 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOf Non-Linearity and Commutativity in BERT
Jan 14, 2021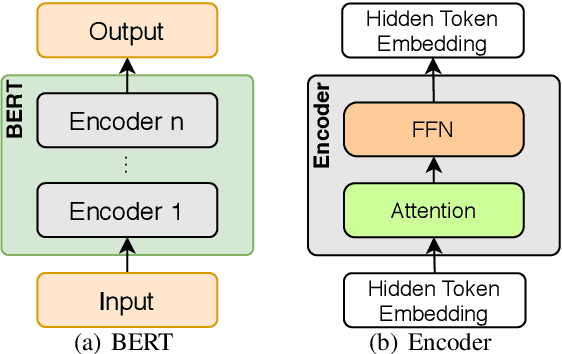
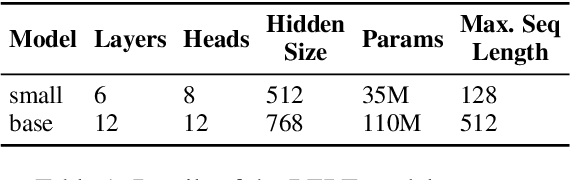
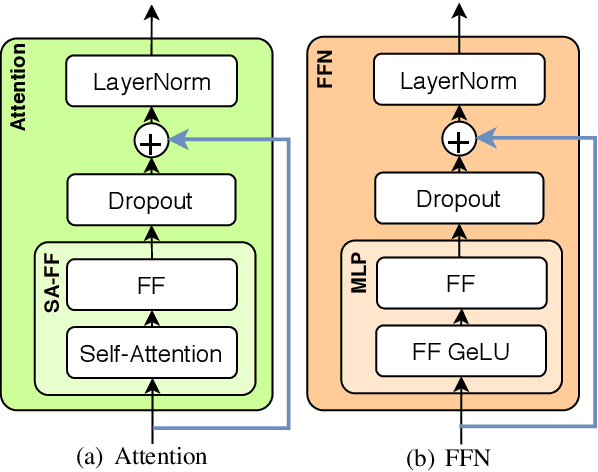
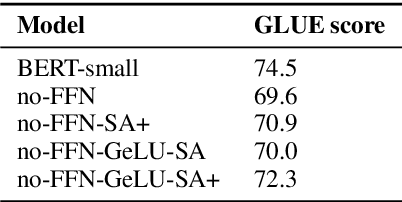
In this work we provide new insights into the transformer architecture, and in particular, its best-known variant, BERT. First, we propose a method to measure the degree of non-linearity of different elements of transformers. Next, we focus our investigation on the feed-forward networks (FFN) inside transformers, which contain 2/3 of the model parameters and have so far not received much attention. We find that FFNs are an inefficient yet important architectural element and that they cannot simply be replaced by attention blocks without a degradation in performance. Moreover, we study the interactions between layers in BERT and show that, while the layers exhibit some hierarchical structure, they extract features in a fuzzy manner. Our results suggest that BERT has an inductive bias towards layer commutativity, which we find is mainly due to the skip connections. This provides a justification for the strong performance of recurrent and weight-shared transformer models.
Medley2K: A Dataset of Medley Transitions
Aug 25, 2020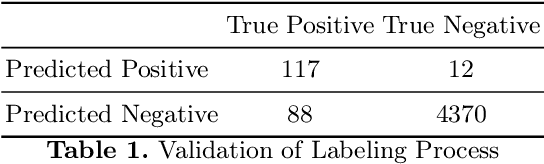
The automatic generation of medleys, i.e., musical pieces formed by different songs concatenated via smooth transitions, is not well studied in the current literature. To facilitate research on this topic, we make available a dataset called Medley2K that consists of 2,000 medleys and 7,712 labeled transitions. Our dataset features a rich variety of song transitions across different music genres. We provide a detailed description of this dataset and validate it by training a state-of-the-art generative model in the task of generating transitions between songs.
