 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation
Feb 21, 2023



We introduce a method to measure uncertainty in large language models. For tasks like question answering, it is essential to know when we can trust the natural language outputs of foundation models. We show that measuring uncertainty in natural language is challenging because of "semantic equivalence" -- different sentences can mean the same thing. To overcome these challenges we introduce semantic entropy -- an entropy which incorporates linguistic invariances created by shared meanings. Our method is unsupervised, uses only a single model, and requires no modifications to off-the-shelf language models. In comprehensive ablation studies we show that the semantic entropy is more predictive of model accuracy on question answering data sets than comparable baselines.
CLAM: Selective Clarification for Ambiguous Questions with Large Language Models
Dec 15, 2022



State-of-the-art language models are often accurate on many question-answering benchmarks with well-defined questions. Yet, in real settings questions are often unanswerable without asking the user for clarifying information. We show that current SotA models often do not ask the user for clarification when presented with imprecise questions and instead provide incorrect answers or "hallucinate". To address this, we introduce CLAM, a framework that first uses the model to detect ambiguous questions, and if an ambiguous question is detected, prompts the model to ask the user for clarification. Furthermore, we show how to construct a scalable and cost-effective automatic evaluation protocol using an oracle language model with privileged information to provide clarifying information. We show that our method achieves a 20.15 percentage point accuracy improvement over SotA on a novel ambiguous question-answering answering data set derived from TriviaQA.
Robustness to Pruning Predicts Generalization in Deep Neural Networks
Mar 10, 2021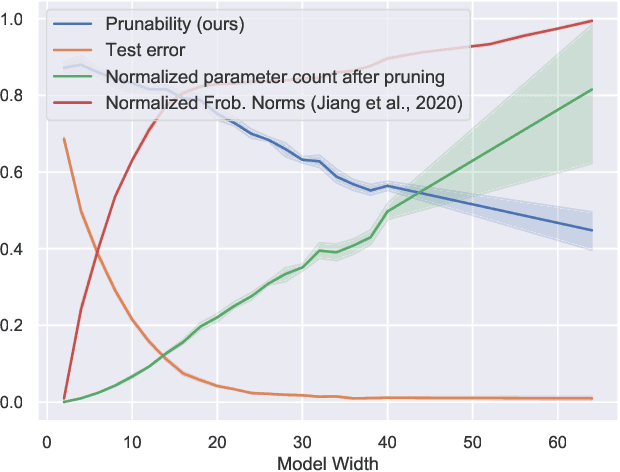
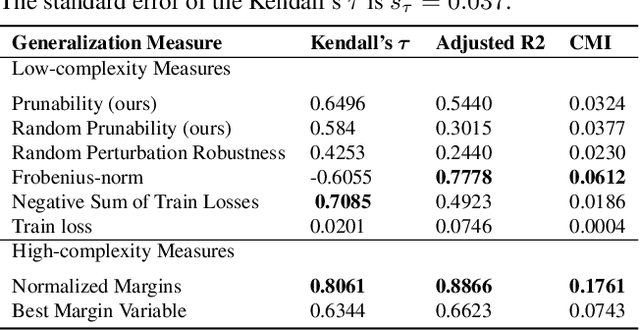
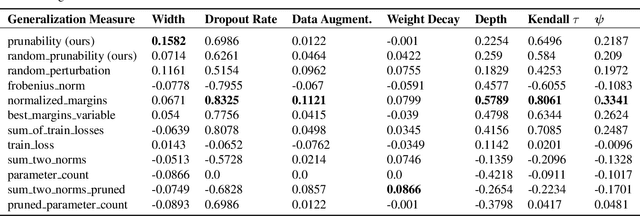
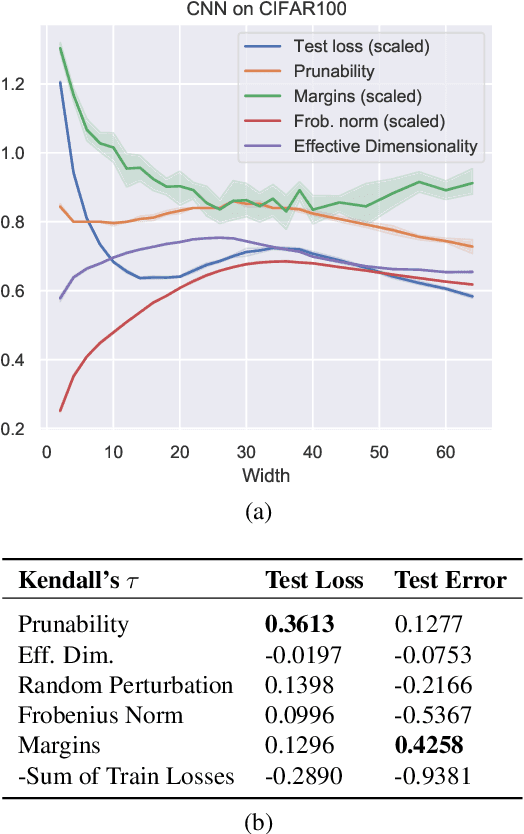
Existing generalization measures that aim to capture a model's simplicity based on parameter counts or norms fail to explain generalization in overparameterized deep neural networks. In this paper, we introduce a new, theoretically motivated measure of a network's simplicity which we call prunability: the smallest \emph{fraction} of the network's parameters that can be kept while pruning without adversely affecting its training loss. We show that this measure is highly predictive of a model's generalization performance across a large set of convolutional networks trained on CIFAR-10, does not grow with network size unlike existing