 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards BERT-based Automatic ICD Coding: Limitations and Opportunities
Apr 14, 2021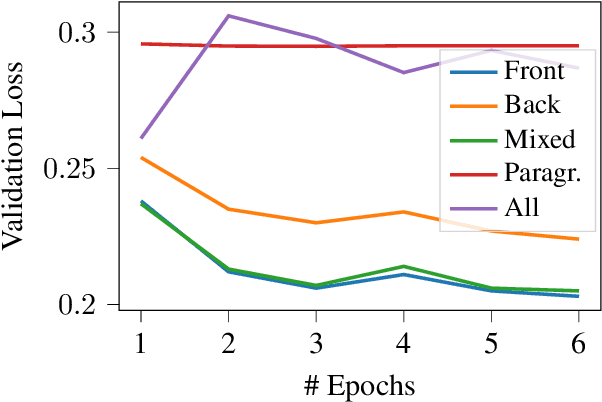
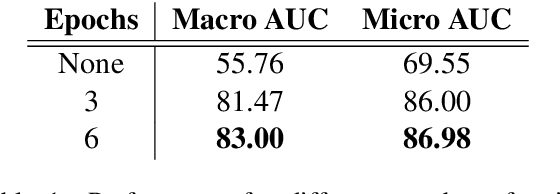
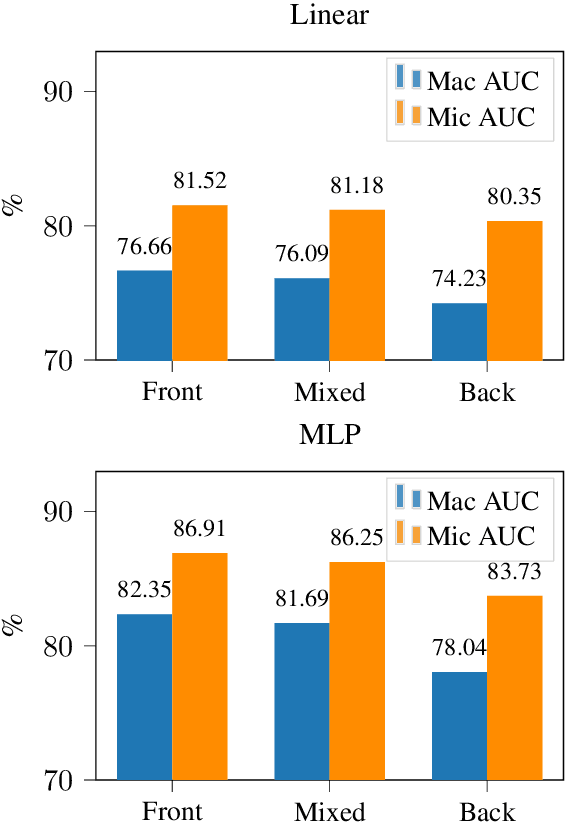

Automatic ICD coding is the task of assigning codes from the International Classification of Diseases (ICD) to medical notes. These codes describe the state of the patient and have multiple applications, e.g., computer-assisted diagnosis or epidemiological studies. ICD coding is a challenging task due to the complexity and length of medical notes. Unlike the general trend in language processing, no transformer model has been reported to reach high performance on this task. Here, we investigate in detail ICD coding using PubMedBERT, a state-of-the-art transformer model for biomedical language understanding. We find that the difficulty of fine-tuning the model on long pieces of text is the main limitation for BERT-based models on ICD coding. We run extensive experiments and show that despite the gap with current state-of-the-art, pretrained transformers can reach competitive performance using relatively small portions of text. We point at better methods to aggregate information from long texts as the main need for improving BERT-based ICD coding.
Medley2K: A Dataset of Medley Transitions
Aug 25, 2020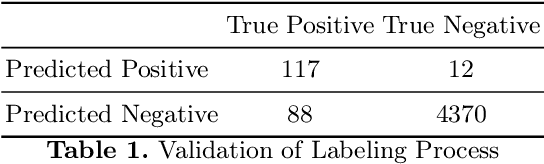
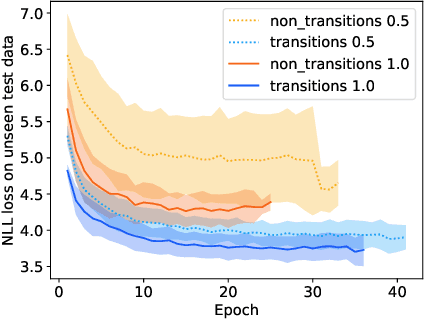
The automatic generation of medleys, i.e., musical pieces formed by different songs concatenated via smooth transitions, is not well studied in the current literature. To facilitate research on this topic, we make available a dataset called Medley2K that consists of 2,000 medleys and 7,712 labeled transitions. Our dataset features a rich variety of song transitions across different music genres. We provide a detailed description of this dataset and validate it by training a state-of-the-art generative model in the task of generating transitions between songs.
Loss Aversion in Recommender Systems: Utilizing Negative User Preference to Improve Recommendation Quality
Dec 29, 2018
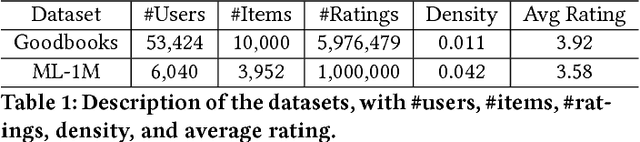
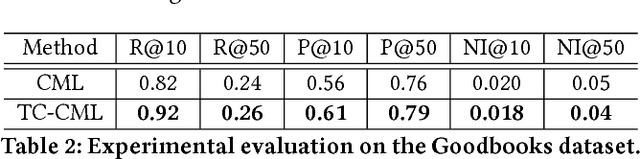

Negative user preference is an important context that is not sufficiently utilized by many existing recommender systems. This context is especially useful in scenarios where the cost of negative items is high for the users. In this work, we describe a new recommender algorithm that explicitly models negative user preferences in order to recommend more positive items at the top of recommendation-lists. We build upon existing machine-learning model to incorporate the contextual information provided by negative user preference. With experimental evaluations on two openly available datasets, we show that our method is able to improve recommendation quality: by improving accuracy and at the same time reducing the number of negative items at the top of recommendation-lists. Our work demonstrates the value of the contextual information provided by negative feedback, and can also be extended to signed social networks and link prediction in other networks.