Telling BERT's full story: from Local Attention to Global Aggregation
Apr 10, 2020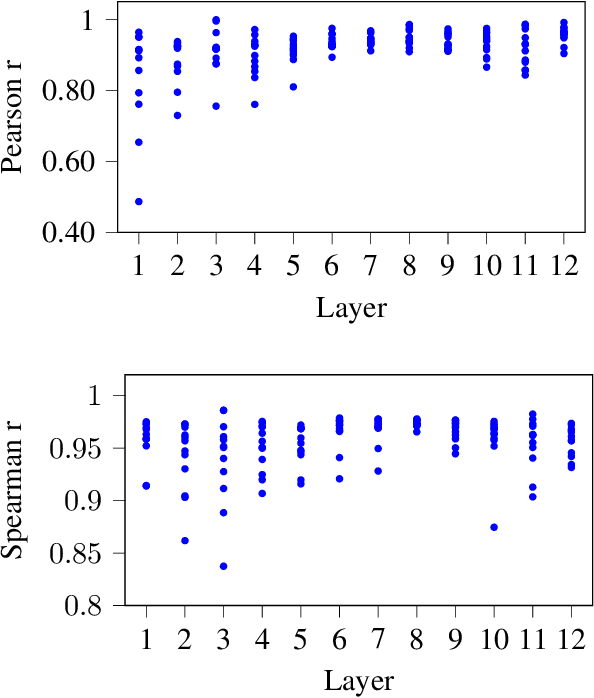
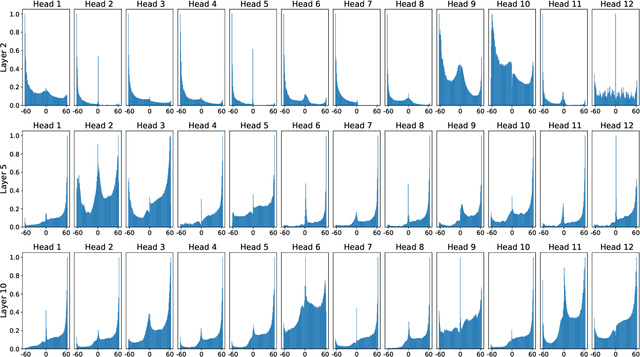
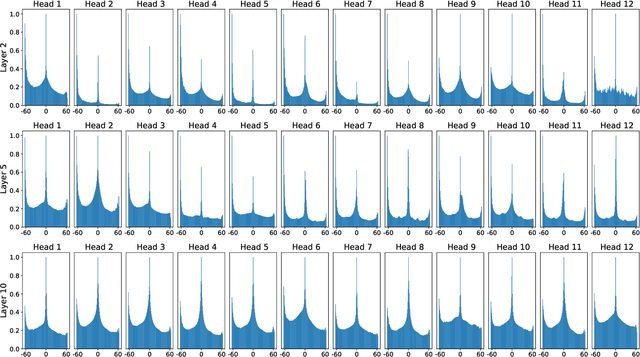
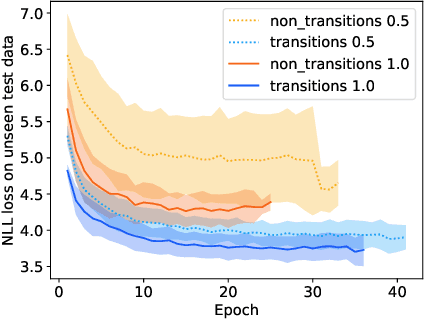
We take a deep look into the behavior of self-attention heads in the transformer architecture. In light of recent work discouraging the use of attention distributions for explaining a model's behavior, we show that attention distributions can nevertheless provide insights into the local behavior of attention heads. This way, we propose a distinction between local patterns revealed by attention and global patterns that refer back to the input, and analyze BERT from both angles. We use gradient attribution to analyze how the output of an attention attention head depends on the input tokens, effectively extending the local attention-based analysis to account for the mixing of information throughout the transformer layers. We find that there is a significant discrepancy between attention and attribution distributions, caused by the mixing of context inside the model. We quantify this discrepancy and observe that interestingly, there are some patterns that persist across all layers despite the mixing.