pruning-based measures, and exhibits high correlation with test set loss even in a particularly challenging double descent setting. Lastly, we show that the success of prunability cannot be explained by its relation to known complexity measures based on models' margin, flatness of minima and optimization speed, finding that our new measure is similar to -- but more predictive than -- existing flatness-based measures, and that its predictions exhibit low mutual information with those of other baselines.
Efficient Smoothing of Dilated Convolutions for Image Segmentation
Mar 19, 2019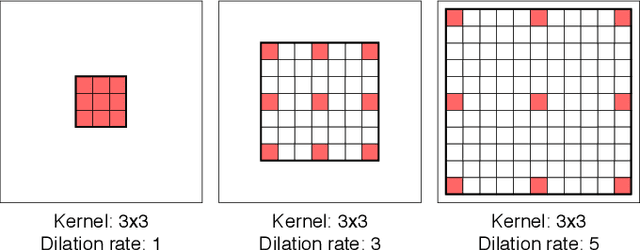
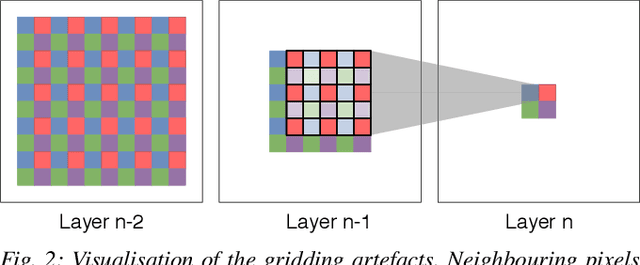
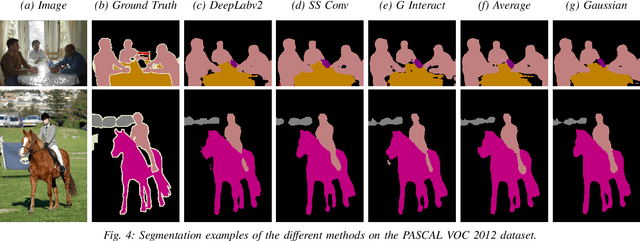
Dilated Convolutions have been shown to be highly useful for the task of image segmentation. By introducing gaps into convolutional filters, they enable the use of larger receptive fields without increasing the original kernel size. Even though this allows for the inexpensive capturing of features at different scales, the structure of the dilated convolutional filter leads to a loss of information. We hypothesise that inexpensive modifications to Dilated Convolutional Neural Networks, such as additional averaging layers, could overcome this limitation. In this project we test this hypothesis by evaluating the effect of these modifications for a state-of-the art image segmentation system and compare them to existing approaches with the same objective. Our experiments show that our proposed methods improve the performance of dilated convolutions for image segmentation. Crucially, our modifications achieve these results at a much lower computational cost than previous smoothing approaches.
Patient Risk Assessment and Warning Symptom Detection Using Deep Attention-Based Neural Networks
Sep 28, 2018
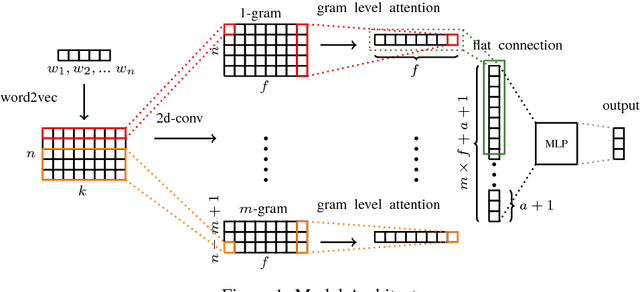


We present an operational component of a real-world patient triage system. Given a specific patient presentation, the system is able to assess the level of medical urgency and issue the most appropriate recommendation in terms of best point of care and time to treat. We use an attention-based convolutional neural network architecture trained on 600,000 doctor notes in German. We compare two approaches, one that uses the full text of the medical notes and one that uses only a selected list of medical entities extracted from the text. These approaches achieve 79% and 66% precision, respectively, but on a confidence threshold of 0.6, precision increases to 85% and 75%, respectively. In addition, a method to detect warning symptoms is implemented to render the classification task transparent from a medical perspective. The method is based on the learning of attention scores and a method of automatic validation using the same data.