 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll Required, In Order: Phase-Level Evaluation for AI-Human Dialogue in Healthcare and Beyond
Jan 13, 2026Conversational AI is starting to support real clinical work, but most evaluation methods miss how compliance depends on the full course of a conversation. We introduce Obligatory-Information Phase Structured Compliance Evaluation (OIP-SCE), an evaluation method that checks whether every required clinical obligation is met, in the right order, with clear evidence for clinicians to review. This makes complex rules practical and auditable, helping close the gap between technical progress and what healthcare actually needs. We demonstrate the method in two case studies (respiratory history, benefits verification) and show how phase-level evidence turns policy into shared, actionable steps. By giving clinicians control over what to check and engineers a clear specification to implement, OIP-SCE provides a single, auditable evaluation surface that aligns AI capability with clinical workflow and supports routine, safe use.
HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification
Apr 09, 2025



This paper introduces a comprehensive system for detecting hallucinations in large language model (LLM) outputs in enterprise settings. We present a novel taxonomy of LLM responses specific to hallucination in enterprise applications, categorizing them into context-based, common knowledge, enterprise-specific, and innocuous statements. Our hallucination detection model HDM-2 validates LLM responses with respect to both context and generally known facts (common knowledge). It provides both hallucination scores and word-level annotations, enabling precise identification of problematic content. To evaluate it on context-based and common-knowledge hallucinations, we introduce a new dataset HDMBench. Experimental results demonstrate that HDM-2 out-performs existing approaches across RagTruth, TruthfulQA, and HDMBench datasets. This work addresses the specific challenges of enterprise deployment, including computational efficiency, domain specialization, and fine-grained error identification. Our evaluation dataset, model weights, and inference code are publicly available.
Steering Without Side Effects: Improving Post-Deployment Control of Language Models
Jun 21, 2024Language models (LMs) have been shown to behave unexpectedly post-deployment. For example, new jailbreaks continually arise, allowing model misuse, despite extensive red-teaming and adversarial training from developers. Given most model queries are unproblematic and frequent retraining results in unstable user experience, methods for mitigation of worst-case behavior should be targeted. One such method is classifying inputs as potentially problematic, then selectively applying steering vectors on these problematic inputs, i.e. adding particular vectors to model hidden states. However, steering vectors can also negatively affect model performance, which will be an issue on cases where the classifier was incorrect. We present KL-then-steer (KTS), a technique that decreases the side effects of steering while retaining its benefits, by first training a model to minimize Kullback-Leibler (KL) divergence between a steered and unsteered model on benign inputs, then steering the model that has undergone this training. Our best method prevents 44% of jailbreak attacks compared to the original Llama-2-chat-7B model while maintaining helpfulness (as measured by MT-Bench) on benign requests almost on par with the original LM. To demonstrate the generality and transferability of our method beyond jailbreaks, we show that our KTS model can be steered to reduce bias towards user-suggested answers on TruthfulQA. Code is available: https://github.com/AsaCooperStickland/kl-then-steer.
Inverse Scaling: When Bigger Isn't Better
Jun 15, 2023



Work on scaling laws has found that large language models (LMs) show predictable improvements to overall loss with increased scale (model size, training data, and compute). Here, we present evidence for the claim that LMs may show inverse scaling, or worse task performance with increased scale, e.g., due to flaws in the training objective and data. We present empirical evidence of inverse scaling on 11 datasets collected by running a public contest, the Inverse Scaling Prize, with a substantial prize pool. Through analysis of the datasets, along with other examples found in the literature, we identify four potential causes of inverse scaling: (i) preference to repeat memorized sequences over following in-context instructions, (ii) imitation of undesirable patterns in the training data, (iii) tasks containing an easy distractor task which LMs could focus on, rather than the harder real task, and (iv) correct but misleading few-shot demonstrations of the task. We release the winning datasets at https://inversescaling.com/data to allow for further investigation of inverse scaling. Our tasks have helped drive the discovery of U-shaped and inverted-U scaling trends, where an initial trend reverses, suggesting that scaling trends are less reliable at predicting the behavior of larger-scale models than previously understood. Overall, our results suggest that there are tasks for which increased model scale alone may not lead to progress, and that more careful thought needs to go into the data and objectives for training language models.
Normative Disagreement as a Challenge for Cooperative AI
Nov 27, 2021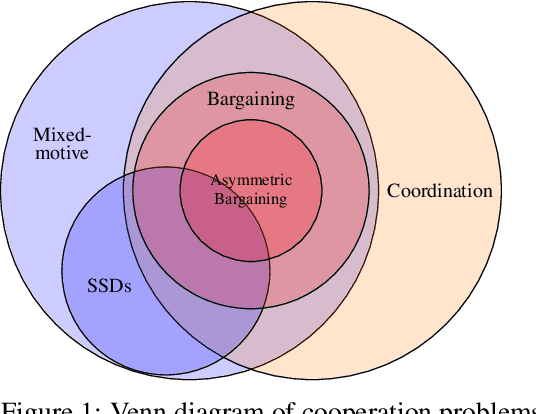



