 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReversed Image Signal Processing and RAW Reconstruction. AIM 2022 Challenge Report
Oct 20, 2022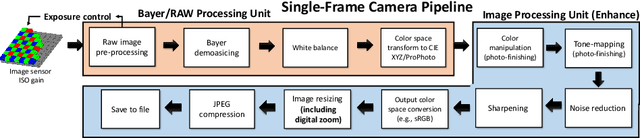
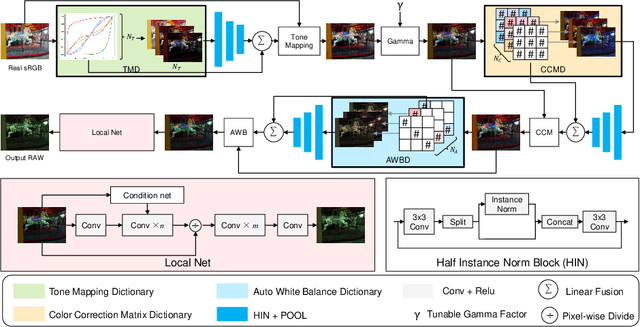
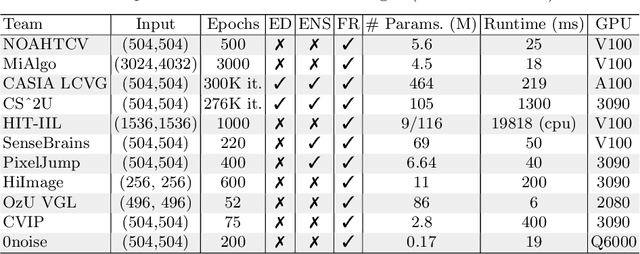
Cameras capture sensor RAW images and transform them into pleasant RGB images, suitable for the human eyes, using their integrated Image Signal Processor (ISP). Numerous low-level vision tasks operate in the RAW domain (e.g. image denoising, white balance) due to its linear relationship with the scene irradiance, wide-range of information at 12bits, and sensor designs. Despite this, RAW image datasets are scarce and more expensive to collect than the already large and public RGB datasets. This paper introduces the AIM 2022 Challenge on Reversed Image Signal Processing and RAW Reconstruction. We aim to recover raw sensor images from the corresponding RGBs without metadata and, by doing this, "reverse" the ISP transformation. The proposed methods and benchmark establish