 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness to Pruning Predicts Generalization in Deep Neural Networks
Paper and Code
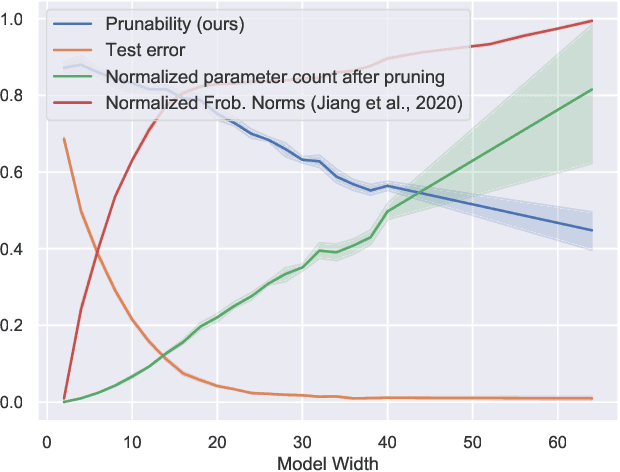
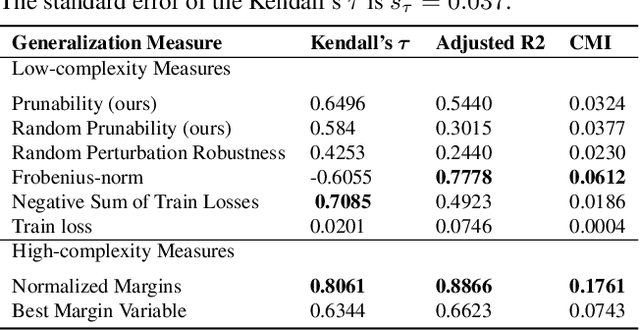
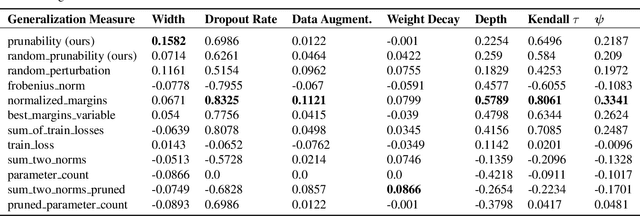
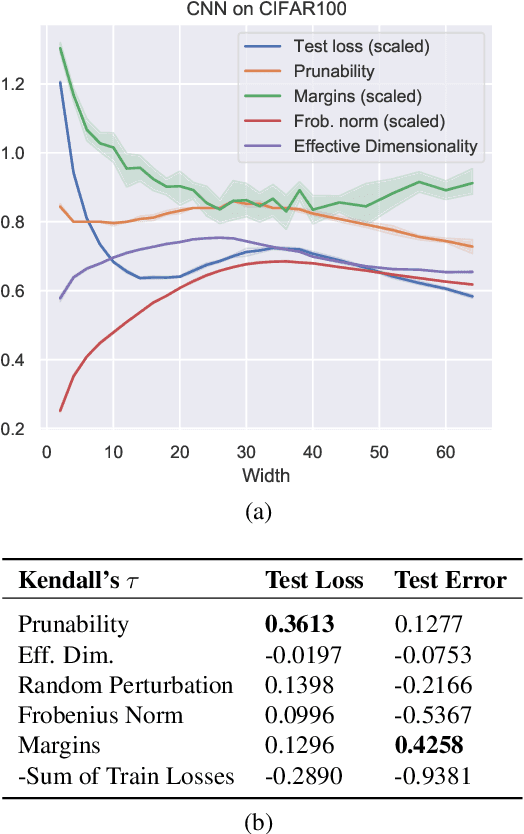
Existing generalization measures that aim to capture a model's simplicity based on parameter counts or norms fail to explain generalization in overparameterized deep neural networks. In this paper, we introduce a new, theoretically motivated measure of a network's simplicity which we call prunability: the smallest \emph{fraction} of the network's parameters that can be kept while pruning without adversely affecting its training loss. We show that this measure is highly predictive of a model's generalization performance across a large set of convolutional networks trained on CIFAR-10, does not grow with network size unlike existing pruning-based measures, and exhibits high correlation with test set loss even in a particularly challenging double descent setting. Lastly, we show that the success of prunability cannot be explained by its relation to known complexity measures based on models' margin, flatness of minima and optimization speed, finding that our new measure is similar to -- but more predictive than -- existing flatness-based measures, and that its predictions exhibit low mutual information with those of other baselines.