Cooperation in settings where agents have both common and conflicting interests (mixed-motive environments) has recently received considerable attention in multi-agent learning. However, the mixed-motive environments typically studied have a single cooperative outcome on which all agents can agree. Many real-world multi-agent environments are instead bargaining problems (BPs): they have several Pareto-optimal payoff profiles over which agents have conflicting preferences. We argue that typical cooperation-inducing learning algorithms fail to cooperate in BPs when there is room for normative disagreement resulting in the existence of multiple competing cooperative equilibria, and illustrate this problem empirically. To remedy the issue, we introduce the notion of norm-adaptive policies. Norm-adaptive policies are capable of behaving according to different norms in different circumstances, creating opportunities for resolving normative disagreement. We develop a class of norm-adaptive policies and show in experiments that these significantly increase cooperation. However, norm-adaptiveness cannot address residual bargaining failure arising from a fundamental tradeoff between exploitability and cooperative robustness.
Greedy Policy Search: A Simple Baseline for Learnable Test-Time Augmentation
Feb 21, 2020
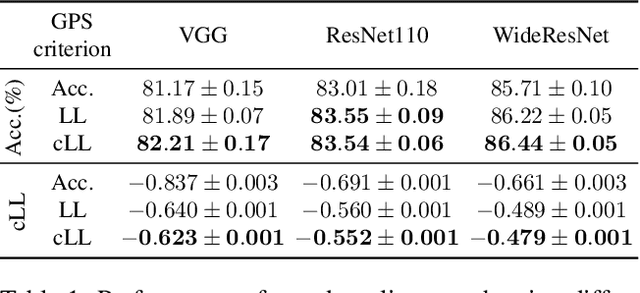
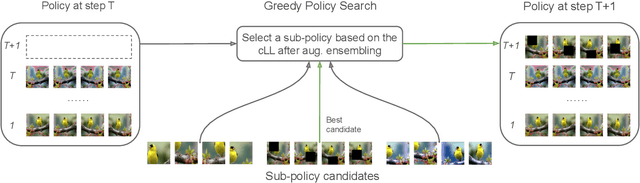

Test-time data augmentation---averaging the predictions of a machine learning model across multiple augmented samples of data---is a widely used technique that improves the predictive performance. While many advanced learnable data augmentation techniques have emerged in recent years, they are focused on the training phase. Such techniques are not necessarily optimal for test-time augmentation and can be outperformed by a policy consisting of simple crops and flips. The primary goal of this paper is to demonstrate that test-time augmentation policies can be successfully learned too. We~introduce \emph{greedy policy search} (GPS), a simple but high-performing method for learning a policy of test-time augmentation. We demonstrate that augmentation policies learned with GPS achieve superior predictive performance on image classification problems, provide better in-domain uncertainty estimation, and improve the robustness to domain shift.
Pitfalls of In-Domain Uncertainty Estimation and Ensembling in Deep Learning
Feb 15, 2020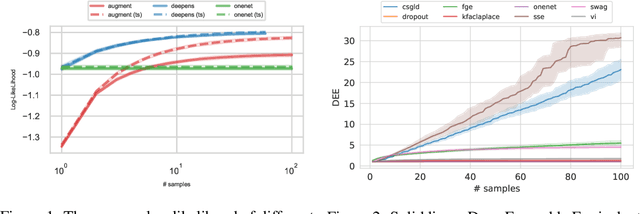


Uncertainty estimation and ensembling methods go hand-in-hand. Uncertainty estimation is one of the main benchmarks for assessment of ensembling performance. At the same time, deep learning ensembles have provided state-of-the-art results in uncertainty estimation. In this work, we focus on in-domain uncertainty for image classification. We explore the standards for its quantification and point out pitfalls of existing metrics. Avoiding these pitfalls, we perform a broad study of different ensembling techniques. To provide more insight in this study, we introduce the deep ensemble equivalent score (DEE) and show that many sophisticated ensembling techniques are equivalent to an ensemble of only few independently trained networks in terms of test performance.