 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepNLP-Mixer: an Efficient all-MLP Architecture for Language
Feb 09, 2022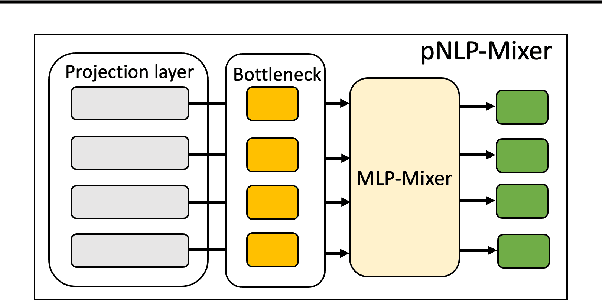
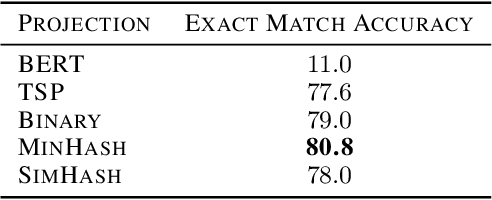
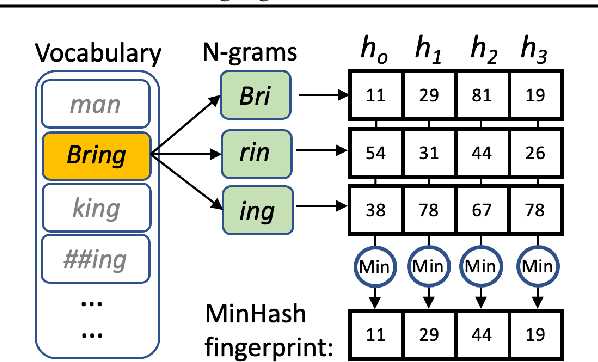
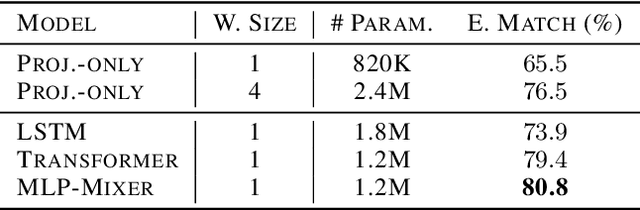
Large pre-trained language models drastically changed the natural language processing(NLP) landscape. Nowadays, they represent the go-to framework to tackle diverse NLP tasks, even with a limited number of annotations. However, using those models in production, either in the cloud or at the edge, remains a challenge due to the memory footprint and/or inference costs. As an alternative, recent work on efficient NLP has shown that small weight-efficient models can reach competitive performance at a fraction of the costs. Here, we introduce pNLP-Mixer, an embbedding-free model based on the MLP-Mixer architecture that achieves high weight-efficiency thanks to a novel linguistically informed projection layer. We evaluate our model on two multi-lingual semantic parsing datasets, MTOP and multiATIS. On MTOP our pNLP-Mixer almost matches the performance of mBERT, which has 38 times more parameters, and outperforms the state-of-the-art of tiny models (pQRNN) with 3 times fewer parameters. On a long-sequence classification task (Hyperpartisan) our pNLP-Mixer without pretraining outperforms RoBERTa, which has 100 times more parameters, demonstrating the potential of this architecture.
