 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManifoldKV: Training-Free KV Cache Compression via Euclidean Outlier Detection
Feb 09, 2026Long-context inference is constrained by KV-cache memory, which grows linearly with sequence length; KV-cache compression therefore hinges on reliably selecting which past tokens to retain. Most geometry-based eviction methods score keys by cosine similarity to a global centroid, but cosine is scale-invariant and can discard magnitude cues that distinguish semantically salient tokens. We propose ManifoldKV, a training-free scorer that ranks tokens by Euclidean distance to the key centroid, capturing both angular and radial deviations. On the RULER benchmark, ManifoldKV achieves 95.7% accuracy at 4K-16K contexts with 20% compression; matching the best geometric baseline while improving robustness in two regimes where cosine scoring fails. First, on multi-key retrieval, ManifoldKV reduces directional collisions, achieving 92.4% vs KeyDiff's 77.0% (+15.4 points) on 3-key NIAH at 50% compression. Second, to address dilution and performance collapse of global centroids at 64K context, we introduce WindowedManifoldKV, which restores accuracy to 84.3% at 25% compression, a 49-point recovery over global L2 and +3.2 points over KeyDiff. The method requires only 3 lines of code and works across 4 architectures without tuning.
HalluciNot: Hallucination Detection Through Context and Common Knowledge Verification
Apr 09, 2025



This paper introduces a comprehensive system for detecting hallucinations in large language model (LLM) outputs in enterprise settings. We present a novel taxonomy of LLM responses specific to hallucination in enterprise applications, categorizing them into context-based, common knowledge, enterprise-specific, and innocuous statements. Our hallucination detection model HDM-2 validates LLM responses with respect to both context and generally known facts (common knowledge). It provides both hallucination scores and word-level annotations, enabling precise identification of problematic content. To evaluate it on context-based and common-knowledge hallucinations, we introduce a new dataset HDMBench. Experimental results demonstrate that HDM-2 out-performs existing approaches across RagTruth, TruthfulQA, and HDMBench datasets. This work addresses the specific challenges of enterprise deployment, including computational efficiency, domain specialization, and fine-grained error identification. Our evaluation dataset, model weights, and inference code are publicly available.
Towards Automatic Bias Detection in Knowledge Graphs
Sep 19, 2021
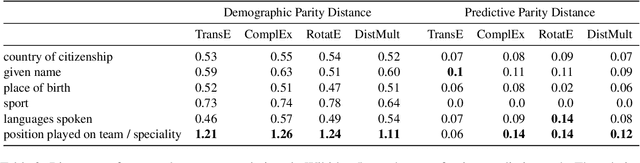


With the recent surge in social applications relying on knowledge graphs, the need for techniques to ensure fairness in KG based methods is becoming increasingly evident. Previous works have demonstrated that KGs are prone to various social biases, and have proposed multiple methods for debiasing them. However, in such studies, the focus has been on debiasing techniques, while the relations to be debiased are specified manually by the user. As manual specification is itself susceptible to human cognitive bias, there is a need for a system capable of quantifying and exposing biases, that can support more informed decisions on what to debias. To address this gap in the literature, we describe a framework for identifying biases present in knowledge graph embeddings, based on numerical bias metrics. We illustrate the framework with three different bias measures on the task of profession prediction, and it can be flexibly extended to further bias definitions and applications. The relations flagged as biased can then be handed to decision makers for judgement upon subsequent debiasing.
Random Walks with Erasure: Diversifying Personalized Recommendations on Social and Information Networks
Feb 25, 2021

Most existing personalization systems promote items that match a user's previous choices or those that are popular among similar users. This results in recommendations that are highly similar to the ones users are already exposed to, resulting in their isolation inside familiar but insulated information silos. In this context, we develop a novel recommendation framework with a goal of improving information diversity using a modified random walk exploration of the user-item graph. We focus on the problem of political content recommendation, while addressing a general problem applicable to personalization tasks in other social and information networks. For recommending political content on social networks, we first propose a new model to estimate the ideological positions for both users and the content they share, which is able to recover ideological positions with high accuracy. Based on these estimated positions, we generate diversified personalized recommendations using our new random-walk based recommendation algorithm. With experimental evaluations on large datasets of Twitter discussions, we show that our method based on \emph{random walks with erasure} is able to generate more ideologically diverse recommendations. Our approach does not depend on the availability of labels regarding the bias of users or content producers. With experiments on open benchmark datasets from other social and information networks, we also demonstrate the effectiveness of our method in recommending diverse long-tail items.
* Web Conference 2021 (WWW '21)
Adversarial Learning for Debiasing Knowledge Graph Embeddings
Jun 29, 2020

