 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIt's FLAN time! Summing feature-wise latent representations for interpretability
Jun 18, 2021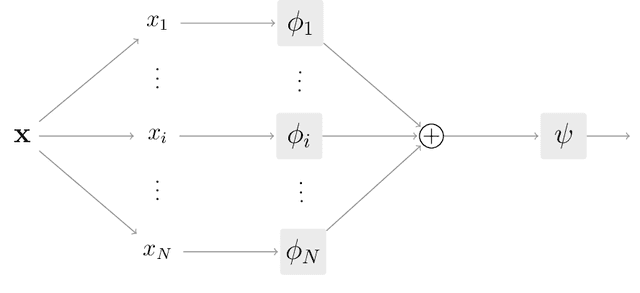
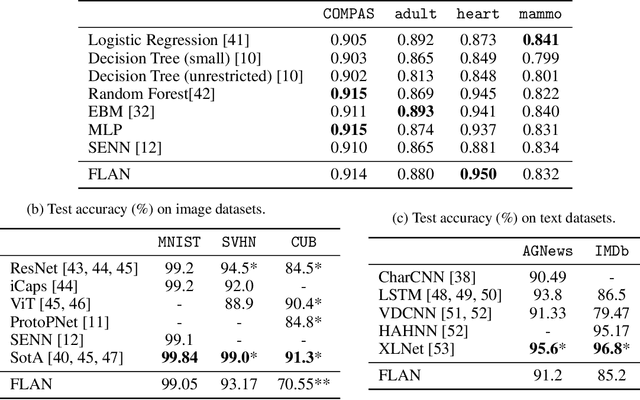
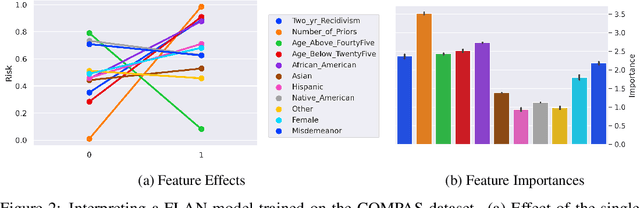
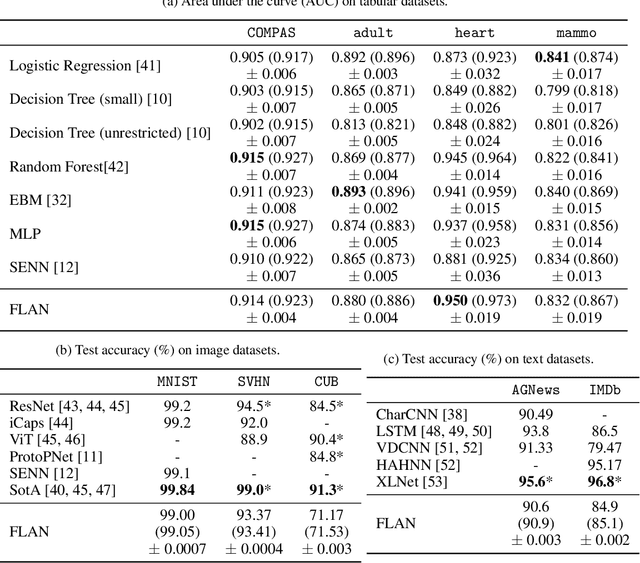
Interpretability has become a necessary feature for machine learning models deployed in critical scenarios, e.g. legal systems, healthcare. In these situations, algorithmic decisions may have (potentially negative) long-lasting effects on the end-user affected by the decision. In many cases, the representational power of deep learning models is not needed, therefore simple and interpretable models (e.g. linear models) should be preferred. However, in high-dimensional and/or complex domains (e.g. computer vision), the universal approximation capabilities of neural networks is required. Inspired by linear models and the Kolmogorov-Arnol representation theorem, we propose a novel class of structurally-constrained neural networks, which we call FLANs (Feature-wise Latent Additive Networks). Crucially, FLANs process each input feature separately, computing for each of them a representation in a common latent space. These feature-wise latent representations are then simply summed, and the aggregated representation is used for prediction. These constraints (which are at the core of the interpretability of linear models) allow an user to estimate the effect of each individual feature independently from the others, enhancing interpretability. In a set of experiments across different domains, we show how without compromising excessively the test performance, the structural constraints proposed in FLANs indeed increase the interpretability of deep learning models.
Learning Invariances for Interpretability using Supervised VAE
Jul 15, 2020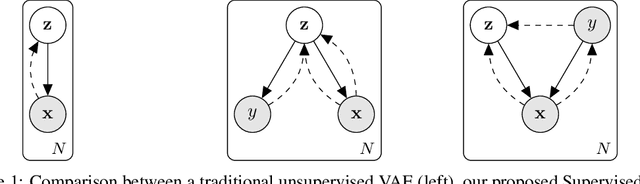