On the Validity of Self-Attention as Explanation in Transformer Models
Aug 12, 2019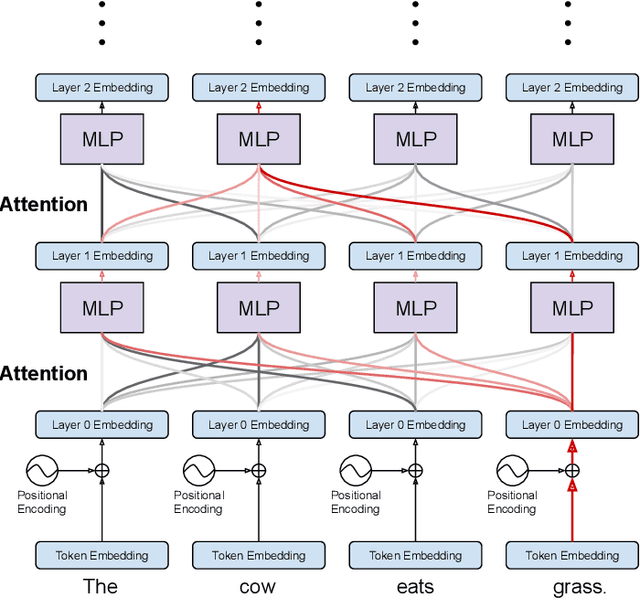
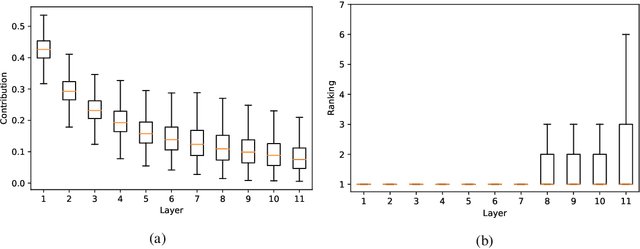
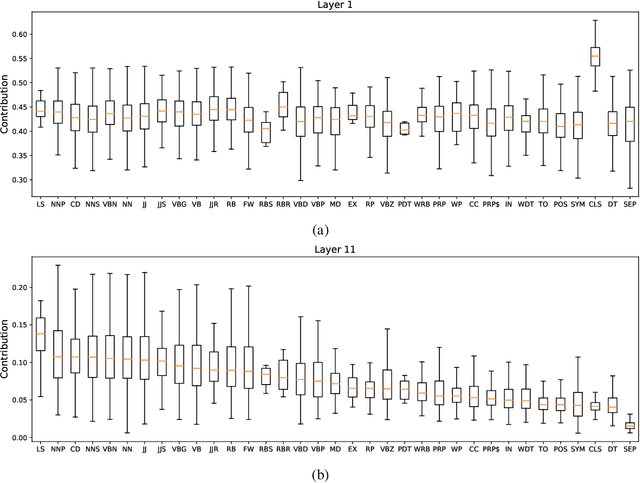
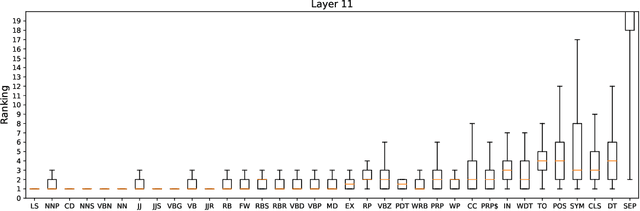
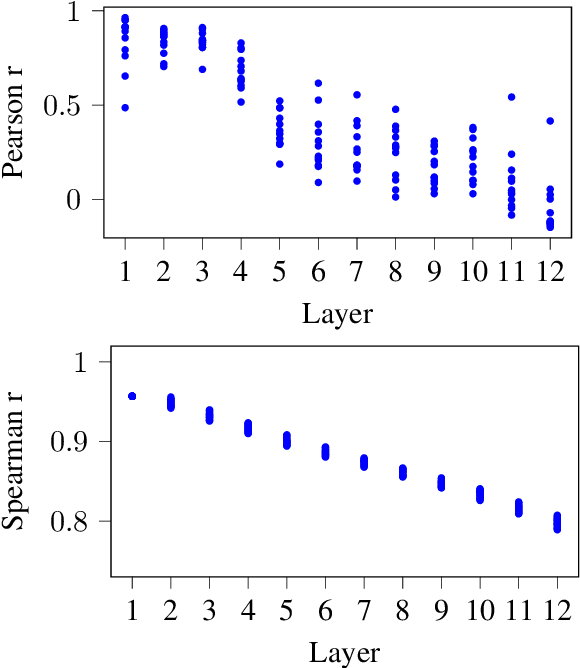
Explainability of deep learning systems is a vital requirement for many applications. However, it is still an unsolved problem. Recent self-attention based models for natural language processing, such as the Transformer or BERT, offer hope of greater explainability by providing attention maps that can be directly inspected. Nevertheless, by just looking at the attention maps one often overlooks that the attention is not over words but over hidden embeddings, which themselves can be mixed representations of multiple embeddings. We investigate to what extent the implicit assumption made in many recent papers - that hidden embeddings at all layers still correspond to the underlying words - is justified. We quantify how much embeddings are mixed based on a gradient based attribution method and find that already after the first layer less than 50% of the embedding is attributed to the underlying word, declining thereafter to a median contribution of 7.5% in the last layer. While throughout the layers the underlying word remains as the one contributing most to the embedding, we argue that attention visualizations are misleading and should be treated with care when explaining the underlying deep learning system.
