 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEGEyeNet: a Simultaneous Electroencephalography and Eye-tracking Dataset and Benchmark for Eye Movement Prediction
Nov 10, 2021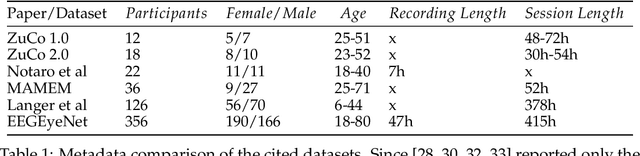
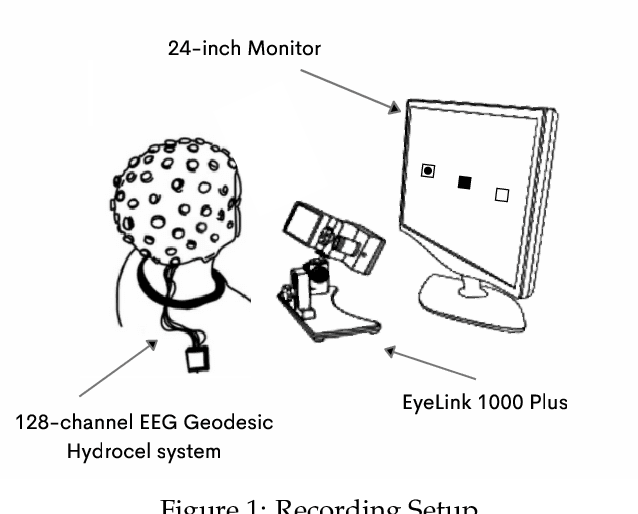
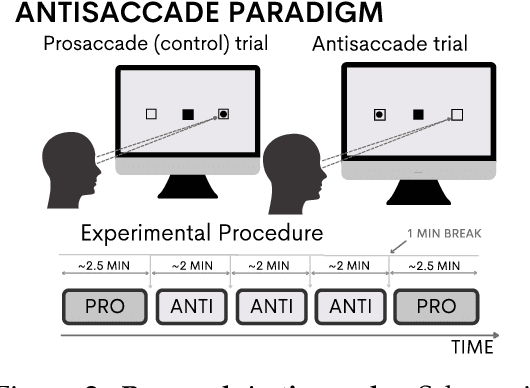
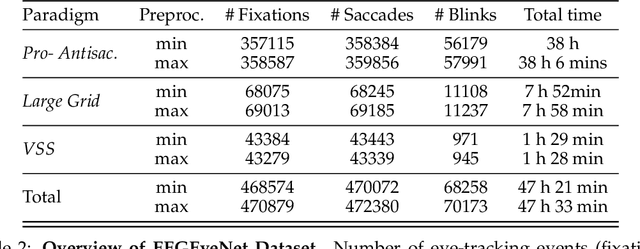
We present a new dataset and benchmark with the goal of advancing research in the intersection of brain activities and eye movements. Our dataset, EEGEyeNet, consists of simultaneous Electroencephalography (EEG) and Eye-tracking (ET) recordings from 356 different subjects collected from three different experimental paradigms. Using this dataset, we also propose a benchmark to evaluate gaze prediction from EEG measurements. The benchmark consists of three tasks with an increasing level of difficulty: left-right, angle-amplitude and absolute position. We run extensive experiments on this benchmark in order to provide solid baselines, both based on classical machine learning models and on large neural networks. We release our complete code and data and provide a simple and easy-to-use interface to evaluate new methods.
BERT is Robust! A Case Against Synonym-Based Adversarial Examples in Text Classification
Sep 15, 2021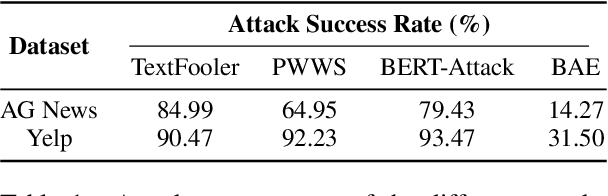
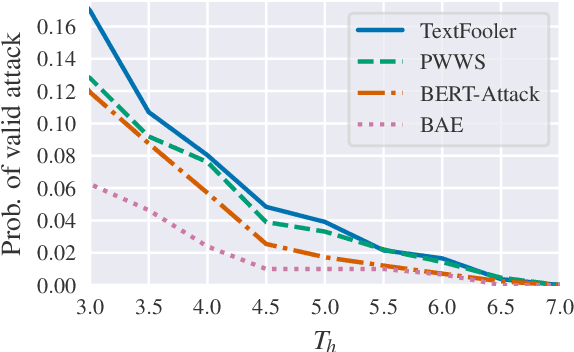

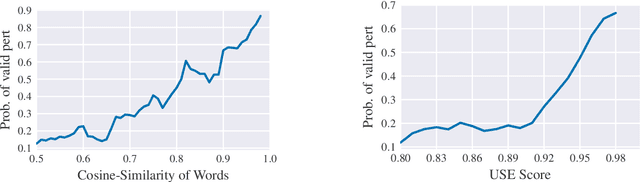
Deep Neural Networks have taken Natural Language Processing by storm. While this led to incredible improvements across many tasks, it also initiated a new research field, questioning the robustness of these neural networks by attacking them. In this paper, we investigate four word substitution-based attacks on BERT. We combine a human evaluation of individual word substitutions and a probabilistic analysis to show that between 96% and 99% of the analyzed attacks do not preserve semantics, indicating that their success is mainly based on feeding poor data to the model. To further confirm that, we introduce an efficient data augmentation procedure and show that many adversarial examples can be prevented by including data similar to the attacks during training. An additional post-processing step reduces the success rates of state-of-the-art attacks below 5%. Finally, by looking at more reasonable thresholds on constraints for word substitutions, we conclude that BERT is a lot more robust than research on attacks suggests.