On Isotropy Calibration of Transformers
Sep 27, 2021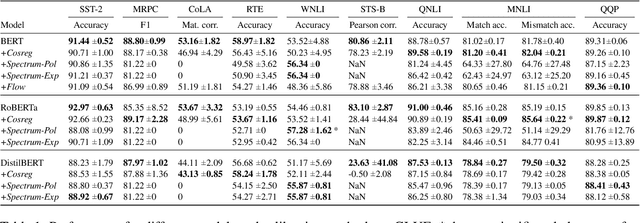
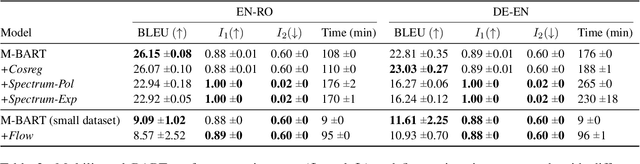
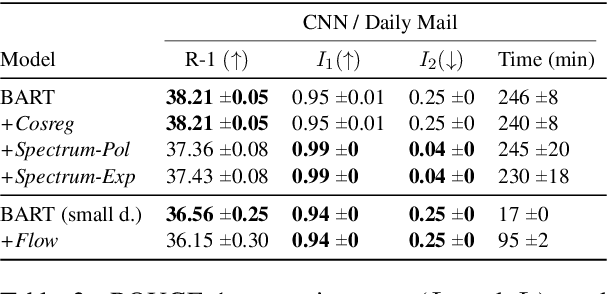
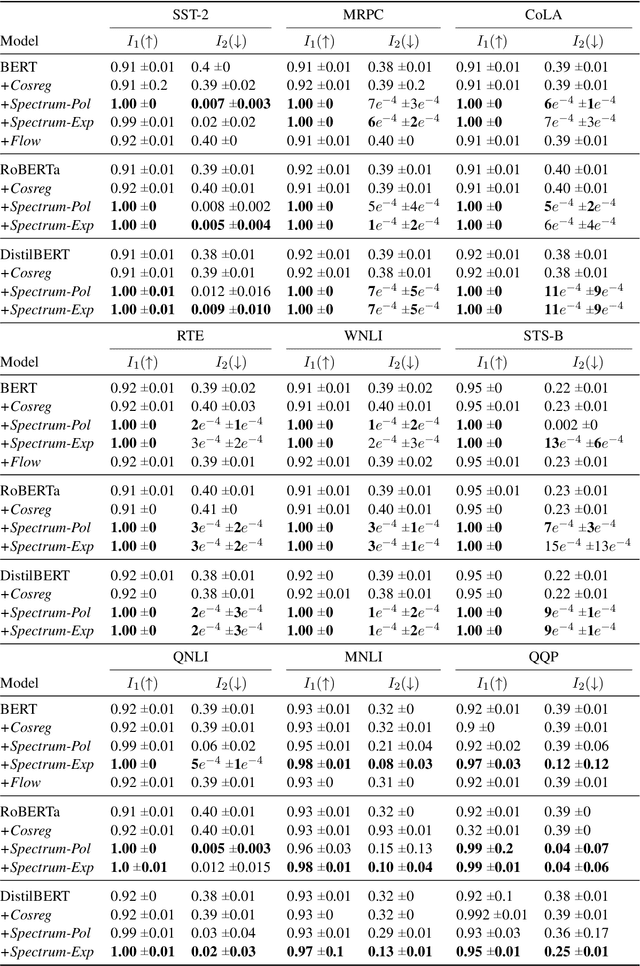
Different studies of the embedding space of transformer models suggest that the distribution of contextual representations is highly anisotropic - the embeddings are distributed in a narrow cone. Meanwhile, static word representations (e.g., Word2Vec or GloVe) have been shown to benefit from isotropic spaces. Therefore, previous work has developed methods to calibrate the embedding space of transformers in order to ensure isotropy. However, a recent study (Cai et al. 2021) shows that the embedding space of transformers is locally isotropic, which suggests that these models are already capable of exploiting the expressive capacity of their embedding space. In this work, we conduct an empirical evaluation of state-of-the-art methods for isotropy calibration on transformers and find that they do not provide consistent improvements across models and tasks. These results support the thesis that, given the local isotropy, transformers do not benefit from additional isotropy calibration.
A Plug-and-Play Method for Controlled Text Generation
Sep 20, 2021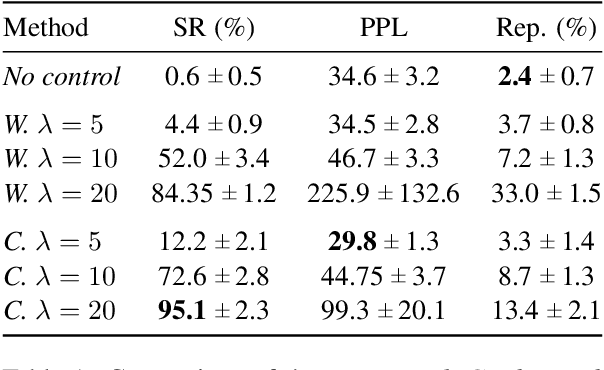
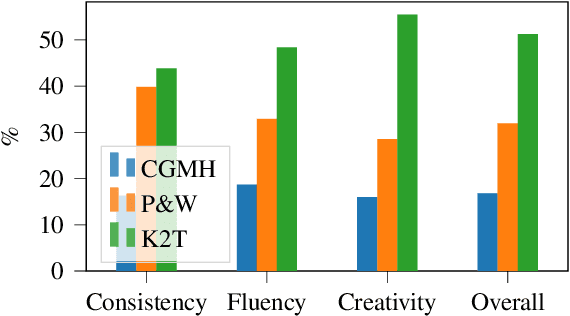
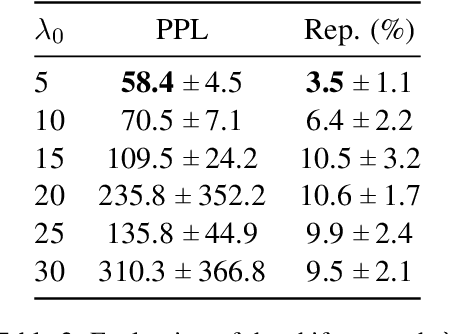
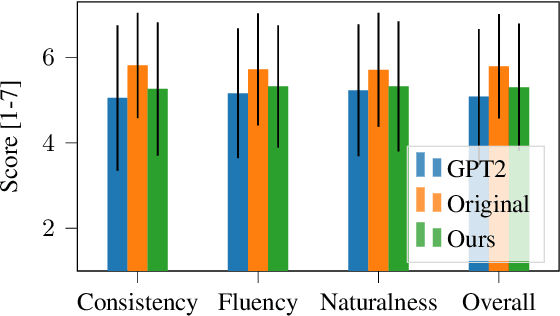
Large pre-trained language models have repeatedly shown their ability to produce fluent text. Yet even when starting from a prompt, generation can continue in many plausible directions. Current decoding methods with the goal of controlling generation, e.g., to ensure specific words are included, either require