Attentive Multi-Task Deep Reinforcement Learning
Jul 05, 2019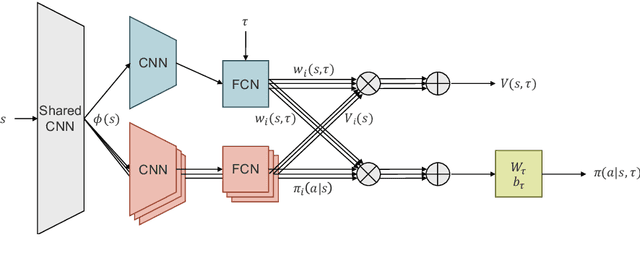


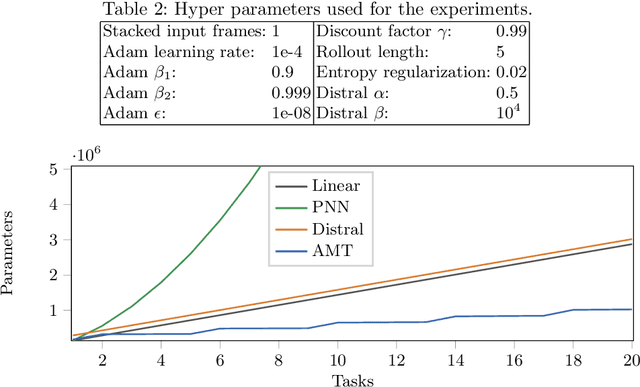
Sharing knowledge between tasks is vital for efficient learning in a multi-task setting. However, most research so far has focused on the easier case where knowledge transfer is not harmful, i.e., where knowledge from one task cannot negatively impact the performance on another task. In contrast, we present an approach to multi-task deep reinforcement learning based on attention that does not require any a-priori assumptions about the relationships between tasks. Our attention network automatically groups task knowledge into sub-networks on a state level granularity. It thereby achieves positive knowledge transfer if possible, and avoids negative transfer in cases where tasks interfere. We test our algorithm against two state-of-the-art multi-task/transfer learning approaches and show comparable or superior performance while requiring fewer network parameters.
Using State Predictions for Value Regularization in Curiosity Driven Deep Reinforcement Learning
Sep 30, 2018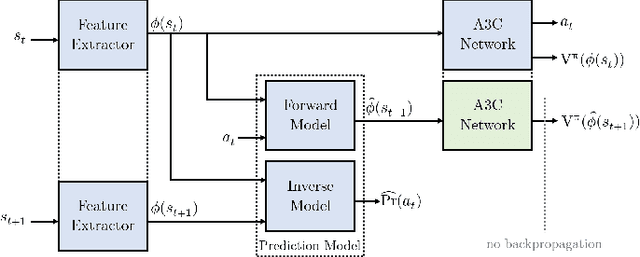
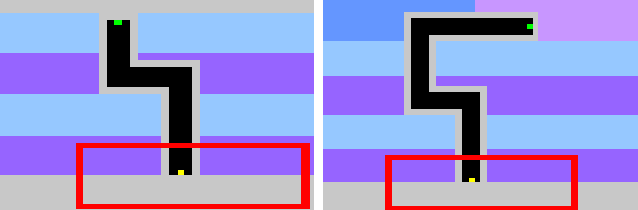
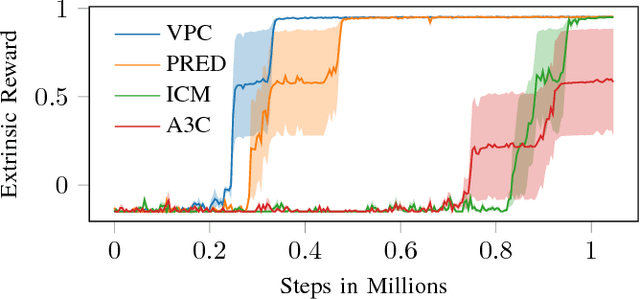
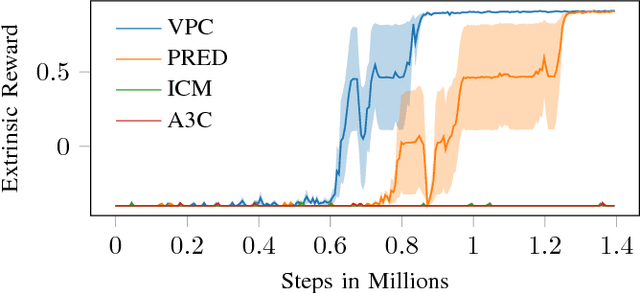
Learning in sparse reward settings remains a challenge in Reinforcement Learning, which is often addressed by using intrinsic rewards. One promising strategy is inspired by human curiosity, requiring the agent to learn to predict the future. In this paper a curiosity-driven agent is extended to use these predictions directly for training. To achieve this, the agent predicts the value function of the next state at any point in time. Subsequently, the consistency of this prediction with the current value function is measured, which is then used as a regularization term in the loss function of the algorithm. Experiments were made on grid-world environments as well as on a 3D navigation task, both with sparse rewards. In the first case the extended agent is able to learn significantly faster than the baselines.