the state-of-the-art for this low-level vision inverse problem, and generating realistic raw sensor readings can potentially benefit other tasks such as denoising and super-resolution.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022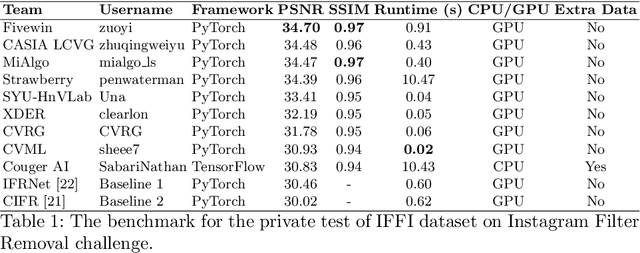

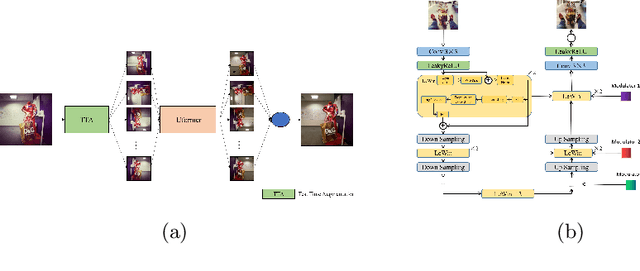
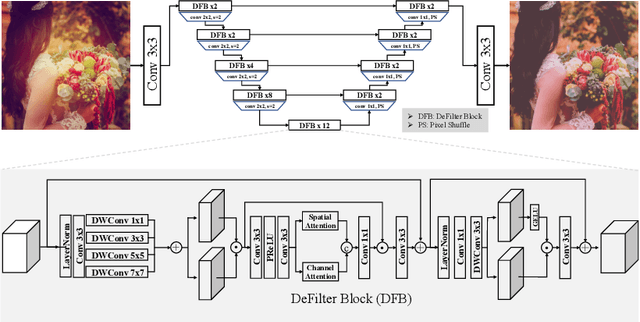
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022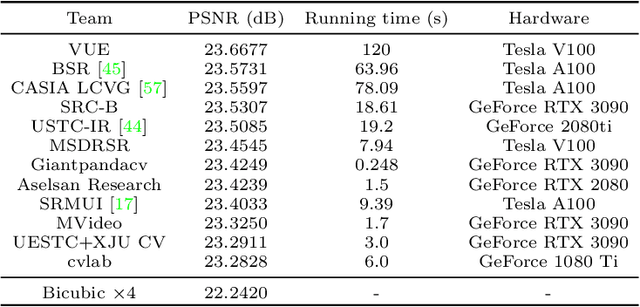
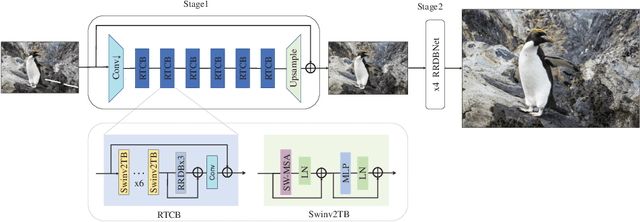

This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Architecture Aware Latency Constrained Sparse Neural Networks
Sep 01, 2021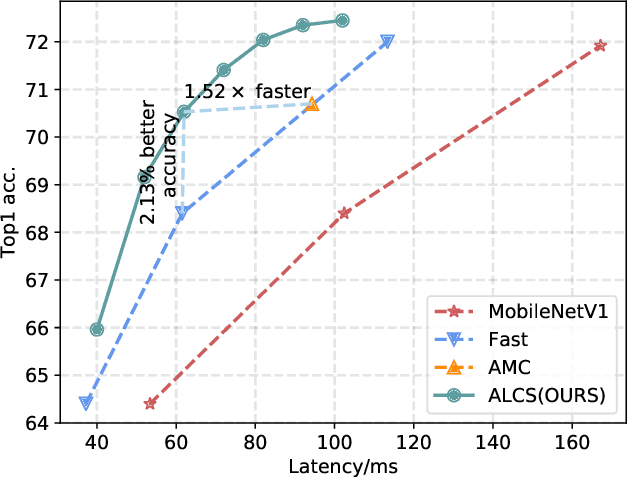
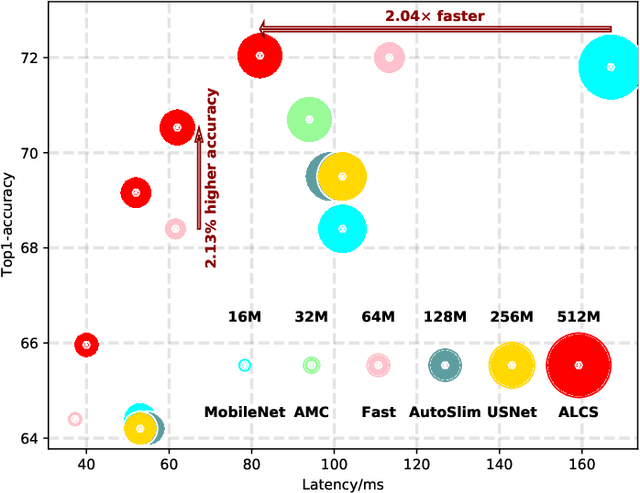
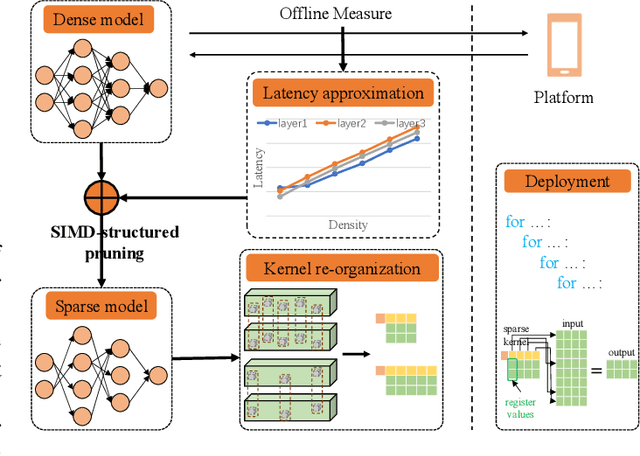
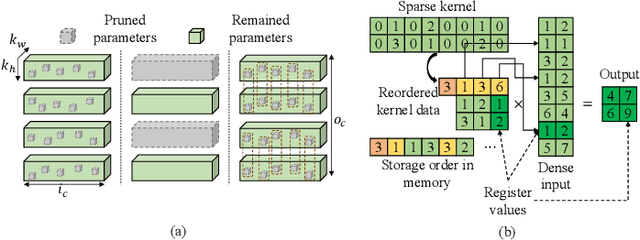
Acceleration of deep neural networks to meet a specific latency constraint is essential for their deployment on mobile devices. In this paper, we design an architecture aware latency constrained sparse (ALCS) framework to prune and accelerate CNN models. Taking