additional models or fine-tuning, or work poorly when the task at hand is semantically unconstrained, e.g., story generation. In this work, we present a plug-and-play decoding method for controlled language generation that is so simple and intuitive, it can be described in a single sentence: given a topic or keyword, we add a shift to the probability distribution over our vocabulary towards semantically similar words. We show how annealing this distribution can be used to impose hard constraints on language generation, something no other plug-and-play method is currently able to do with SOTA language generators. Despite the simplicity of this approach, we see it works incredibly well in practice: decoding from GPT-2 leads to diverse and fluent sentences while guaranteeing the appearance of given guide words. We perform two user studies, revealing that (1) our method outperforms competing methods in human evaluations; and (2) forcing the guide words to appear in the generated text has no impact on the fluency of the generated text.
Towards BERT-based Automatic ICD Coding: Limitations and Opportunities
Apr 14, 2021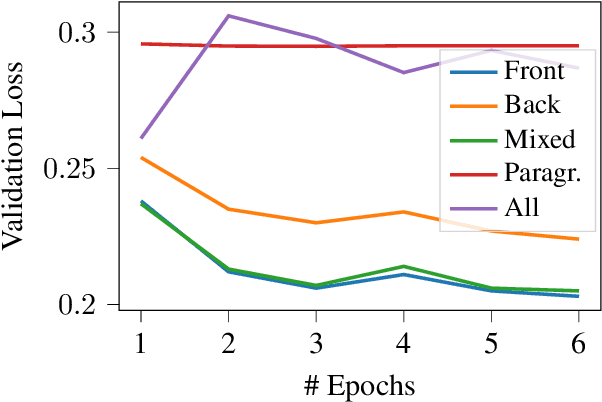
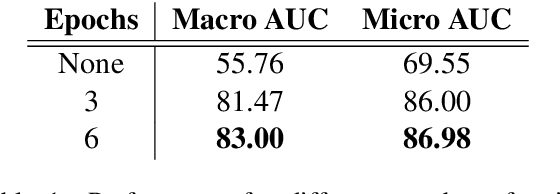
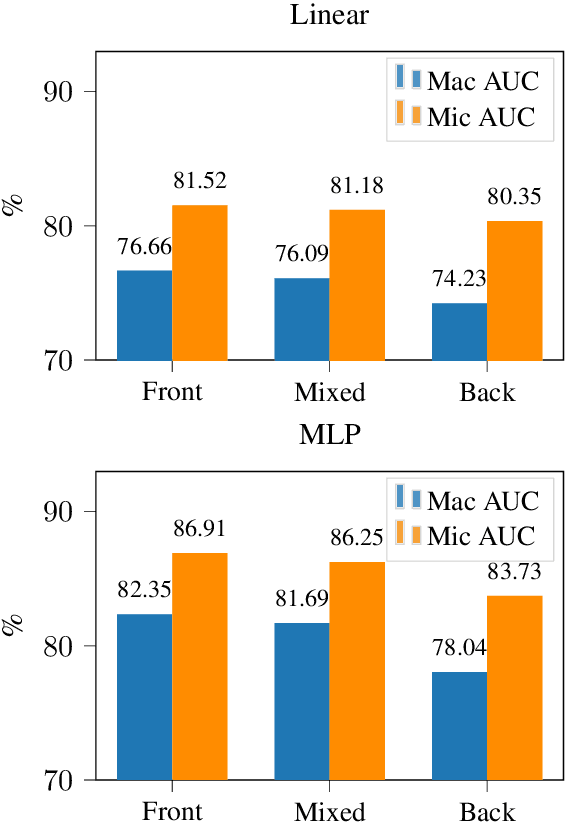

Automatic ICD coding is the task of assigning codes from the International Classification of Diseases (ICD) to medical notes. These codes describe the state of the patient and have multiple applications, e.g., computer-assisted diagnosis or epidemiological studies. ICD coding is a challenging task due to the complexity and length of medical notes. Unlike the general trend in language processing, no transformer model has been reported to reach high performance on this task. Here, we investigate in detail