The Urban Last Mile Problem: Autonomous Drone Delivery to Your Balcony
Sep 21, 2018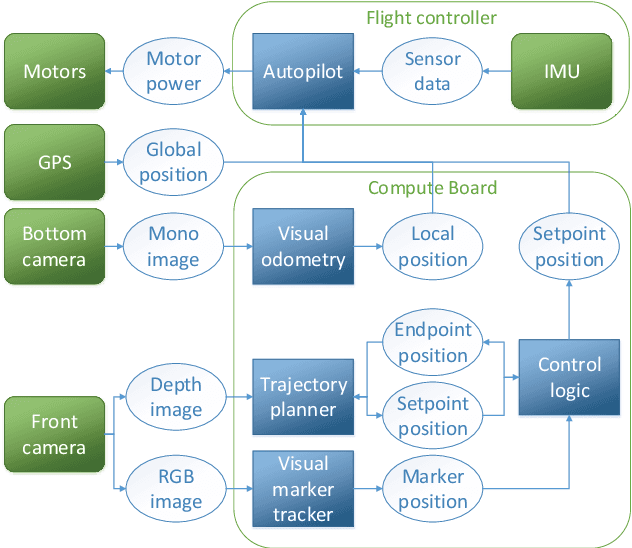
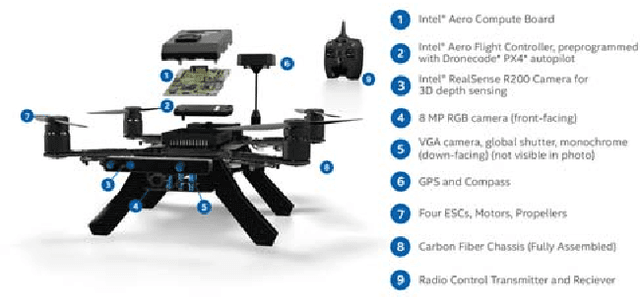
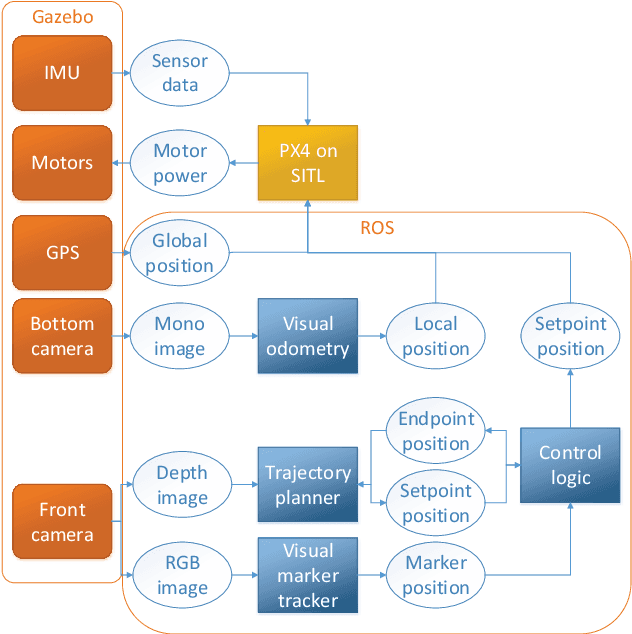

Drone delivery has been a hot topic in the industry in the past few years. However, existing approaches either focus on rural areas or rely on centralized drop-off locations from where the last mile delivery is performed. In this paper we tackle the problem of autonomous last mile delivery in urban environments using an off-the-shelf drone. We build a prototype system that is able to fly to the approximate delivery location using GPS and then find the exact drop-off location using visual navigation. The drop-off location could, e.g., be on a balcony or porch, and simply needs to be indicated by a visual marker on the wall or window. We test our system components in simulated environments, including the visual navigation and collision avoidance. Finally, we deploy our drone in a real-world environment and show how it can find the drop-off point on a balcony. To stimulate future research in this topic we open source our code.
