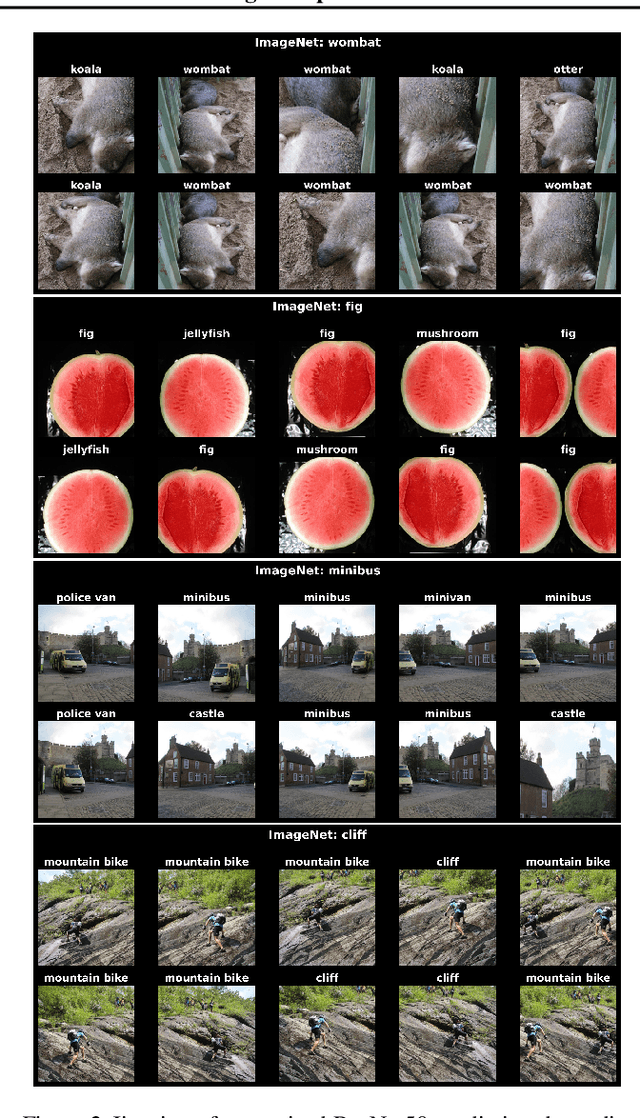
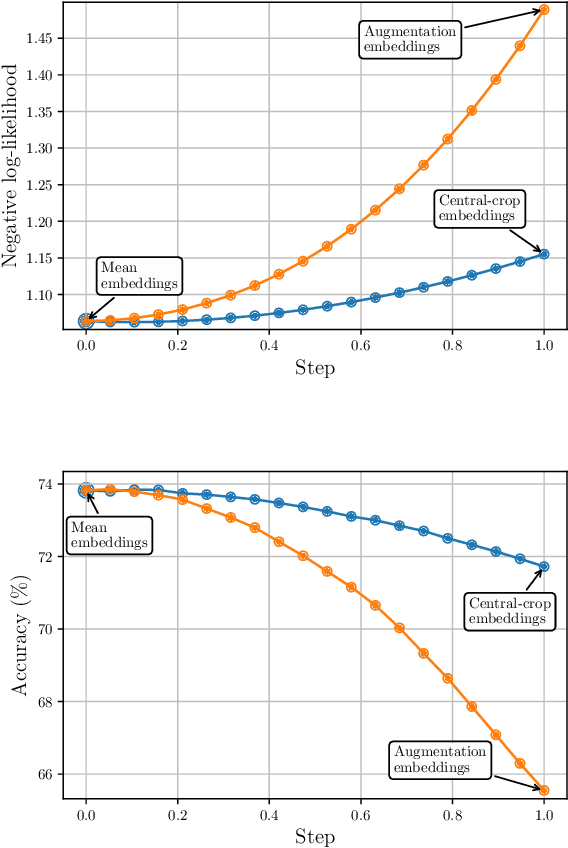
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.
Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation
Feb 21, 2020
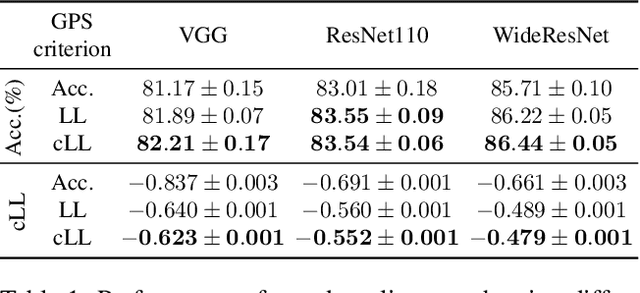
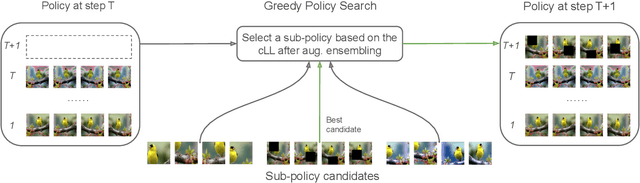

Test-time data augmentation---averaging the predictions of a machine learning model across multiple augmented samples of data---is a widely used technique that improves the predictive performance. While many advanced learnable data augmentation techniques have emerged in recent years, they are focused on the training phase. Such techniques are not necessarily optimal for test-time augmentation and can be outperformed by a policy consisting of simple crops and flips. The primary goal of this paper is to demonstrate that test-time augmentation policies can be successfully learned too. We~introduce \emph{greedy policy search} (GPS), a simple but high-performing method for learning a policy of test-time augmentation. We demonstrate that augmentation policies learned with GPS achieve superior predictive performance on image classification problems, provide better in-domain uncertainty estimation, and improve the robustness to domain shift.
Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning
Feb 15, 2020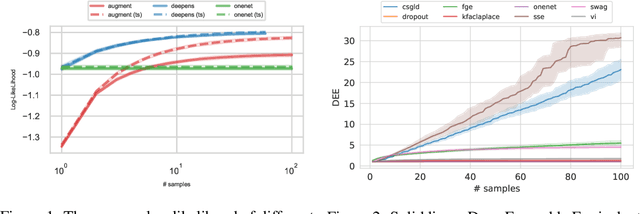


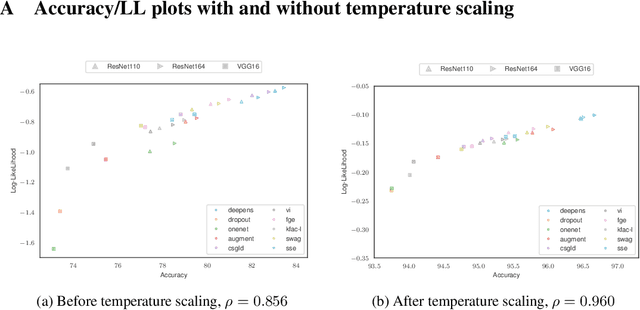
Uncertainty estimation and ensembling methods go hand-in-hand. Uncertainty estimation is one of the main benchmarks for assessment of ensembling performance. At the same time, deep learning ensembles have provided state-of-the-art results in uncertainty estimation. In this work, we focus on in-domain uncertainty for image classification. We explore the standards for its quantification and point out pitfalls of existing metrics. Avoiding these pitfalls, we perform a broad study of different ensembling techniques. To provide more insight in this study, we introduce the deep ensemble equivalent score (DEE) and show that many sophisticated ensembling techniques are equivalent to an ensemble of only few independently trained networks in terms of test performance.
Semi-Conditional Normalizing Flows for Semi-Supervised Learning
May 01, 2019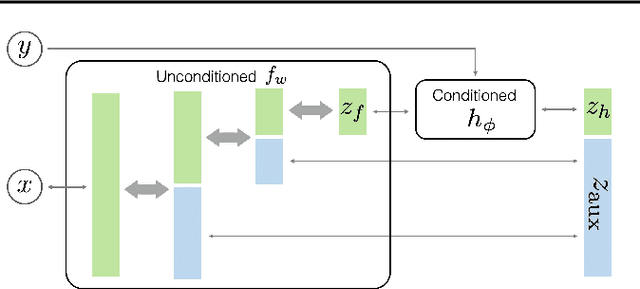
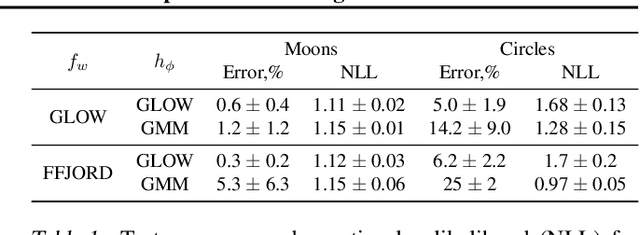
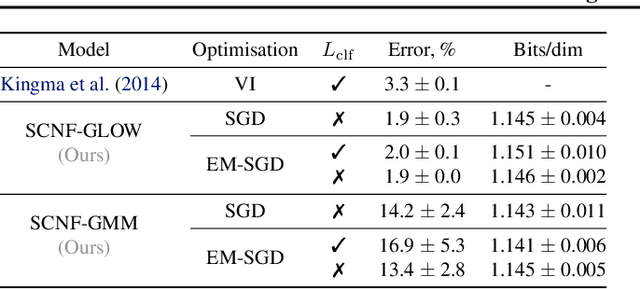
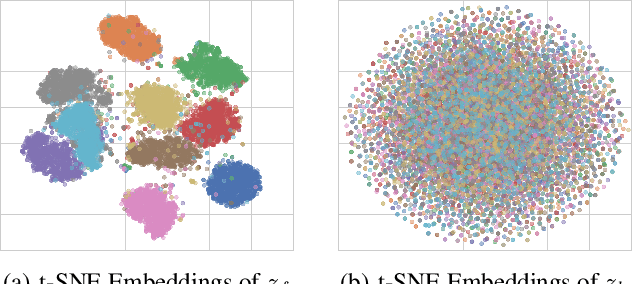
This paper proposes a semi-conditional normalizing flow model for semi-supervised learning. The model uses both labelled and unlabeled data to learn an explicit model of joint distribution over objects and labels. Semi-conditional architecture of the model allows us to efficiently compute a value and gradients of the marginal likelihood for unlabeled objects. The conditional part of the model is based on a proposed conditional coupling layer. We demonstrate performance of the model for semi-supervised classification problem on different datasets. The model outperforms the baseline approach based on variational auto-encoders on MNIST dataset.