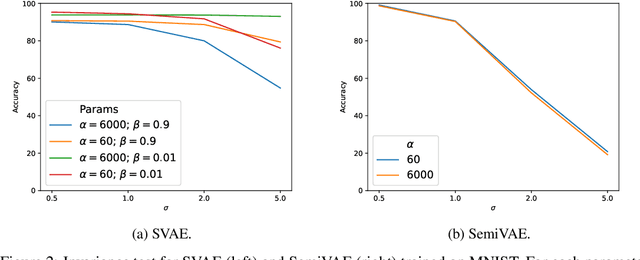

We propose to learn model invariances as a means of interpreting a model. This is motivated by a reverse engineering principle. If we understand a problem, we may introduce inductive biases in our model in the form of invariances. Conversely, when interpreting a complex supervised model, we can study its invariances to understand how that model solves a problem. To this end we propose a supervised form of variational auto-encoders (VAEs). Crucially, only a subset of the dimensions in the latent space contributes to the supervised task, allowing the remaining dimensions to act as nuisance parameters. By sampling solely the nuisance dimensions, we are able to generate samples that have undergone transformations that leave the classification unchanged, revealing the invariances of the model. Our experimental results show the capability of our proposed model both in terms of classification, and generation of invariantly transformed samples. Finally we show how combining our model with feature attribution methods it is possible to reach a more fine-grained understanding about the decision process of the model.
On quantitative aspects of model interpretability
Jul 15, 2020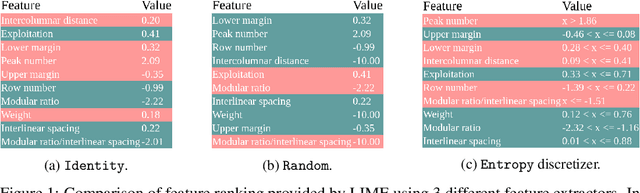
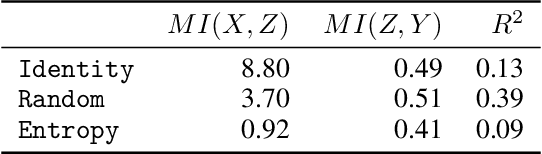

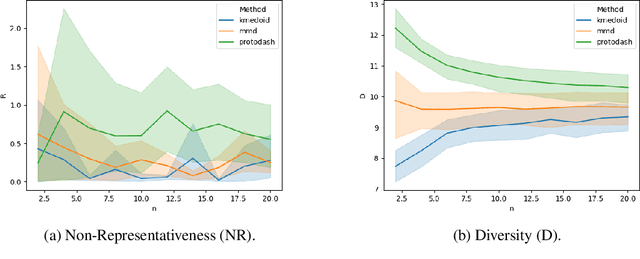
Despite the growing body of work in interpretable machine learning, it remains unclear how to evaluate different explainability methods without resorting to qualitative assessment and user-studies. While interpretability is an inherently subjective matter, previous works in cognitive science and epistemology have shown that good explanations do possess aspects that can be objectively judged apart from fidelity), such assimplicity and broadness. In this paper we propose a set of metrics to programmatically evaluate interpretability methods along these dimensions. In particular, we argue that the performance of methods along these dimensions can be orthogonally imputed to two conceptual parts, namely the feature extractor and the actual explainability method. We experimentally validate our metrics on different benchmark tasks and show how they can be used to guide a practitioner in the selection of the most appropriate method for the task at hand.
MonoNet: Towards Interpretable Models by Learning Monotonic Features
Sep 30, 2019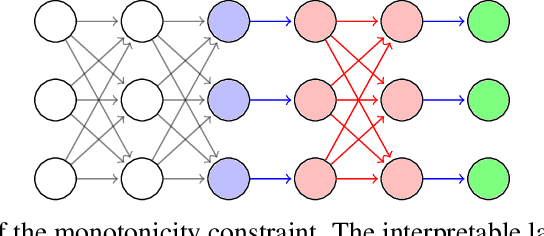