ICD coding using PubMedBERT, a state-of-the-art transformer model for biomedical language understanding. We find that the difficulty of fine-tuning the model on long pieces of text is the main limitation for BERT-based models on ICD coding. We run extensive experiments and show that despite the gap with current state-of-the-art, pretrained transformers can reach competitive performance using relatively small portions of text. We point at better methods to aggregate information from long texts as the main need for improving BERT-based ICD coding.
Of Non-Linearity and Commutativity in BERT
Jan 14, 2021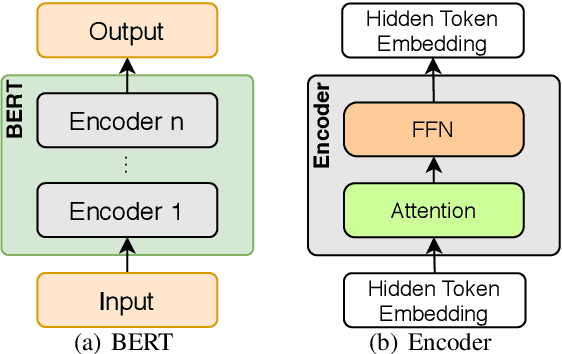
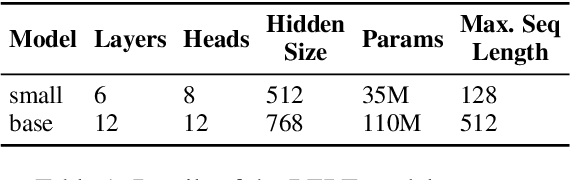
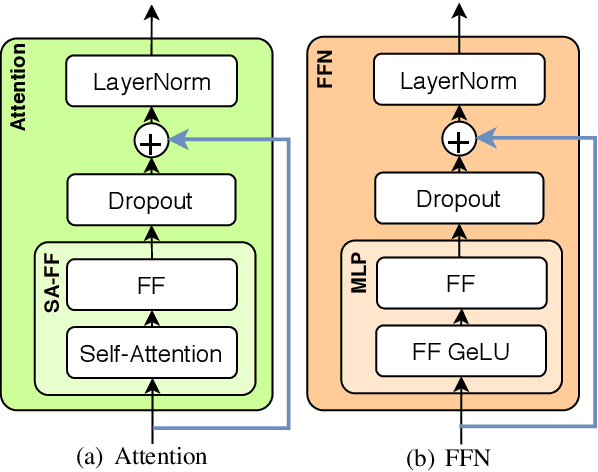
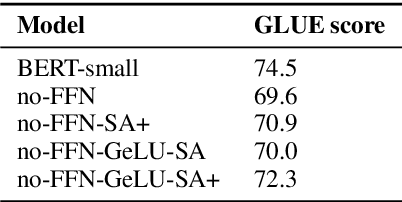
In this work we provide new insights into the transformer architecture, and in particular, its best-known variant, BERT. First, we propose a method to measure the degree of non-linearity of different elements of transformers. Next, we focus our investigation on the feed-forward networks (FFN) inside transformers, which contain 2/3 of the model parameters and have so far not received much attention. We find that FFNs are an inefficient yet important architectural element and that they cannot simply be replaced by attention blocks without a degradation in performance. Moreover, we study the interactions between layers in BERT and show that, while the layers exhibit some hierarchical structure, they extract features in a fuzzy manner. Our results suggest that BERT has an inductive bias towards layer commutativity, which we find is mainly due to the skip connections. This provides a justification for the strong performance of recurrent and weight-shared transformer models.
