 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised haze removal from underwater images
Jun 05, 2023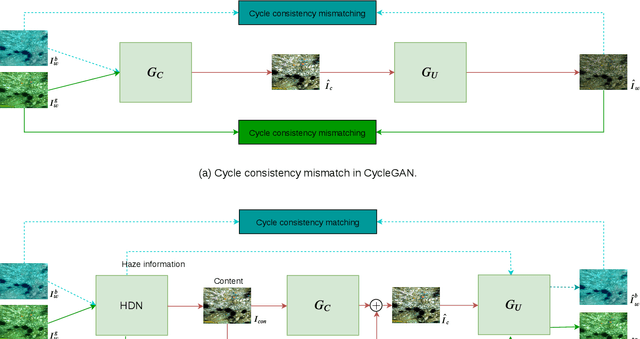

Several supervised networks exist that remove haze information from underwater images using paired datasets and pixel-wise loss functions. However, training these networks requires large amounts of paired data which is cumbersome, complex and time-consuming. Also, directly using adversarial and cycle consistency loss functions for unsupervised learning is inaccurate as the underlying mapping from clean to underwater images is one-to-many, resulting in an inaccurate constraint on the cycle consistency loss. To address these issues, we propose a new method to remove haze from underwater images using unpaired data. Our model disentangles haze and content information from underwater images using a Haze Disentanglement Network (HDN). The disentangled content is used by a restoration network to generate a clean image using adversarial losses. The disentangled haze is then used as a guide for underwater image regeneration resulting in a strong constraint on cycle consistency loss and improved performance gains. Different ablation studies show that the haze and content from underwater images are effectively separated. Exhaustive experiments reveal that accurate cycle consistency constraint and the proposed network architecture play an important role in yielding enhanced results. Experiments on UFO-120, UWNet, UWScenes, and UIEB underwater datasets indicate that the results of our method outperform prior art both visually and quantitatively.
Unsupervised network for low-light enhancement
Jun 05, 2023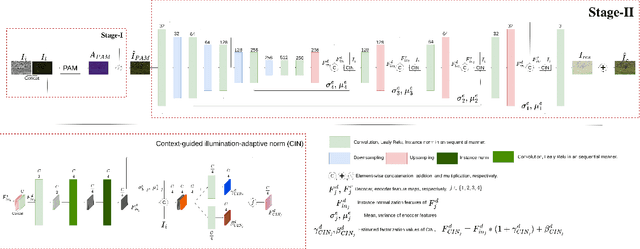
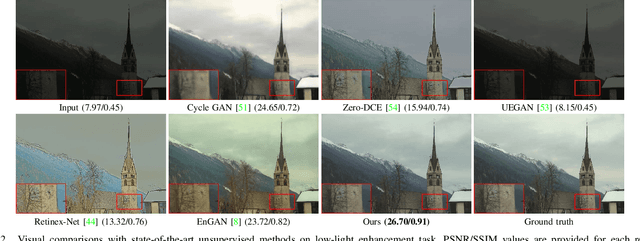
Supervised networks address the task of low-light enhancement using paired images. However, collecting a wide variety of low-light/clean paired images is tedious as the scene needs to remain static during imaging. In this paper, we propose an unsupervised low-light enhancement network using contextguided illumination-adaptive norm (CIN). Inspired by coarse to fine methods, we propose to address this task in two stages. In stage-I, a pixel amplifier module (PAM) is used to generate a coarse estimate with an overall improvement in visibility and aesthetic quality. Stage-II further enhances the saturated dark pixels and scene properties of the image using CIN. Different ablation studies show the importance of PAM and CIN in improving the visible quality of the image. Next, we propose a region-adaptive single input multiple output (SIMO) model that can generate multiple enhanced images from a single lowlight image. The objective of SIMO is to let users choose the image of their liking from a pool of enhanced images. Human subjective analysis of SIMO results shows that the distribution of preferred images varies, endorsing the importance of SIMO-type models. Lastly, we propose a low-light road scene (LLRS) dataset having an unpaired collection of low-light and clean scenes. Unlike existing datasets, the clean and low-light scenes in LLRS are real and captured using fixed camera settings. Exhaustive comparisons on publicly available datasets, and the proposed dataset reveal that the results of our model outperform prior art quantitatively and qualitatively.
