 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Rigid Origami Design
Nov 20, 2022



While rigid origami has shown potential in a large diversity of engineering applications, current rigid origami crease pattern designs mostly rely on known tessellations. This leaves a potential gap in performance as the space of rigidly foldable crease patterns is far larger than these tessellations would suggest. In this work, we build upon the recently developed principle of three units method to formulate rigid origami design as a discrete optimization problem. Our implementation allows for a simple definition of diverse objectives and thereby expands the potential of rigid origami further to optimized, application-specific crease patterns. We benchmark a diverse set of search methods in several shape approximation tasks to validate our model and showcase the flexibility of our formulation through four illustrative case studies. Results show that using our proposed problem formulation one can successfully approximate a variety of target shapes. Moreover, by specifying custom reward functions, we can find patterns, which result in novel, foldable designs for everyday objects.
Normalized Attention Without Probability Cage
May 19, 2020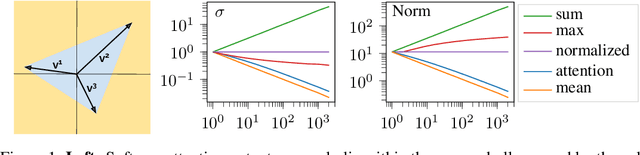
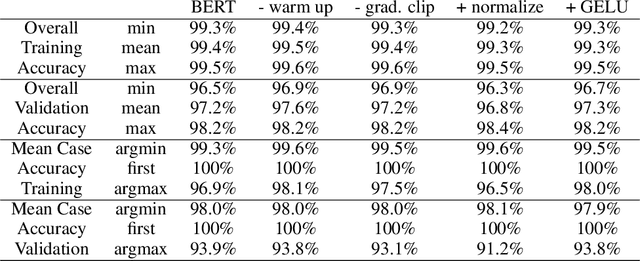
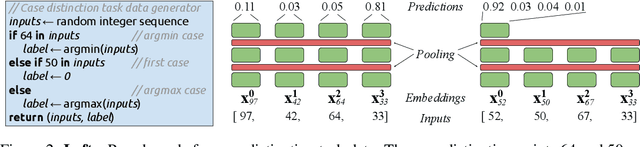

Attention architectures are widely used; they recently gained renewed popularity with Transformers yielding a streak of state of the art results. Yet, the geometrical implications of softmax-attention remain largely unexplored. In this work we highlight the limitations of constraining attention weights to the probability simplex and the resulting convex hull of value vectors. We show that Transformers are sequence length dependent biased towards token isolation at initialization and contrast Transformers to simple max- and sum-pooling - two strong baselines rarely reported. We propose to replace the softmax in self-attention with normalization, yielding a hyperparameter and data-bias robust, generally applicable architecture. We support our insights with empirical results from more than 25,000 trained models. All results and implementations are made available.
On the Validity of Self-Attention as Explanation in Transformer Models
Aug 12, 2019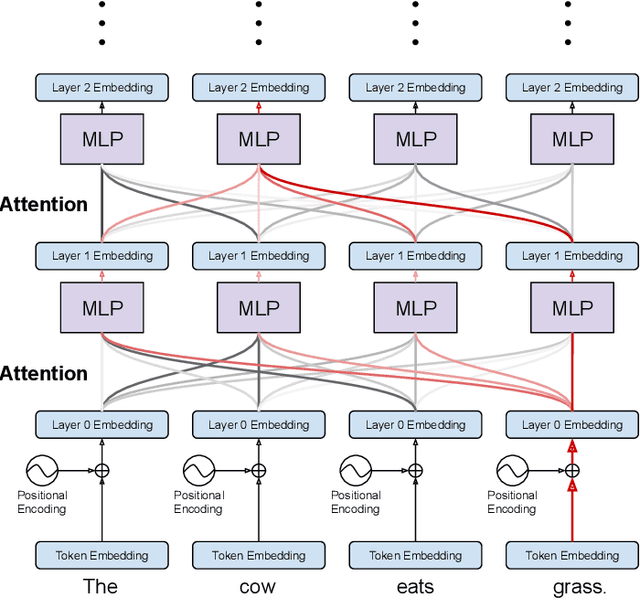