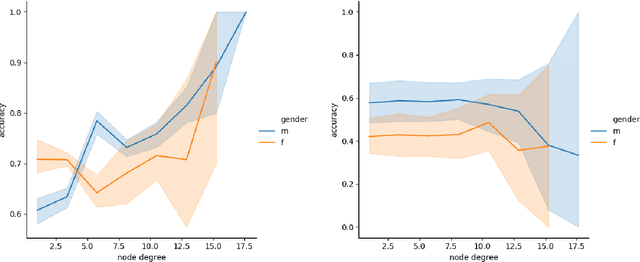
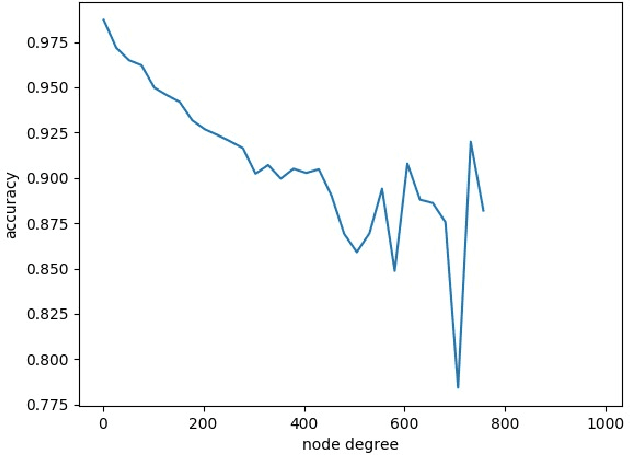
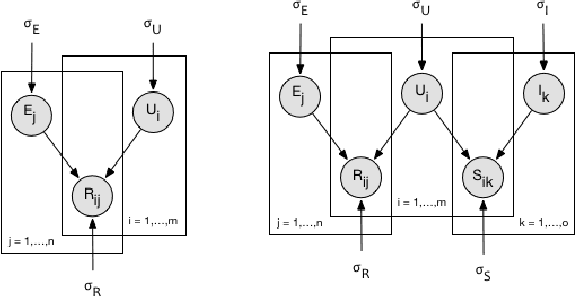
Knowledge Graphs (KG) are gaining increasing attention in both academia and industry. Despite their diverse benefits, recent research have identified social and cultural biases embedded in the representations learned from KGs. Such biases can have detrimental consequences on different population and minority groups as applications of KG begin to intersect and interact with social spheres. This paper aims at identifying and mitigating such biases in Knowledge Graph (KG) embeddings. As a first step, we explore popularity bias -- the relationship between node popularity and link prediction accuracy. In case of node2vec graph embeddings, we find that prediction accuracy of the embedding is negatively correlated with the degree of the node. However, in case of knowledge-graph embeddings (KGE), we observe an opposite trend. As a second step, we explore gender bias in KGE, and a careful examination of popular KGE algorithms suggest that sensitive attribute like the gender of a person can be predicted from the embedding. This implies that such biases in popular KGs is captured by the structural properties of the embedding. As a preliminary solution to debiasing KGs, we introduce a novel framework to filter out the sensitive attribute information from the KG embeddings, which we call FAN (Filtering Adversarial Network). We also suggest the applicability of FAN for debiasing other network embeddings which could be explored in future work.
A Deep Learning Pipeline for Patient Diagnosis Prediction Using Electronic Health Records
Jun 23, 2020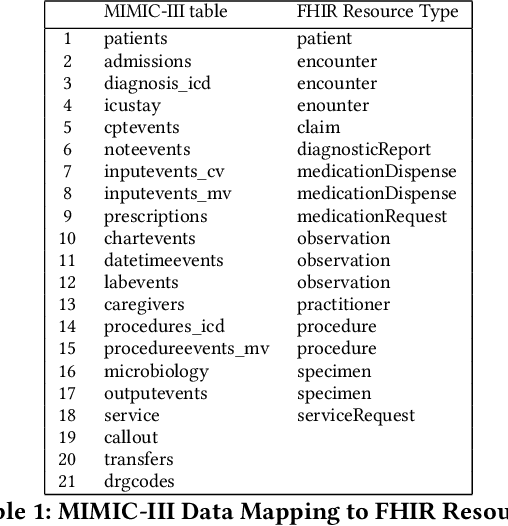
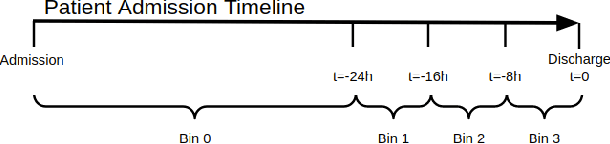
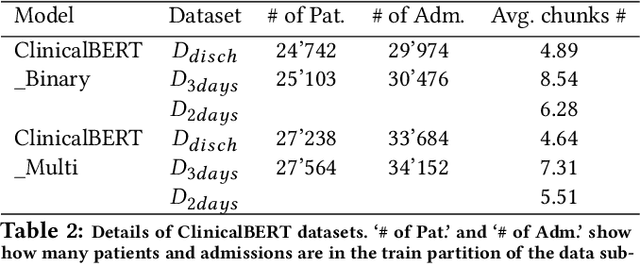