MIDI-VAE: Modeling Dynamics and Instrumentation of Music with Applications to Style Transfer
Sep 20, 2018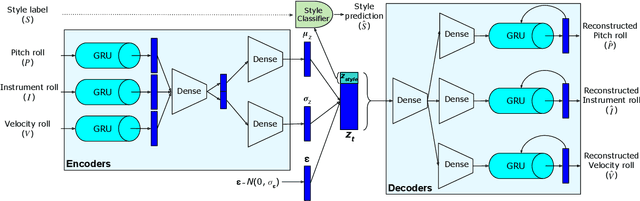
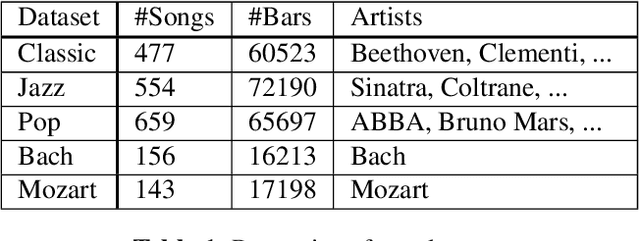
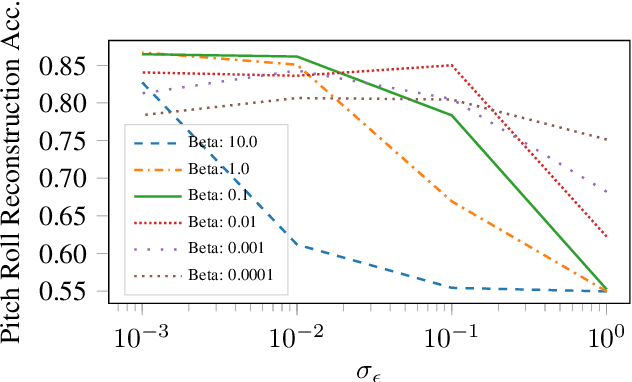
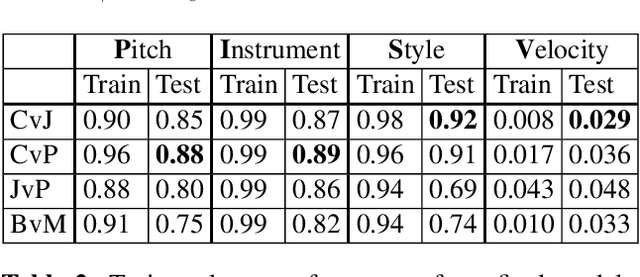
We introduce MIDI-VAE, a neural network model based on Variational Autoencoders that is capable of handling polyphonic music with multiple instrument tracks, as well as modeling the dynamics of music by incorporating note durations and velocities. We show that MIDI-VAE can perform style transfer on symbolic music by automatically changing pitches, dynamics and instruments of a music piece from, e.g., a Classical to a Jazz style. We evaluate the efficacy of the style transfer by training separate style validation classifiers. Our model can also interpolate between short pieces of music, produce medleys and create mixtures of entire songs. The interpolations smoothly change pitches, dynamics and instrumentation to create a harmonic bridge between two music pieces. To the best of our knowledge, this work represents the first successful attempt at applying neural style transfer to complete musical compositions.