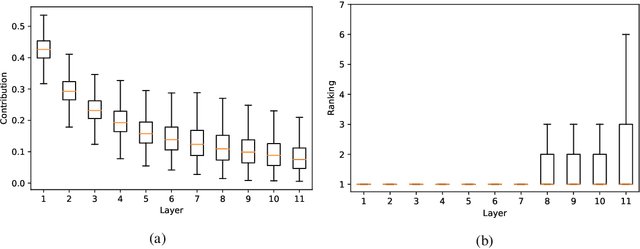
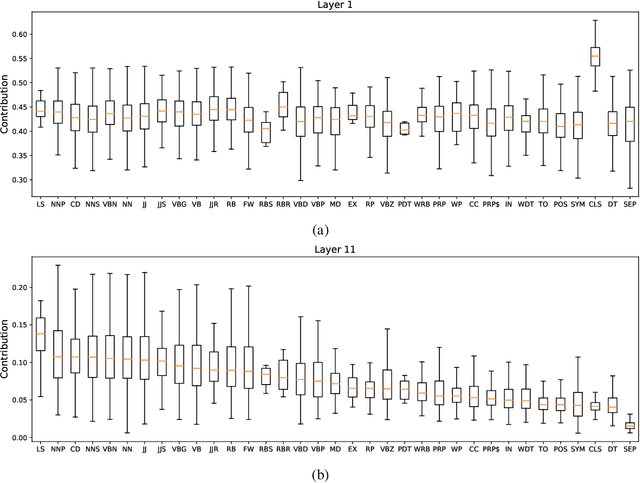
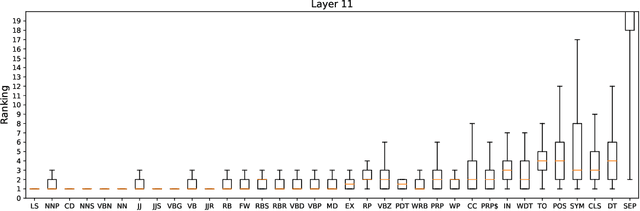
Explainability of deep learning systems is a vital requirement for many applications. However, it is still an unsolved problem. Recent self-attention based models for natural language processing, such as the Transformer or BERT, offer hope of greater explainability by providing attention maps that can be directly inspected. Nevertheless, by just looking at the attention maps one often overlooks that the attention is not over words but over hidden embeddings, which themselves can be mixed representations of multiple embeddings. We investigate to what extent the implicit assumption made in many recent papers - that hidden embeddings at all layers still correspond to the underlying words - is justified. We quantify how much embeddings are mixed based on a gradient based attribution method and find that already after the first layer less than 50% of the embedding is attributed to the underlying word, declining thereafter to a median contribution of 7.5% in the last layer. While throughout the layers the underlying word remains as the one contributing most to the embedding, we argue that attention visualizations are misleading and should be treated with care when explaining the underlying deep learning system.
Attentive Multi-Task Deep Reinforcement Learning
Jul 05, 2019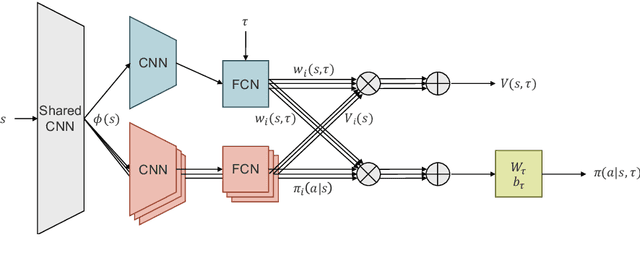


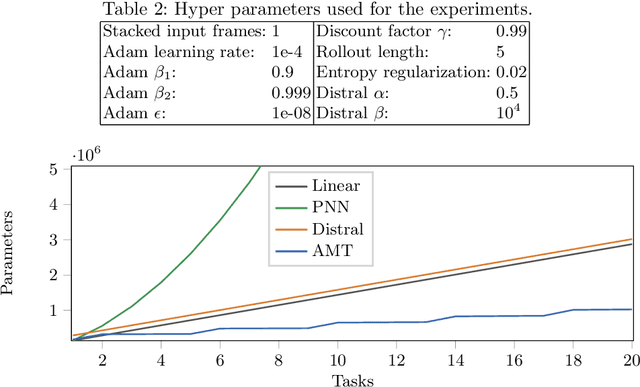
Sharing knowledge between tasks is vital for efficient learning in a multi-task setting. However, most research so far has focused on the easier case where knowledge transfer is not harmful, i.e., where knowledge from one task cannot negatively impact the performance on another task. In contrast, we present an approach to multi-task deep reinforcement learning based on attention that does not require any a-priori assumptions about the relationships between tasks. Our attention network automatically groups task knowledge into sub-networks on a state level granularity. It thereby achieves positive knowledge transfer if possible, and avoids negative transfer in cases where tasks interfere. We test our algorithm against two state-of-the-art multi-task/transfer learning approaches and show comparable or superior performance while requiring fewer network parameters.