Augmentation of disease diagnosis and decision-making in healthcare with machine learning algorithms is gaining much impetus in recent years. In particular, in the current epidemiological situation caused by COVID-19 pandemic, swift and accurate prediction of disease diagnosis with machine learning algorithms could facilitate identification and care of vulnerable clusters of population, such as those having multi-morbidity conditions. In order to build a useful disease diagnosis prediction system, advancement in both data representation and development of machine learning architectures are imperative. First, with respect to data collection and representation, we face severe problems due to multitude of formats and lack of coherency prevalent in Electronic Health Records (EHRs). This causes hindrance in extraction of valuable information contained in EHRs. Currently, no universal global data standard has been established. As a useful solution, we develop and publish a Python package to transform public health dataset into an easy to access universal format. This data transformation to an international health data format facilitates researchers to easily combine EHR datasets with clinical datasets of diverse formats. Second, machine learning algorithms that predict multiple disease diagnosis categories simultaneously remain underdeveloped. We propose two novel model architectures in this regard. First, DeepObserver, which uses structured numerical data to predict the diagnosis categories and second, ClinicalBERT_Multi, that incorporates rich information available in clinical notes via natural language processing methods and also provides interpretable visualizations to medical practitioners. We show that both models can predict multiple diagnoses simultaneously with high accuracy.
Iteratively Learning Embeddings and Rules for Knowledge Graph Reasoning
Mar 21, 2019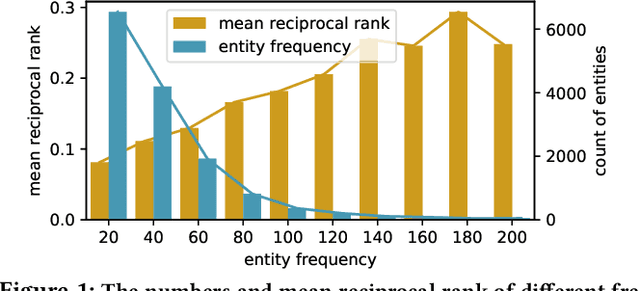

