 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOf Non-Linearity and Commutativity in BERT
Jan 14, 2021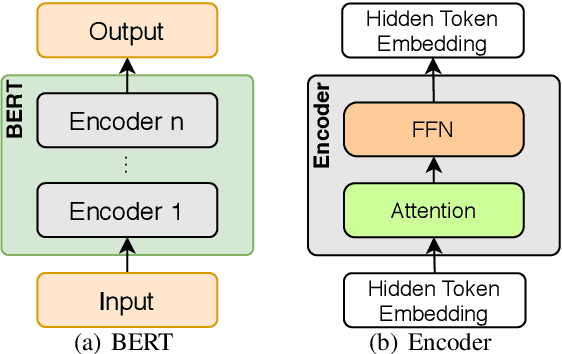
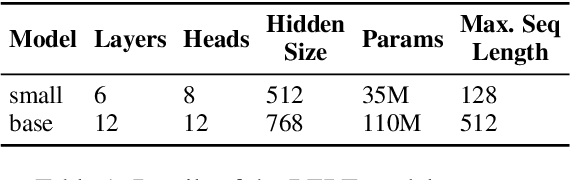
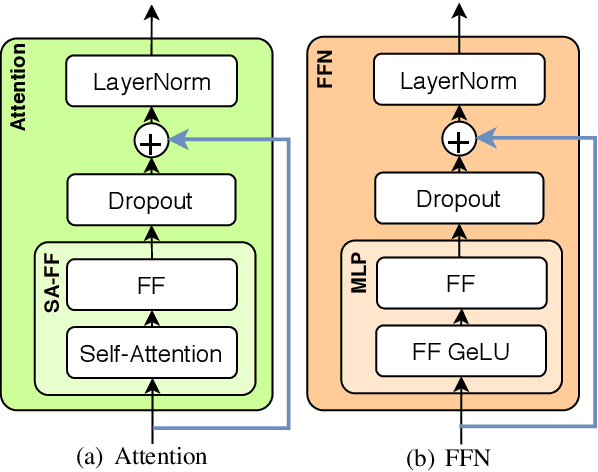
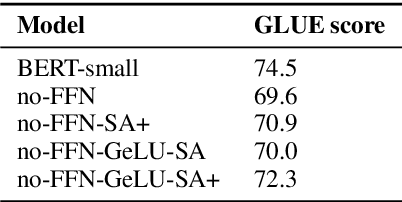
In this work we provide new insights into the transformer architecture, and in particular, its best-known variant, BERT. First, we propose a method to measure the degree of non-linearity of different elements of transformers. Next, we focus our investigation on the feed-forward networks (FFN) inside transformers, which contain 2/3 of the model parameters and have so far not received much attention. We find that FFNs are an inefficient yet important architectural element and that they cannot simply be replaced by attention blocks without a degradation in performance. Moreover, we study the interactions between layers in BERT and show that, while the layers exhibit some hierarchical structure, they extract features in a fuzzy manner. Our results suggest that BERT has an inductive bias towards layer commutativity, which we find is mainly due to the skip connections. This provides a justification for the strong performance of recurrent and weight-shared transformer models.
Symbolic Music Genre Transfer with CycleGAN
Sep 20, 2018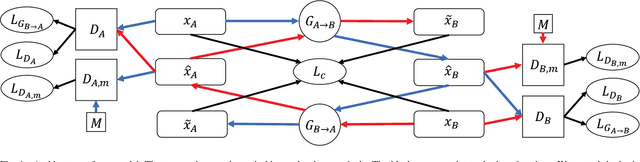
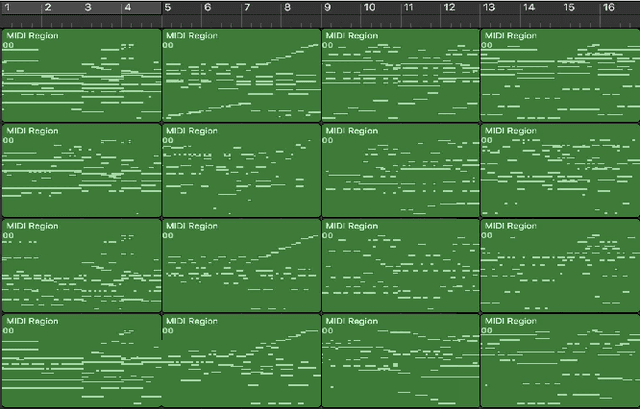

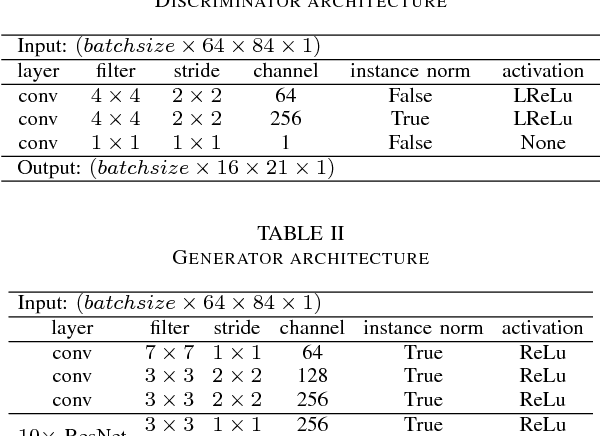
Deep generative models such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) have recently been applied to style and domain transfer for images, and in the case of VAEs, music. GAN-based models employing several generators and some form of cycle consistency loss have been among the most successful for image domain transfer. In this paper we apply such a model to symbolic music and show the feasibility of our approach for music genre transfer. Evaluations using separate genre classifiers show that the style transfer works well. In order to improve the fidelity of the transformed music, we add additional discriminators that cause the generators to keep the structure of the original music mostly intact, while still achieving strong genre transfer. Visual and audible results further show the potential of our approach. To the best of our knowledge, this paper represents the first application of GANs to symbolic music domain transfer.