Quantile Regression Deep Reinforcement Learning
Jun 27, 2019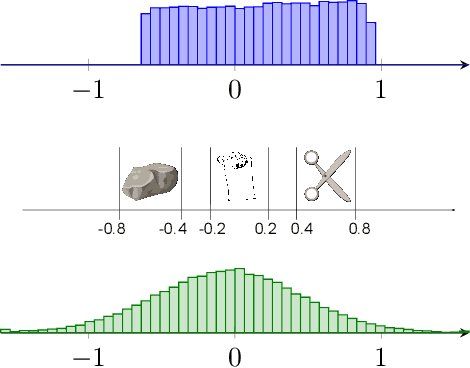
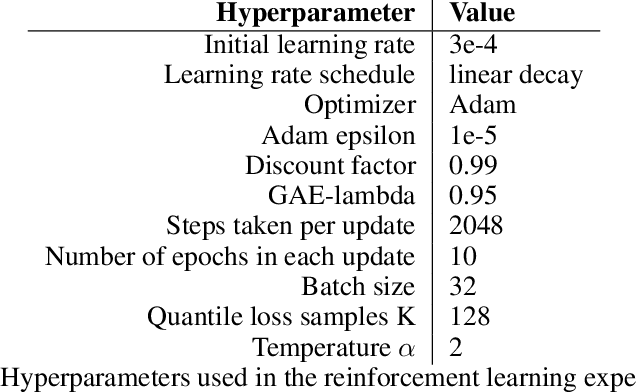
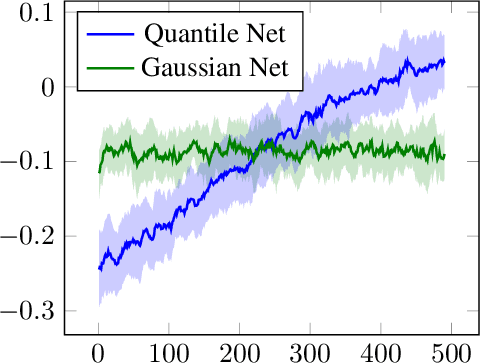
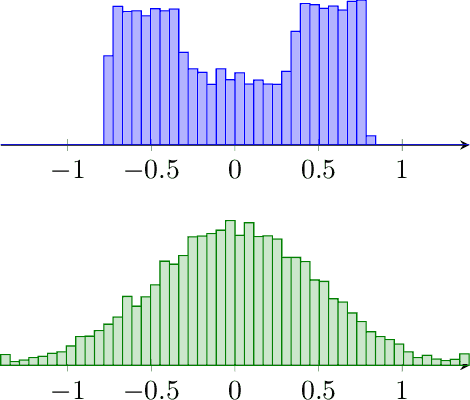
Policy gradient based reinforcement learning algorithms coupled with neural networks have shown success in learning complex policies in the model free continuous action space control setting. However, explicitly parameterized policies are limited by the scope of the chosen parametric probability distribution. We show that alternatively to the likelihood based policy gradient, a related objective can be optimized through advantage weighted quantile regression. Our approach models the policy implicitly in the network, which gives the agent the freedom to approximate any distribution in each action dimension, not limiting its capabilities to the commonly used unimodal Gaussian parameterization. This broader spectrum of policies makes our algorithm suitable for problems where Gaussian policies cannot fit the optimal policy. Moreover, our results on the MuJoCo physics simulator benchmarks are comparable or superior to state-of-the-art on-policy methods.
Using State Predictions for Value Regularization in Curiosity Driven Deep Reinforcement Learning
Sep 30, 2018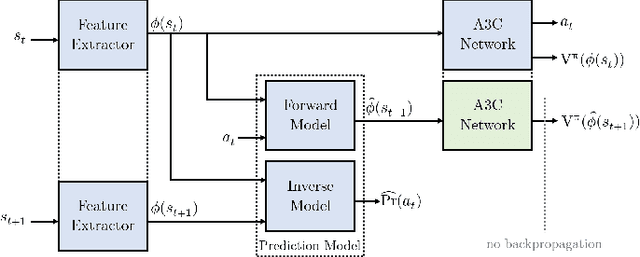
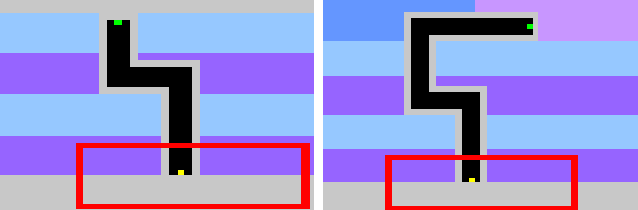
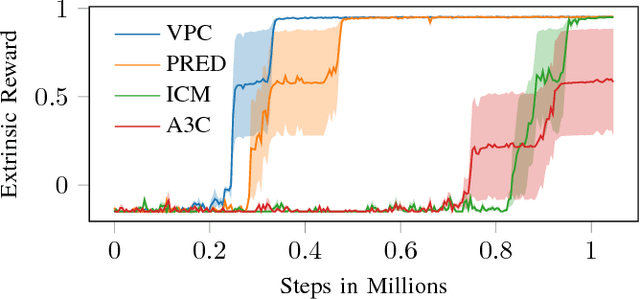
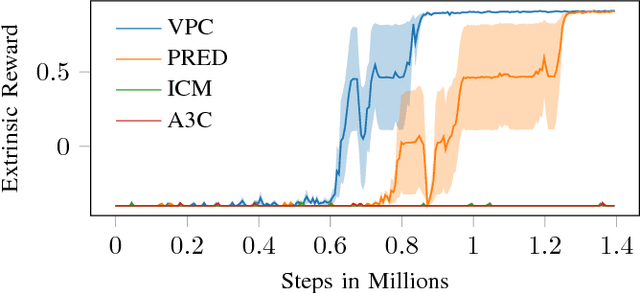
