 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIM 2019 Challenge on Real-World Image Super-Resolution: Methods and Results
Nov 19, 2019
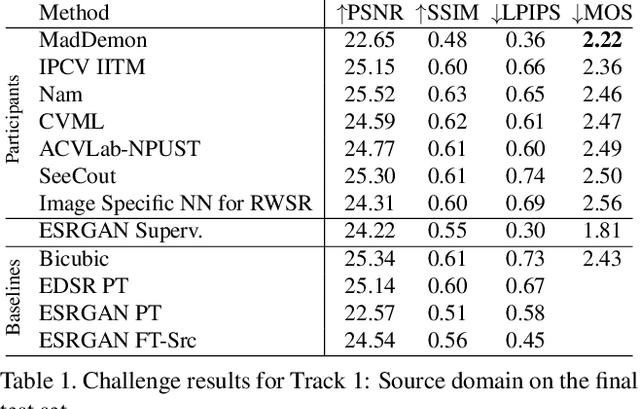
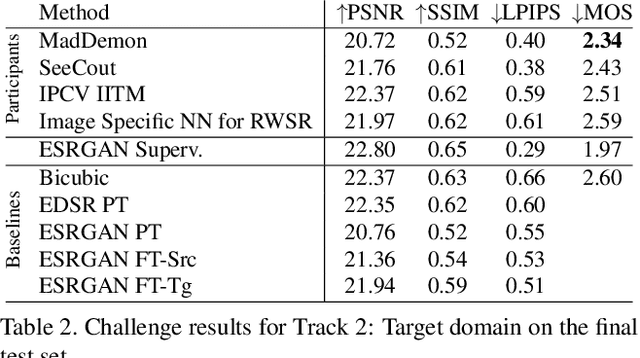

This paper reviews the AIM 2019 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided in the challenge. In Track 1: Source Domain the aim is to super-resolve such images while preserving the low level image characteristics of the source input domain. In Track 2: Target Domain a set of high-quality images is also provided for training, that defines the output domain and desired quality of the super-resolved images. To allow for quantitative evaluation, the source input images in both tracks are constructed using artificial, but realistic, image degradations. The challenge is the first of its kind, aiming to advance the state-of-the-art and provide a standard benchmark for this newly emerging task. In total 7 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
Frequency Separation for Real-World Super-Resolution
Nov 18, 2019
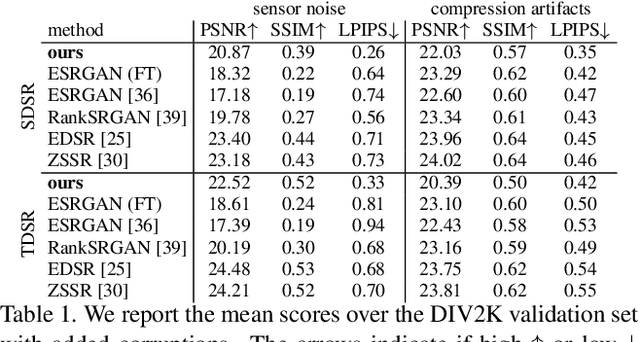

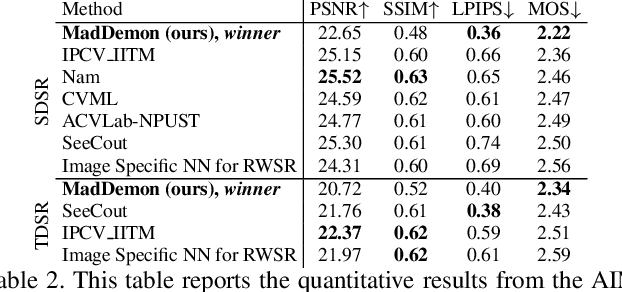
Most of the recent literature on image super-resolution (SR) assumes the availability of training data in the form of paired low resolution (LR) and high resolution (HR) images or the knowledge of the downgrading operator (usually bicubic downscaling). While the proposed methods perform well on standard benchmarks, they often fail to produce convincing results in real-world settings. This is because real-world images can be subject to corruptions such as sensor noise, which are severely altered by bicubic downscaling. Therefore, the models never see a real-world image during training, which limits their generalization capabilities. Moreover, it is cumbersome to collect paired LR and HR images in the same source domain. To address this problem, we propose DSGAN to introduce natural image characteristics in bicubically downscaled images. It can be trained in an unsupervised fashion on HR images, thereby generating LR images with the same characteristics as the original images. We then use the generated data to train a SR model, which greatly improves its performance on real-world images. Furthermore, we propose to separate the low and high image frequencies and treat them differently during training. Since the low frequencies are preserved by downsampling operations, we only require adversarial training to modify the high frequencies. This idea is applied to our DSGAN model as well as the SR model. We demonstrate the effectiveness of our method in several experiments through quantitative and qualitative analysis. Our solution is the winner of the AIM Challenge on Real World SR at ICCV 2019.