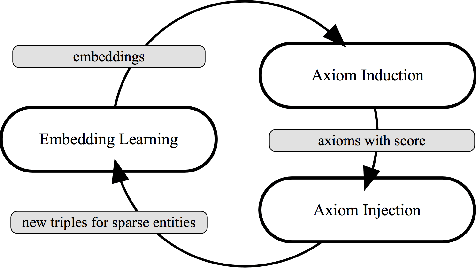
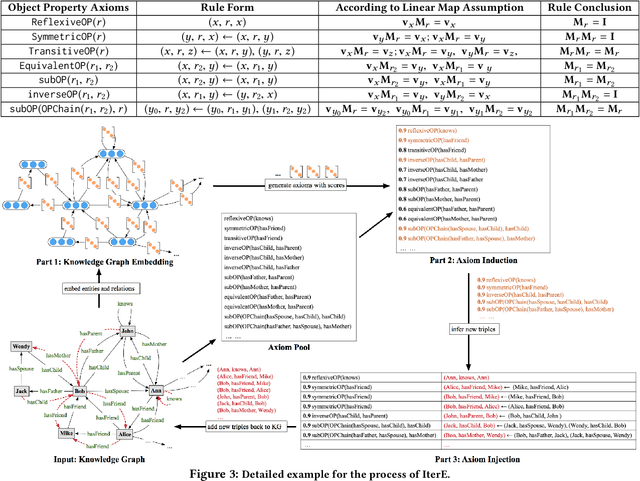
Reasoning is essential for the development of large knowledge graphs, especially for completion, which aims to infer new triples based on existing ones. Both rules and embeddings can be used for knowledge graph reasoning and they have their own advantages and difficulties. Rule-based reasoning is accurate and explainable but rule learning with searching over the graph always suffers from efficiency due to huge search space. Embedding-based reasoning is more scalable and efficient as the reasoning is conducted via computation between embeddings, but it has difficulty learning good representations for sparse entities because a good embedding relies heavily on data richness. Based on this observation, in this paper we explore how embedding and rule learning can be combined together and complement each other's difficulties with their advantages. We propose a novel framework IterE iteratively learning embeddings and rules, in which rules are learned from embeddings with proper pruning strategy and embeddings are learned from existing triples and new triples inferred by rules. Evaluations on embedding qualities of IterE show that rules help improve the quality of sparse entity embeddings and their link prediction results. We also evaluate the efficiency of rule learning and quality of rules from IterE compared with AMIE+, showing that IterE is capable of generating high quality rules more efficiently. Experiments show that iteratively learning embeddings and rules benefit each other during learning and prediction.
Interaction Embeddings for Prediction and Explanation in Knowledge Graphs
Mar 12, 2019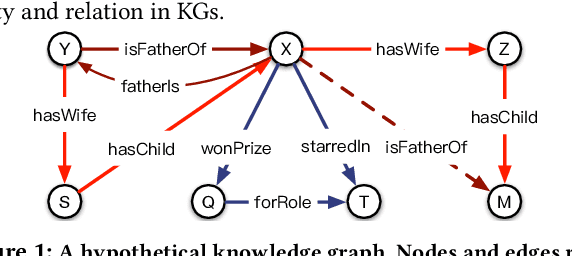
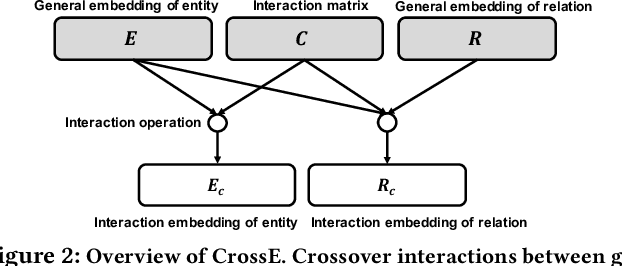
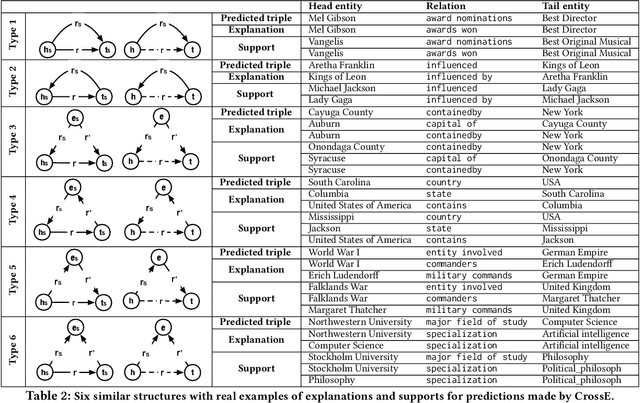
Knowledge graph embedding aims to learn distributed representations for entities and relations, and is proven to be effective in many applications. Crossover interactions --- bi-directional effects between entities and relations --- help select related information when predicting a new triple, but haven't been formally discussed before. In this paper, we propose CrossE, a novel knowledge graph embedding which explicitly simulates crossover interactions. It not only learns one general embedding for each entity and relation as most previous methods do, but also generates multiple triple specific embeddings for both of them, named interaction embeddings. We evaluate embeddings on typical link prediction tasks and find that CrossE achieves state-of-the-art results on complex and more challenging datasets. Furthermore, we evaluate embeddings from a new perspective --- giving explanations for predicted triples, which is important for real applications. In this work, an explanation for a triple is regarded as a reliable closed-path between the head and the tail entity. Compared to other baselines, we show experimentally that CrossE, benefiting from interaction embeddings, is more capable of generating reliable explanations to support its predictions.
Loss Aversion in Recommender Systems: Utilizing Negative User Preference to Improve Recommendation Quality
Dec 29, 2018
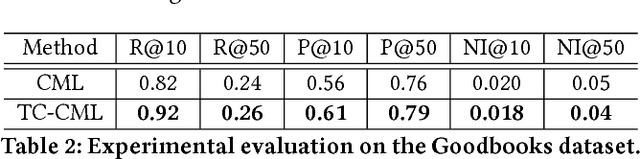

Negative user preference is an important context that is not sufficiently utilized by many existing recommender systems. This context is especially useful in scenarios where the cost of negative items is high for the users. In this work, we describe a new recommender algorithm that explicitly models negative user preferences in order to recommend more positive items at the top of recommendation-lists. We build upon existing machine-learning model to incorporate the contextual information provided by negative user preference. With experimental evaluations on two openly available datasets, we show that our method is able to improve recommendation quality: by improving accuracy and at the same time reducing the number of negative items at the top of recommendation-lists. Our work demonstrates the value of the contextual information provided by negative feedback, and can also be extended to signed social networks and link prediction in other networks.