Learning in sparse reward settings remains a challenge in Reinforcement Learning, which is often addressed by using intrinsic rewards. One promising strategy is inspired by human curiosity, requiring the agent to learn to predict the future. In this paper a curiosity-driven agent is extended to use these predictions directly for training. To achieve this, the agent predicts the value function of the next state at any point in time. Subsequently, the consistency of this prediction with the current value function is measured, which is then used as a regularization term in the loss function of the algorithm. Experiments were made on grid-world environments as well as on a 3D navigation task, both with sparse rewards. In the first case the extended agent is able to learn significantly faster than the baselines.
Teaching a Machine to Read Maps with Deep Reinforcement Learning
Nov 20, 2017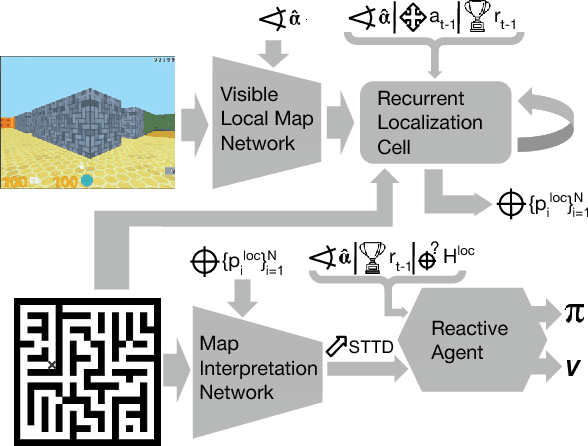
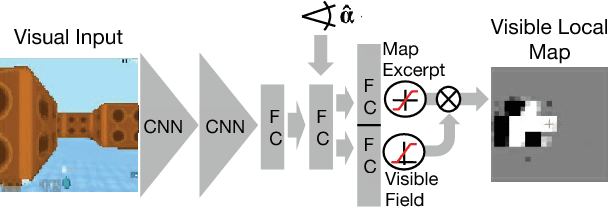
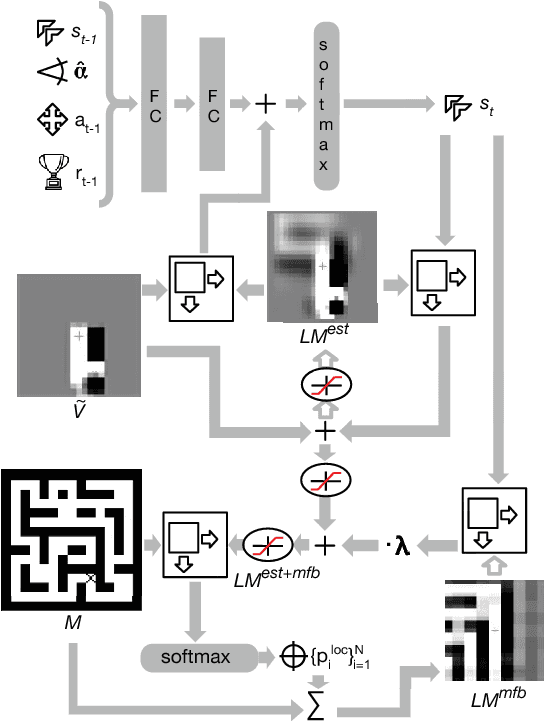
The ability to use a 2D map to navigate a complex 3D environment is quite remarkable, and even difficult for many humans. Localization and navigation is also an important problem in domains such as robotics, and has recently become a focus of the deep reinforcement learning community. In this paper we teach a reinforcement learning agent to read a map in order to find the shortest way out of a random maze it has never seen before. Our system combines several state-of-the-art methods such as A3C and incorporates novel elements such as a recurrent localization cell. Our agent learns to localize itself based on 3D first person images and an approximate orientation angle. The agent generalizes well to bigger mazes, showing that it learned useful localization and navigation capabilities.