Directed Beam Search: Plug-and-Play Lexically Constrained Language Generation
Dec 31, 2020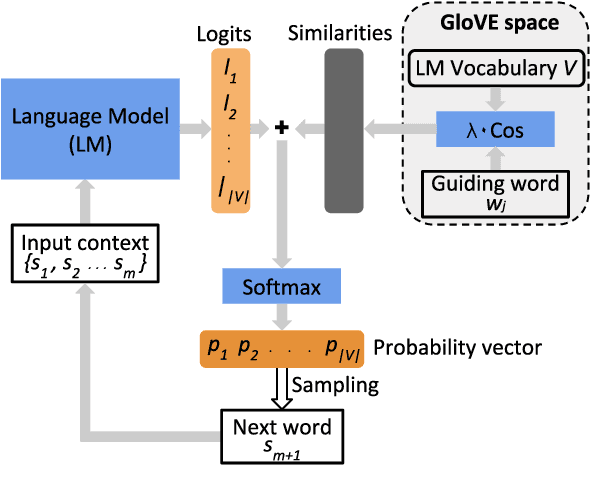
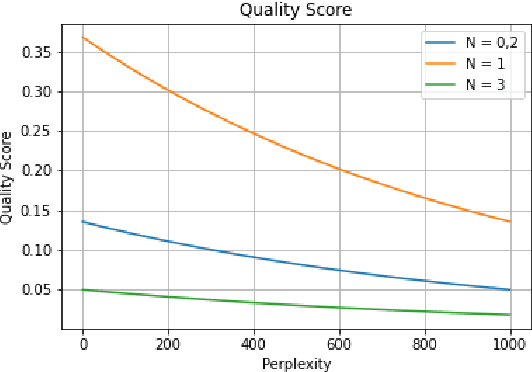

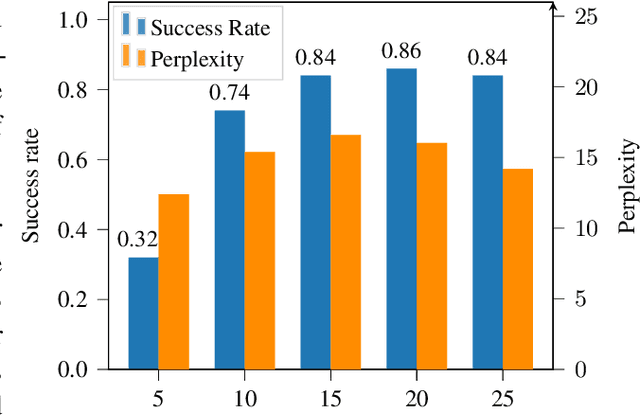
Large pre-trained language models are capable of generating realistic text. However, controlling these models so that the generated text satisfies lexical constraints, i.e., contains specific words, is a challenging problem. Given that state-of-the-art language models are too large to be trained from scratch in a manageable time, it is desirable to control these models without re-training them. Methods capable of doing this are called plug-and-play. Recent plug-and-play methods have been successful in constraining small bidirectional language models as well as forward models in tasks with a restricted search space, e.g., machine translation. However, controlling large transformer-based models to meet lexical constraints without re-training them remains a challenge. In this work, we propose Directed Beam Search (DBS), a plug-and-play method for lexically constrained language generation. Our method can be applied to any language model, is easy to implement and can be used for general language generation. In our experiments we use DBS to control GPT-2. We demonstrate its performance on keyword-to-phrase generation and we obtain comparable results as a state-of-the-art non-plug-and-play model for lexically constrained story generation.