Zero shot framework for satellite image restoration
Jun 05, 2023


Satellite images are typically subject to multiple distortions. Different factors affect the quality of satellite images, including changes in atmosphere, surface reflectance, sun illumination, viewing geometries etc., limiting its application to downstream tasks. In supervised networks, the availability of paired datasets is a strong assumption. Consequently, many unsupervised algorithms have been proposed to address this problem. These methods synthetically generate a large dataset of degraded images using image formation models. A neural network is then trained with an adversarial loss to discriminate between images from distorted and clean domains. However, these methods yield suboptimal performance when tested on real images that do not necessarily conform to the generation mechanism. Also, they require a large amount of training data and are rendered unsuitable when only a few images are available. We propose a distortion disentanglement and knowledge distillation framework for satellite image restoration to address these important issues. Our algorithm requires only two images: the distorted satellite image to be restored and a reference image with similar semantics. Specifically, we first propose a mechanism to disentangle distortion. This enables us to generate images with varying degrees of distortion using the disentangled distortion and the reference image. We then propose the use of knowledge distillation to train a restoration network using the generated image pairs. As a final step, the distorted image is passed through the restoration network to get the final output. Ablation studies show that our proposed mechanism successfully disentangles distortion.
Unsupervised Domain-Specific Deblurring using Scale-Specific Attention
Dec 12, 2021
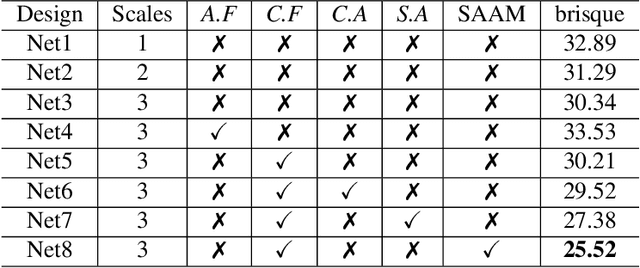
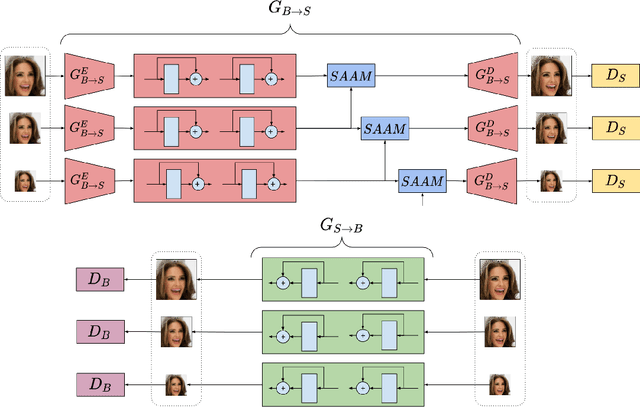
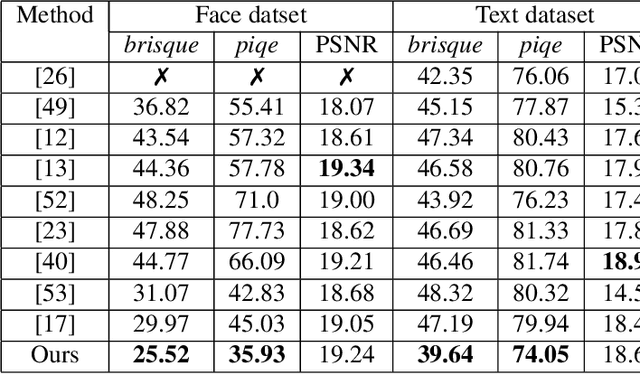