On the Validity of Self-Attention as Explanation in Transformer Models
Aug 12, 2019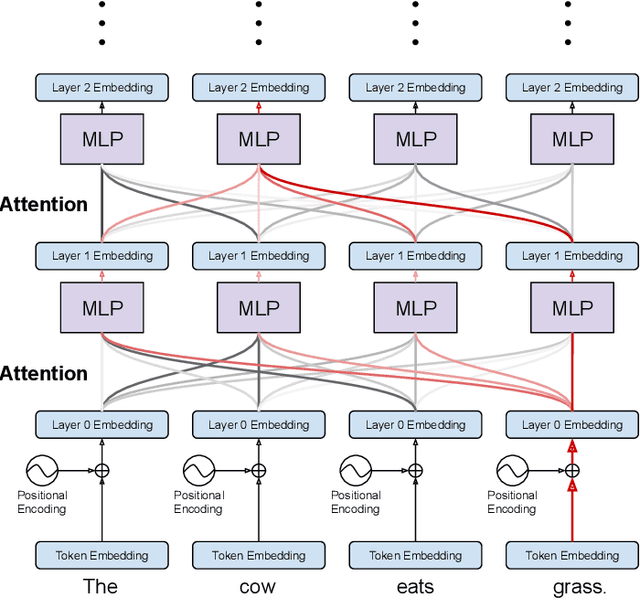
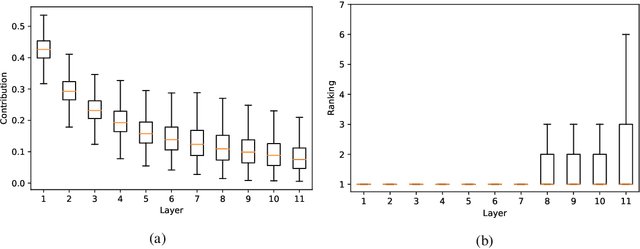
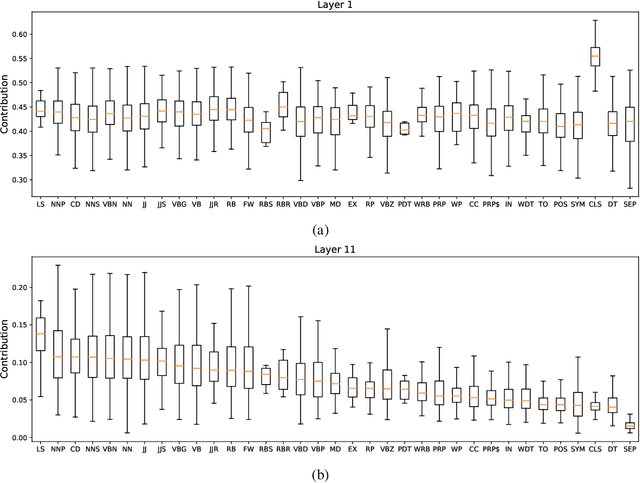
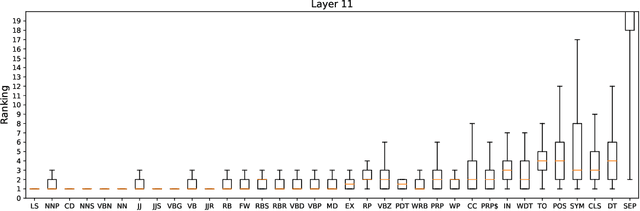
Explainability of deep learning systems is a vital requirement for many applications. However, it is still an unsolved problem. Recent self-attention based models for natural language processing, such as the Transformer or BERT, offer hope of greater explainability by providing attention maps that can be directly inspected. Nevertheless, by just looking at the attention maps one often overlooks that the attention is not over words but over hidden embeddings, which themselves can be mixed representations of multiple embeddings. We investigate to what extent the implicit assumption made in many recent papers - that hidden embeddings at all layers still correspond to the underlying words - is justified. We quantify how much embeddings are mixed based on a gradient based attribution method and find that already after the first layer less than 50% of the embedding is attributed to the underlying word, declining thereafter to a median contribution of 7.5% in the last layer. While throughout the layers the underlying word remains as the one contributing most to the embedding, we argue that attention visualizations are misleading and should be treated with care when explaining the underlying deep learning system.