The Deep Weight Prior. Modeling a prior distribution for CNNs using generative models
Oct 16, 2018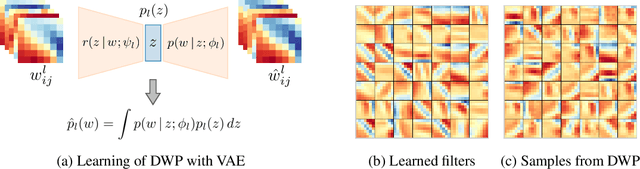
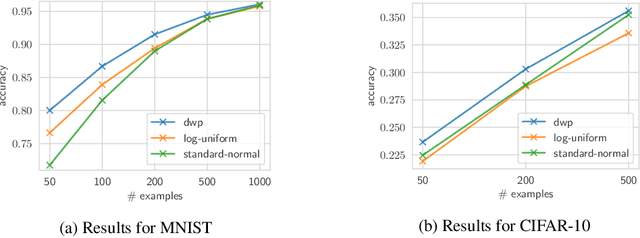

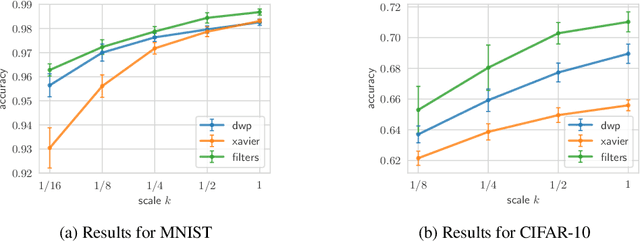
Bayesian inference is known to provide a general framework for incorporating prior knowledge or specific properties into machine learning models via carefully choosing a prior distribution. In this work, we propose a new type of prior distributions for convolutional neural networks, deep weight prior, that in contrast to previously published techniques, favors empirically estimated structure of convolutional filters e.g., spatial correlations of weights. We define deep weight prior as an implicit distribution and propose a method for variational inference with such type of implicit priors. In experiments, we show that deep weight priors can improve the performance of Bayesian neural networks on several problems when training data is limited. Also, we found that initialization of weights of conventional networks with samples from deep weight prior leads to faster training.
Variance Networks: When Expectation Does Not Meet Your Expectations
Jul 04, 2018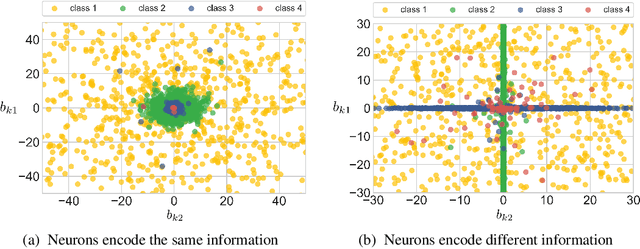

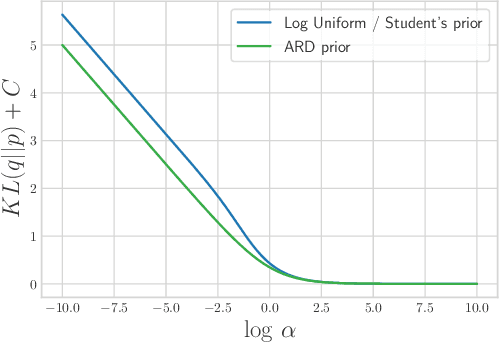
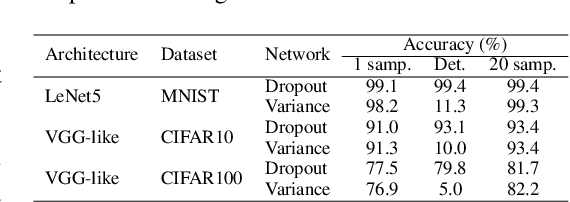
Ordinary stochastic neural networks mostly rely on the expected values of their weights to make predictions, whereas the induced noise is mostly used to capture the uncertainty, prevent overfitting and slightly boost the performance through test-time averaging. In this paper, we introduce variance layers, a different kind of stochastic layers. Each weight of a variance layer follows a zero-mean distribution and is only parameterized by its variance. We show that such layers can learn surprisingly well, can serve as an efficient exploration tool in reinforcement learning tasks and provide a decent defense against adversarial attacks. We also show that a number of conventional Bayesian neural networks naturally converge to such zero-mean posteriors. We observe that in these cases such zero-mean parameterization leads to a much better training objective than conventional parameterizations where the mean is being learned.