Symbolic Music Genre Transfer with CycleGAN
Sep 20, 2018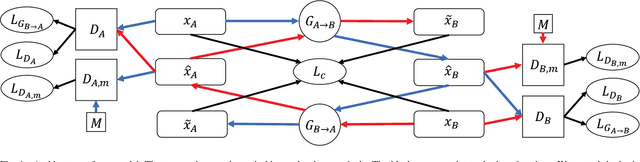
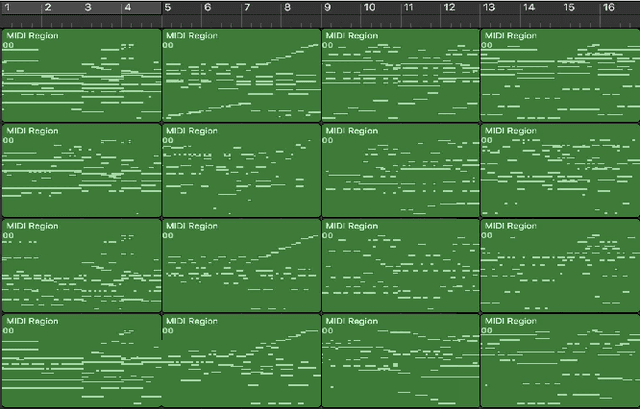

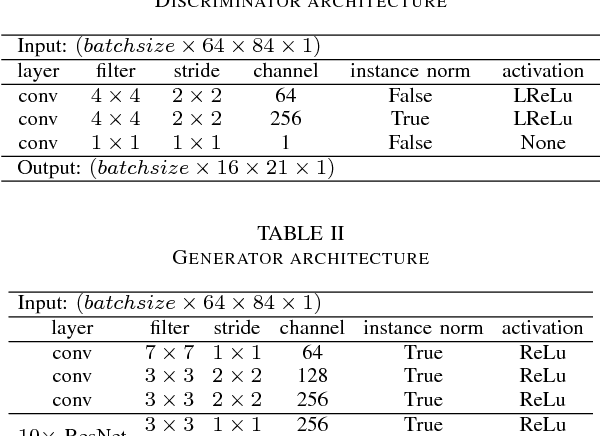
Deep generative models such as Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs) have recently been applied to style and domain transfer for images, and in the case of VAEs, music. GAN-based models employing several generators and some form of cycle consistency loss have been among the most successful for image domain transfer. In this paper we apply such a model to symbolic music and show the feasibility of our approach for music genre transfer. Evaluations using separate genre classifiers show that the style transfer works well. In order to improve the fidelity of the transformed music, we add additional discriminators that cause the generators to keep the structure of the original music mostly intact, while still achieving strong genre transfer. Visual and audible results further show the potential of our approach. To the best of our knowledge, this paper represents the first application of GANs to symbolic music domain transfer.
Natural Language Multitasking: Analyzing and Improving Syntactic Saliency of Hidden Representations
Jan 18, 2018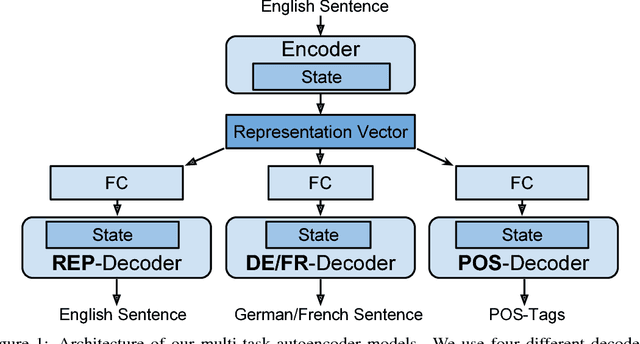
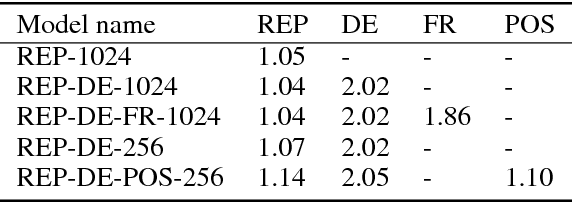


We train multi-task autoencoders on linguistic tasks and analyze the learned hidden sentence representations. The representations change significantly when translation and part-of-speech decoders are added. The more decoders a model employs, the better it clusters sentences according to their syntactic similarity, as the representation space becomes less entangled. We explore the structure of the representation space by interpolating between sentences, which yields interesting pseudo-English sentences, many of which have recognizable syntactic structure. Lastly, we point out an interesting property of our models: The difference-vector between two sentences can be added to change a third sentence with similar features in a meaningful way.