In the literature, coarse-to-fine or scale-recurrent approach i.e. progressively restoring a clean image from its low-resolution versions has been successfully employed for single image deblurring. However, a major disadvantage of existing methods is the need for paired data; i.e. sharpblur image pairs of the same scene, which is a complicated and cumbersome acquisition procedure. Additionally, due to strong supervision on loss functions, pre-trained models of such networks are strongly biased towards the blur experienced during training and tend to give sub-optimal performance when confronted by new blur kernels during inference time. To address the above issues, we propose unsupervised domain-specific deblurring using a scale-adaptive attention module (SAAM). Our network does not require supervised pairs for training, and the deblurring mechanism is primarily guided by adversarial loss, thus making our network suitable for a distribution of blur functions. Given a blurred input image, different resolutions of the same image are used in our model during training and SAAM allows for effective flow of information across the resolutions. For network training at a specific scale, SAAM attends to lower scale features as a function of the current scale. Different ablation studies show that our coarse-to-fine mechanism outperforms end-to-end unsupervised models and SAAM is able to attend better compared to attention models used in literature. Qualitative and quantitative comparisons (on no-reference metrics) show that our method outperforms prior unsupervised methods.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020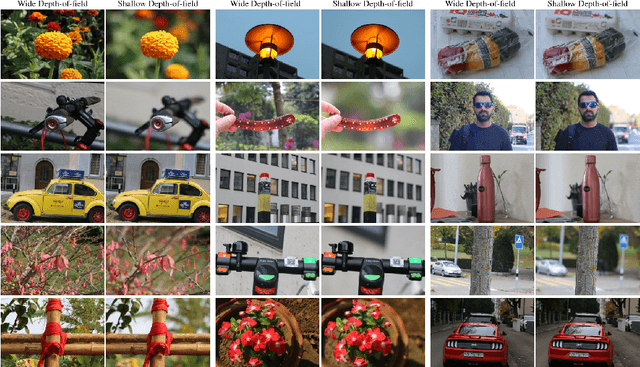


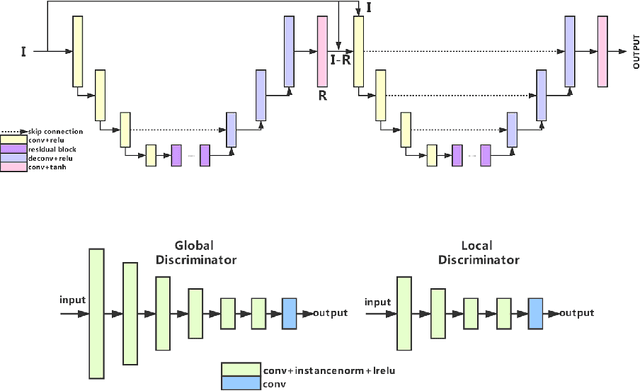
This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
AIM 2019 Challenge on Real-World Image Super-Resolution: Methods and Results
Nov 19, 2019
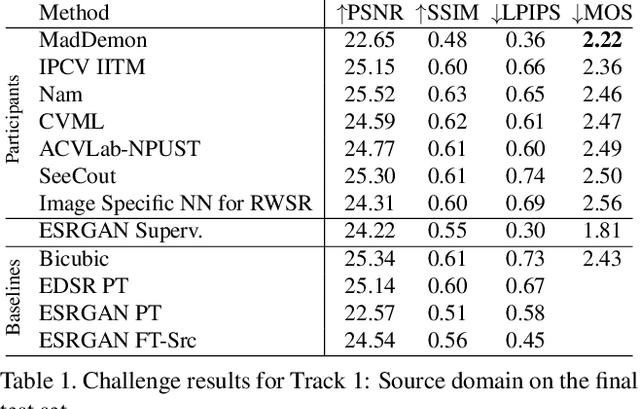
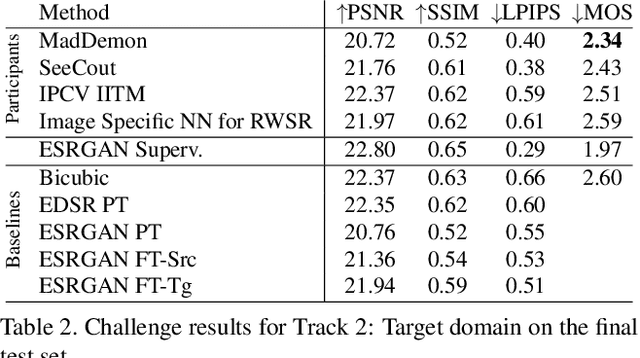