Bayesian Incremental Learning for Deep Neural Networks
Mar 27, 2018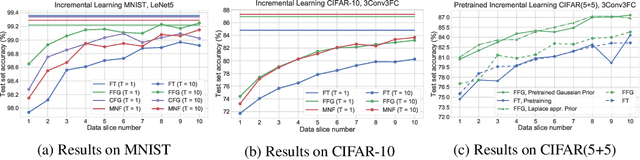
In industrial machine learning pipelines, data often arrive in parts. Particularly in the case of deep neural networks, it may be too expensive to train the model from scratch each time, so one would rather use a previously learned model and the new data to improve performance. However, deep neural networks are prone to getting stuck in a suboptimal solution when trained on only new data as compared to the full dataset. Our work focuses on a continuous learning setup where the task is always the same and new parts of data arrive sequentially. We apply a Bayesian approach to update the posterior approximation with each new piece of data and find this method to outperform the traditional approach in our experiments.
Uncertainty Estimation via Stochastic Batch Normalization
Mar 20, 2018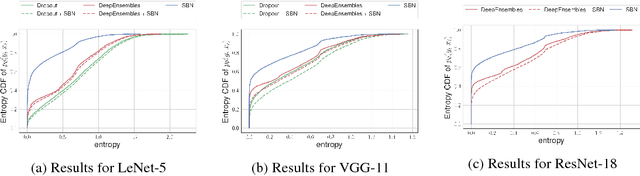
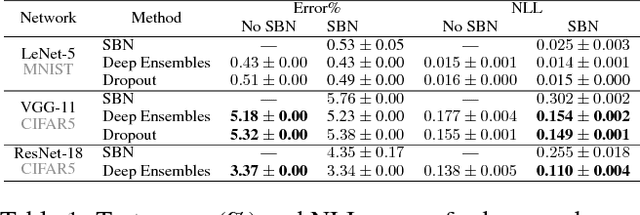
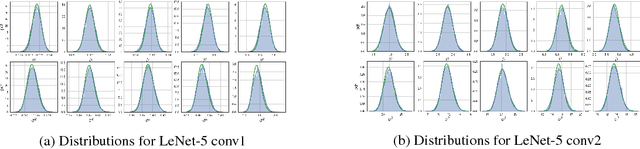
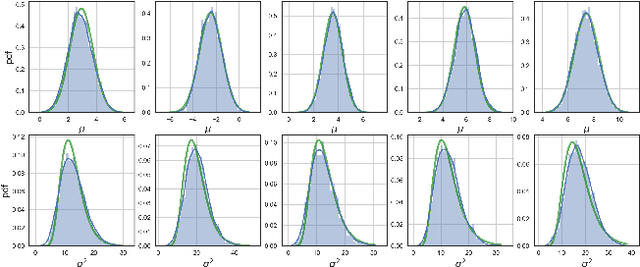
In this work, we investigate Batch Normalization technique and propose its probabilistic interpretation. We propose a probabilistic model and show that Batch Normalization maximazes the lower bound of its marginalized log-likelihood. Then, according to the new probabilistic model, we design an algorithm which acts consistently during train and test. However, inference becomes computationally inefficient. To reduce memory and computational cost, we propose Stochastic Batch Normalization -- an efficient approximation of proper inference procedure. This method provides us with a scalable uncertainty estimation technique. We demonstrate the performance of Stochastic Batch Normalization on popular architectures (including deep convolutional architectures: VGG-like and ResNets) for MNIST and CIFAR-10 datasets.
* Under review as a workshop paper at ICLR 2018