Efficient Smoothing of Dilated Convolutions for Image Segmentation
Mar 19, 2019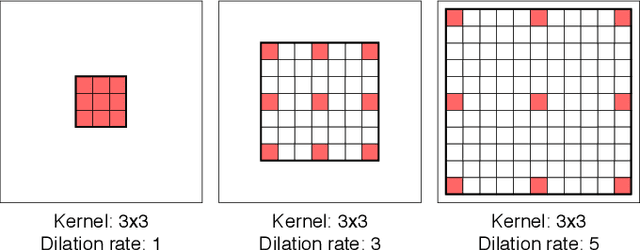
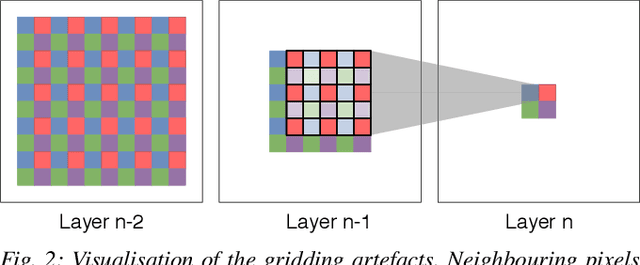
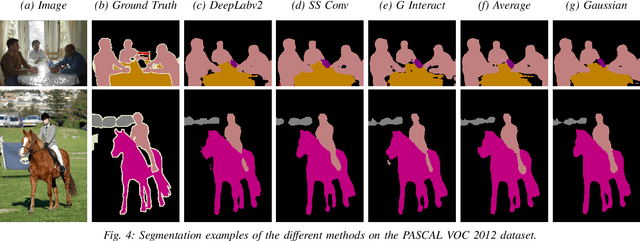
Dilated Convolutions have been shown to be highly useful for the task of image segmentation. By introducing gaps into convolutional filters, they enable the use of larger receptive fields without increasing the original kernel size. Even though this allows for the inexpensive capturing of features at different scales, the structure of the dilated convolutional filter leads to a loss of information. We hypothesise that inexpensive modifications to Dilated Convolutional Neural Networks, such as additional averaging layers, could overcome this limitation. In this project we test this hypothesis by evaluating the effect of these modifications for a state-of-the art image segmentation system and compare them to existing approaches with the same objective. Our experiments show that our proposed methods improve the performance of dilated convolutions for image segmentation. Crucially, our modifications achieve these results at a much lower computational cost than previous smoothing approaches.
Using State Predictions for Value Regularization in Curiosity Driven Deep Reinforcement Learning
Sep 30, 2018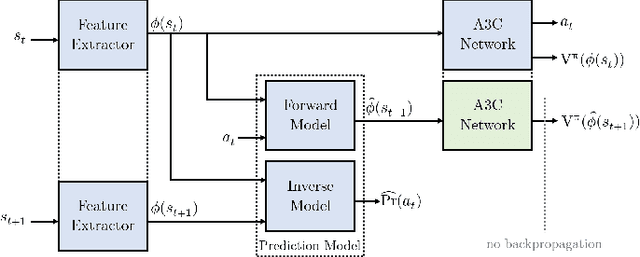
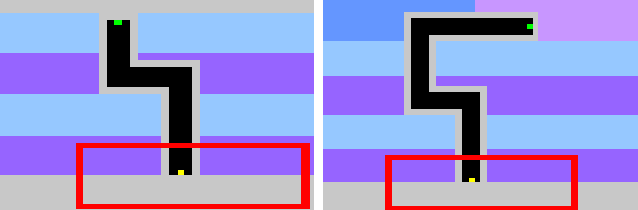
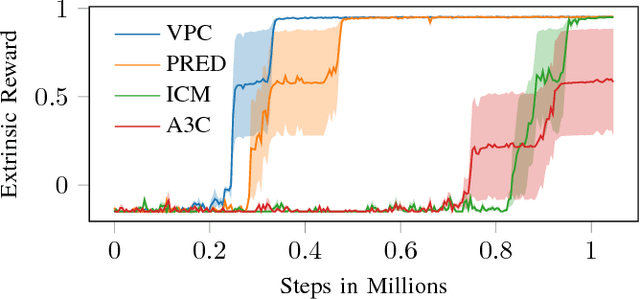
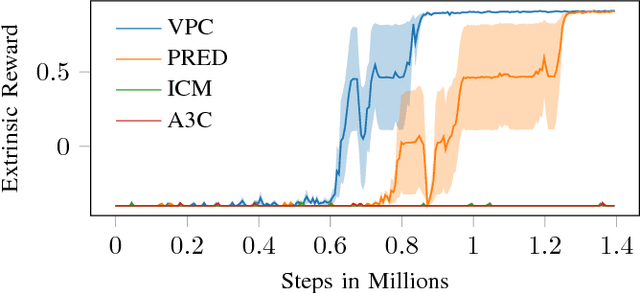
Learning in sparse reward settings remains a challenge in Reinforcement Learning, which is often addressed by using intrinsic rewards. One promising strategy is inspired by human curiosity, requiring the agent to learn to predict the future. In this paper a curiosity-driven agent is extended to use these predictions directly for training. To achieve this, the agent predicts the value function of the next state at any point in time. Subsequently, the consistency of this prediction with the current value function is measured, which is then used as a regularization term in the loss function of the algorithm. Experiments were made on grid-world environments as well as on a 3D navigation task, both with sparse rewards. In the first case the extended agent is able to learn significantly faster than the baselines.