This paper reviews the AIM 2019 challenge on real world super-resolution. It focuses on the participating methods and final results. The challenge addresses the real world setting, where paired true high and low-resolution images are unavailable. For training, only one set of source input images is therefore provided in the challenge. In Track 1: Source Domain the aim is to super-resolve such images while preserving the low level image characteristics of the source input domain. In Track 2: Target Domain a set of high-quality images is also provided for training, that defines the output domain and desired quality of the super-resolved images. To allow for quantitative evaluation, the source input images in both tracks are constructed using artificial, but realistic, image degradations. The challenge is the first of its kind, aiming to advance the state-of-the-art and provide a standard benchmark for this newly emerging task. In total 7 teams competed in the final testing phase, demonstrating new and innovative solutions to the problem.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019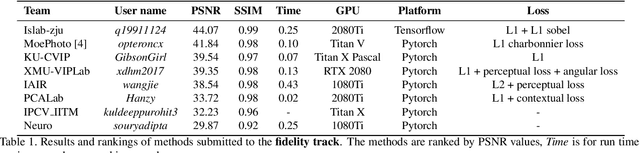
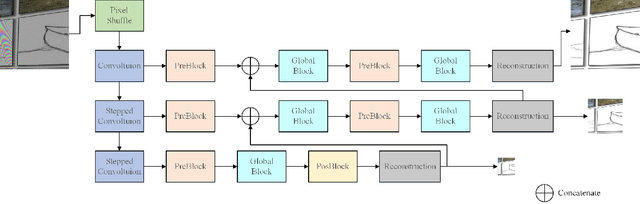
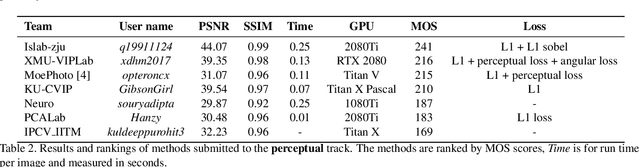
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.
PIRM Challenge on Perceptual Image Enhancement on Smartphones: Report
Oct 03, 2018
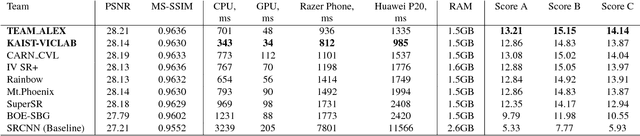

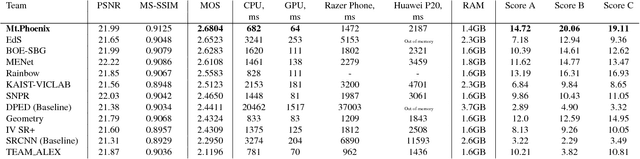
This paper reviews the first challenge on efficient perceptual image enhancement with the focus on deploying deep learning models on smartphones. The challenge consisted of two tracks. In the first one, participants were solving the classical image super-resolution problem with a bicubic downscaling factor of 4. The second track was aimed at real-world photo enhancement, and the goal was to map low-quality photos from the iPhone 3GS device to the same photos captured with a DSLR camera. The target metric used in this challenge combined the runtime, PSNR scores and solutions' perceptual results measured in the user study. To ensure the efficiency of the submitted models, we additionally measured their runtime and memory requirements on Android smartphones. The proposed solutions significantly improved baseline results defining the state-of-the-art for image enhancement on smartphones.