modern mobile computation architectures into consideration, we propose Single Instruction Multiple Data (SIMD)-structured pruning, along with a novel sparse convolution algorithm for efficient computation. Besides, we propose to estimate the run time of sparse models with piece-wise linear interpolation. The whole latency constrained pruning task is formulated as a constrained optimization problem that can be efficiently solved with Alternating Direction Method of Multipliers (ADMM). Extensive experiments show that our system-algorithm co-design framework can achieve much better Pareto frontier among network accuracy and latency on resource-constrained mobile devices.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
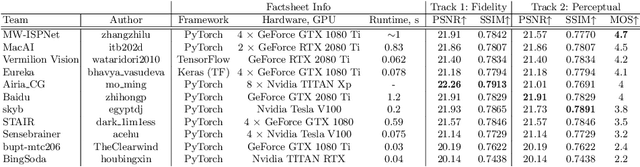
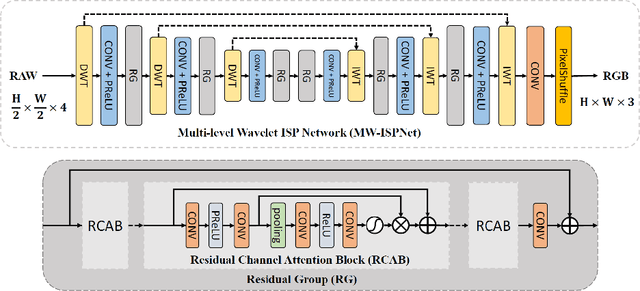
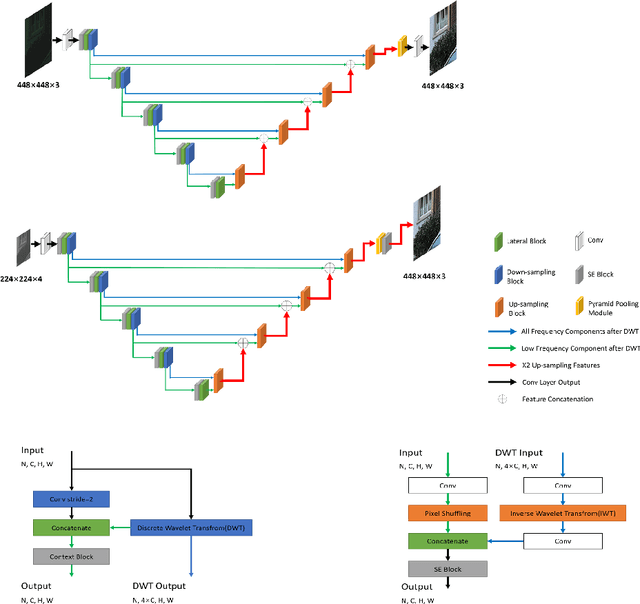
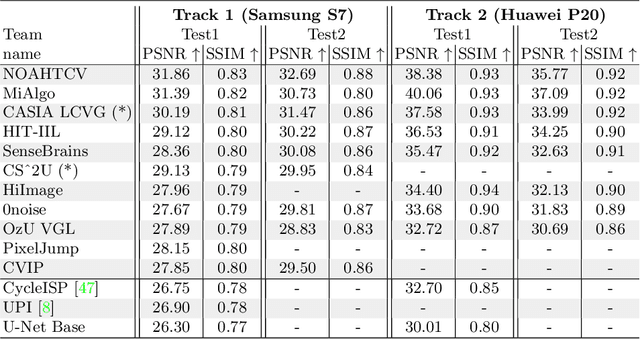
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020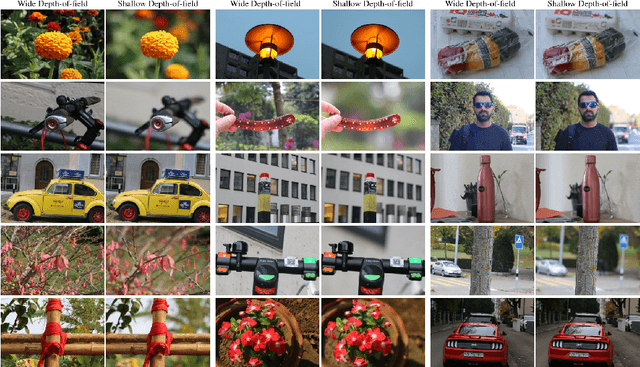


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.