Being able to interpret, or explain, the predictions made by a machine learning model is of fundamental importance. This is especially true when there is interest in deploying data-driven models to make high-stakes decisions, e.g. in healthcare. While recent years have seen an increasing interest in interpretable machine learning research, this field is currently lacking an agreed-upon definition of interpretability, and some researchers have called for a more active conversation towards a rigorous approach to interpretability. Joining this conversation, we claim in this paper that the difficulty of interpreting a complex model stems from the existing interactions among features. We argue that by enforcing monotonicity between features and outputs, we are able to reason about the effect of a single feature on an output independently from other features, and consequently better understand the model. We show how to structurally introduce this constraint in deep learning models by adding new simple layers. We validate our model on benchmark datasets, and compare our results with previously proposed interpretable models.
edGNN: a Simple and Powerful GNN for Directed Labeled Graphs
Apr 18, 2019
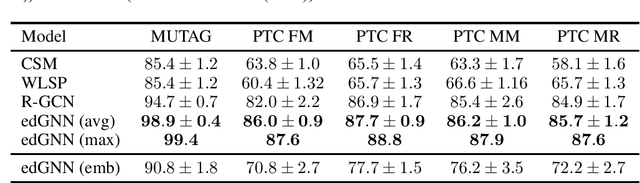

The ability of a graph neural network (GNN) to leverage both the graph topology and graph labels is fundamental to building discriminative node and graph embeddings. Building on previous work, we theoretically show that edGNN, our model for directed labeled graphs, is as powerful as the Weisfeiler--Lehman algorithm for graph isomorphism. Our experiments support our theoretical findings, confirming that graph neural networks can be used effectively for inference problems on directed graphs with both node and edge labels. Code available at https://github.com/guillaumejaume/edGNN.
Patient Risk Assessment and Warning Symptom Detection Using Deep Attention-Based Neural Networks
Sep 28, 2018
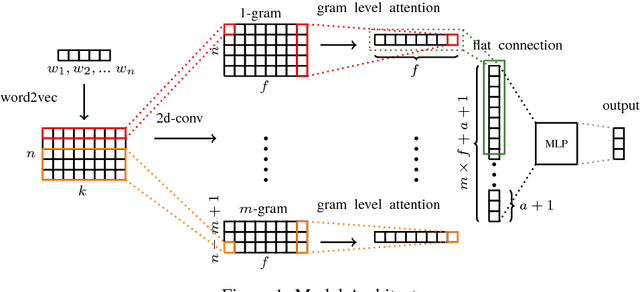


We present an operational component of a real-world patient triage system. Given a specific patient presentation, the system is able to assess the level of medical urgency and issue the most appropriate recommendation in terms of best point of care and time to treat. We use an attention-based convolutional neural network architecture trained on 600,000 doctor notes in German. We compare two approaches, one that uses the full text of the medical notes and one that uses only a selected list of medical entities extracted from the text. These approaches achieve 79% and 66% precision, respectively, but on a confidence threshold of 0.6, precision increases to 85% and 75%, respectively. In addition, a method to detect warning symptoms is implemented to render the classification task transparent from a medical perspective. The method is based on the learning of attention scores and a method of automatic validation using the same data.