Brain2Word: Decoding Brain Activity for Language Generation
Oct 13, 2020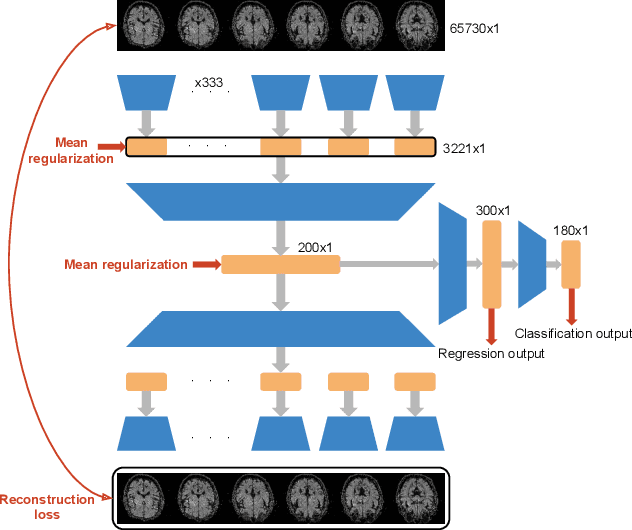
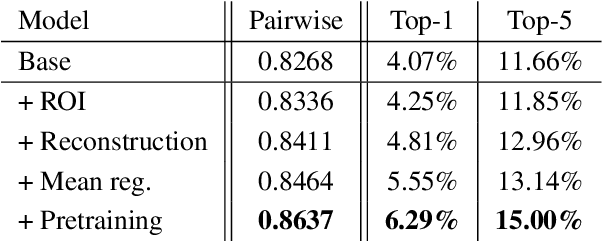
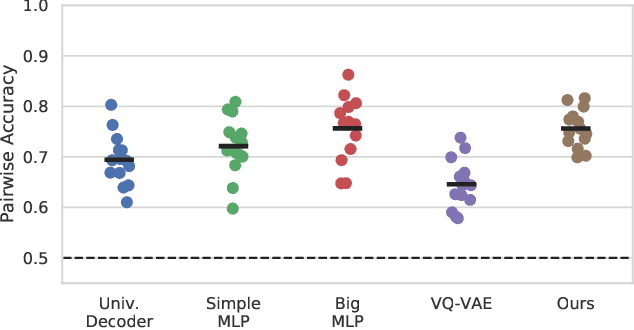
Brain decoding, understood as the process of mapping brain activities to the stimuli that generated them, has been an active research area in the last years. In the case of language stimuli, recent studies have shown that it is possible to decode fMRI scans into an embedding of the word a subject is reading. However, such word embeddings are designed for natural language processing tasks rather than for brain decoding. Therefore, they limit our ability to recover the precise stimulus. In this work, we propose to directly classify an fMRI scan, mapping it to the corresponding word within a fixed vocabulary. Unlike existing work, we evaluate on scans from previously unseen subjects. We argue that this is a more realistic setup and we present a model that can decode fMRI data from unseen subjects. Our model achieves 5.22% Top-1 and 13.59% Top-5 accuracy in this challenging task, significantly outperforming all the considered competitive baselines. Furthermore, we use the decoded words to guide language generation with the GPT-2 model. This way, we advance the quest for a system that translates brain activities into coherent text.
Medley2K: A Dataset of Medley Transitions
Aug 25, 2020
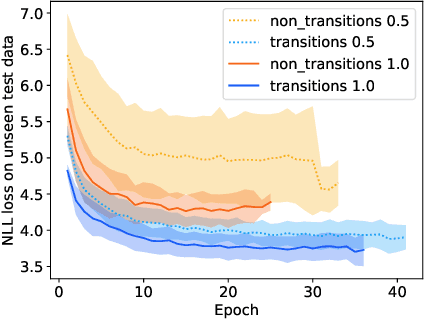
The automatic generation of medleys, i.e., musical pieces formed by different songs concatenated via smooth transitions, is not well studied in the current literature. To facilitate research on this topic, we make available a dataset called Medley2K that consists of 2,000 medleys and 7,712 labeled transitions. Our dataset features a rich variety of song transitions across different music genres. We provide a detailed description of this dataset and validate it by training a state-of-the-art generative model in the task of generating transitions between songs.
Telling BERT's full story: from Local Attention to Global Aggregation
Apr 10, 2020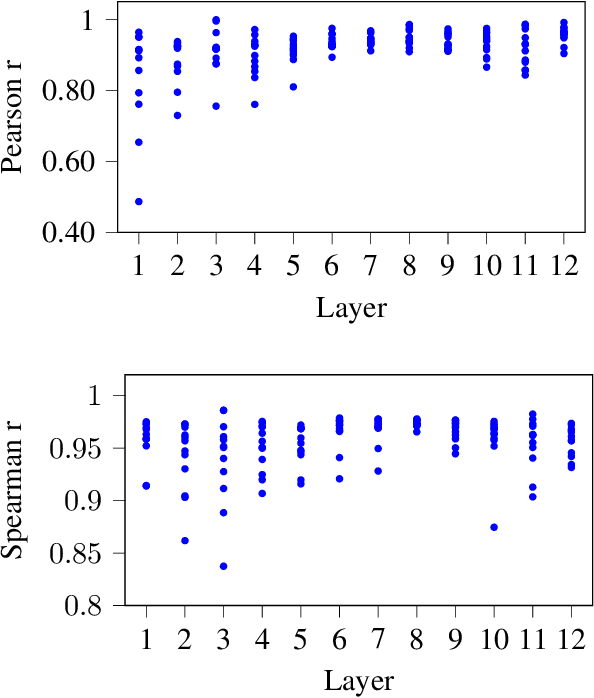
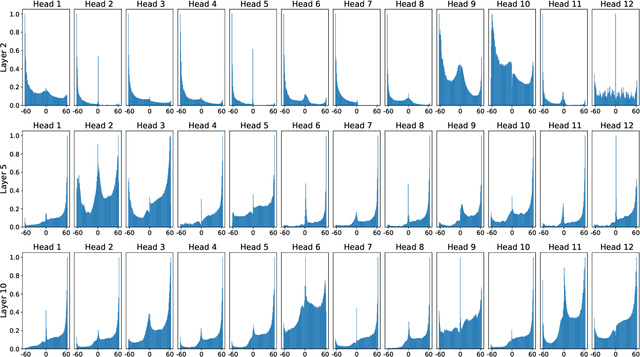
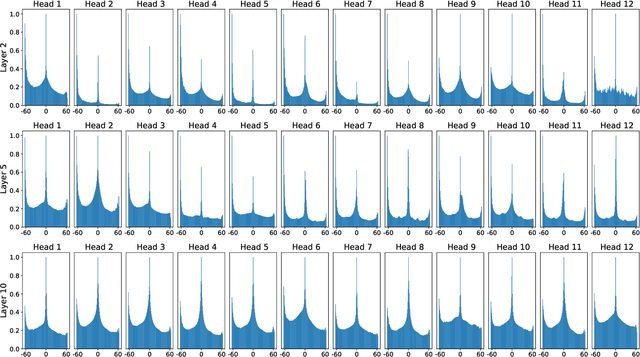
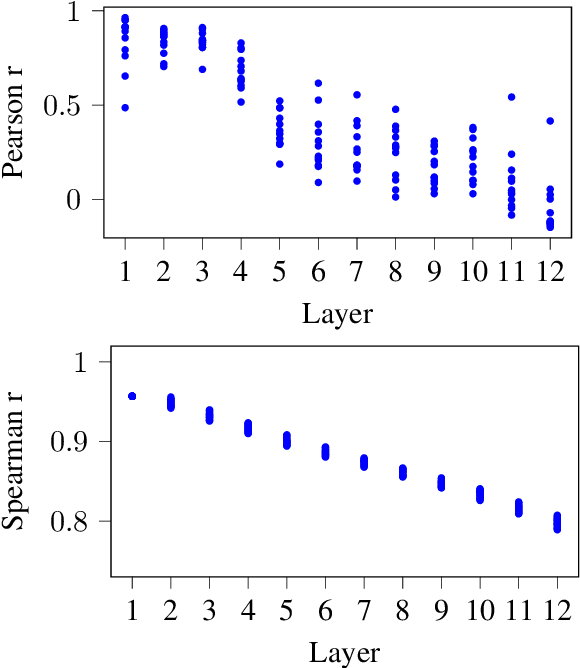
We take a deep look into the behavior of self-attention heads in the transformer architecture. In light of recent work discouraging the use of attention distributions for explaining a model's behavior, we show that attention distributions can nevertheless provide insights into the local behavior of attention heads. This way, we propose a distinction between local patterns revealed by attention and global patterns that refer back to the input, and analyze BERT from both angles. We use gradient attribution to analyze how the output of an attention attention head depends on the input tokens, effectively extending the local attention-based analysis to account for the mixing of information throughout the transformer layers. We find that there is a significant discrepancy between attention and attribution distributions, caused by the mixing of context inside the model. We quantify this discrepancy and observe that interestingly, there are some patterns that persist across all layers despite the mixing.
Synthetic Epileptic Brain Activities Using Generative Adversarial Networks
Jul 22, 2019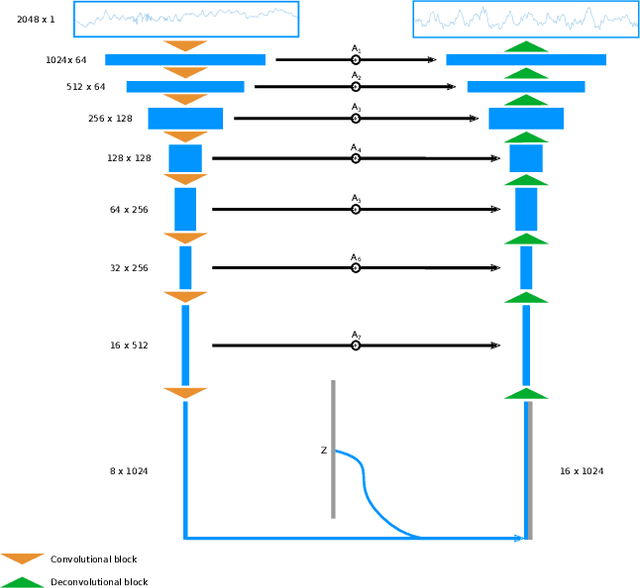
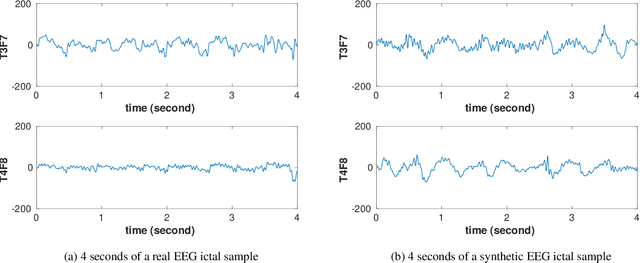
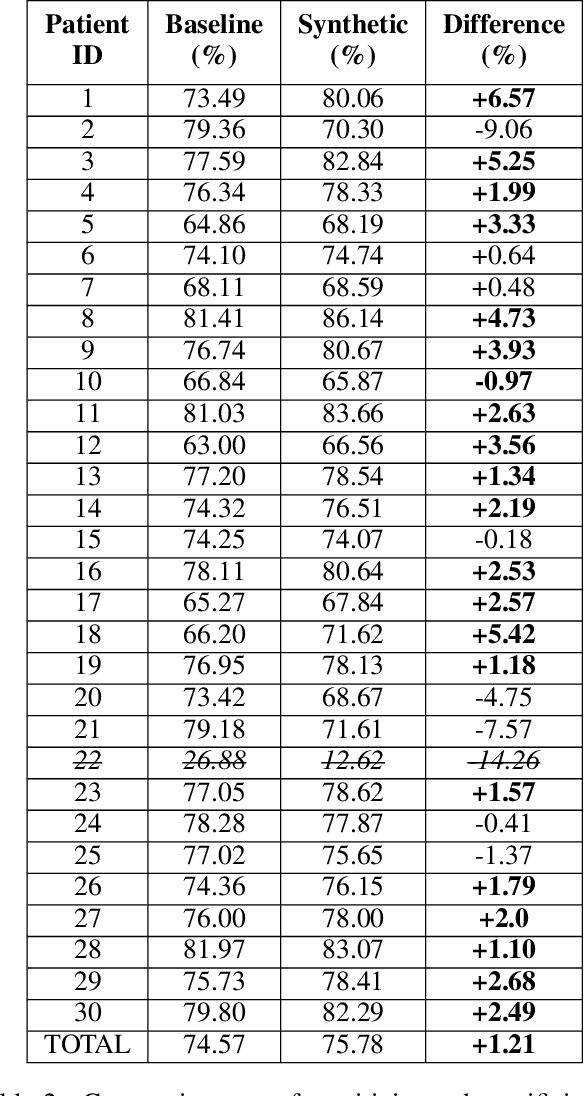
Epilepsy is a chronic neurological disorder affecting more than 65 million people worldwide and manifested by recurrent unprovoked seizures. The unpredictability of seizures not only degrades the quality of life of the patients, but it can also be life-threatening. Modern systems monitoring electroencephalography (EEG) signals are being currently developed with the view to detect epileptic seizures in order to alert caregivers and reduce the impact of seizures on patients' quality of life. Such seizure detection systems employ state-of-the-art machine learning algorithms that require a considerably large amount of labeled personal data for training. However, acquiring EEG signals of epileptic seizures is a costly and time-consuming process for medical experts and patients, currently requiring in-hospital recordings in specialized units. In this work, we generate synthetic seizure-like brain electrical activities, i.e., EEG signals, that can be used to train seizure detection algorithms, alleviating the need for recorded data. First, we train a Generative Adversarial Network (GAN) with data from 30 epilepsy patients. Then, we generate synthetic personalized training sets for new, unseen patients, which overall yield higher detection performance than the real-data training sets. We demonstrate our results using the datasets from the EPILEPSIAE Project, one of the world's largest public databases for seizure detection.