BGGAN: Bokeh-Glass Generative Adversarial Network for Rendering Realistic Bokeh
Nov 04, 2020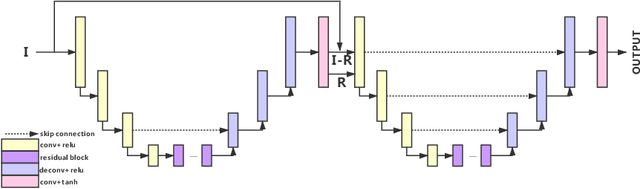
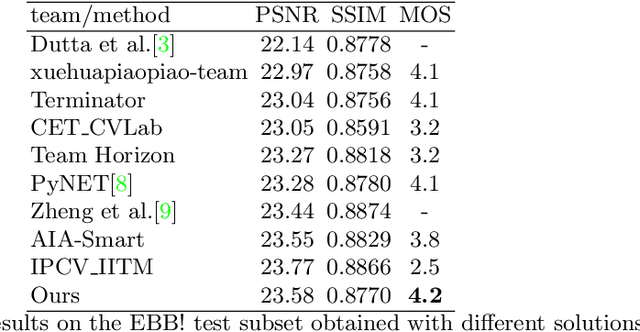
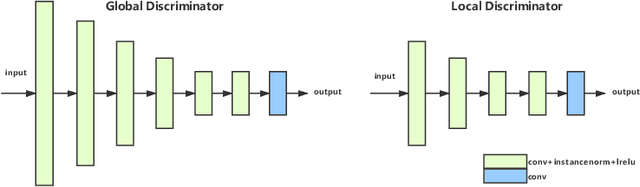
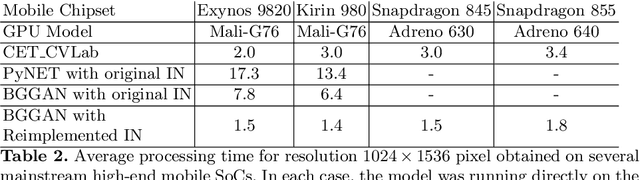
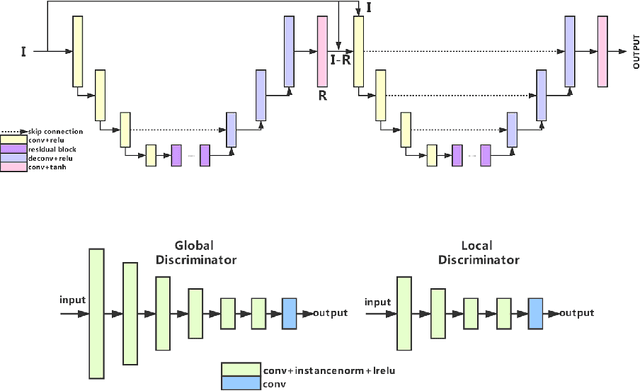
A photo captured with bokeh effect often means objects in focus are sharp while the out-of-focus areas are all blurred. DSLR can easily render this kind of effect naturally. However, due to the limitation of sensors, smartphones cannot capture images with depth-of-field effects directly. In this paper, we propose a novel generator called Glass-Net, which generates bokeh images not relying on complex hardware. Meanwhile, the GAN-based method and perceptual loss are combined for rendering a realistic bokeh effect in the stage of finetuning the model. Moreover, Instance Normalization(IN) is reimplemented in our network, which ensures our tflite model with IN can be accelerated on smartphone GPU. Experiments show that our method is able to render a high-quality bokeh effect and process one $1024 \times 1536$ pixel image in 1.9 seconds on all smartphone chipsets. This approach ranked First in AIM 2020 Rendering Realistic Bokeh Challenge Track 1 \& Track 2.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020

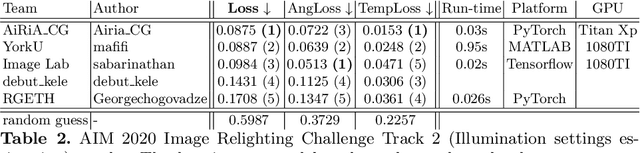

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
AIM 2020 Challenge on Efficient Super-Resolution: Methods and Results
Sep 15, 2020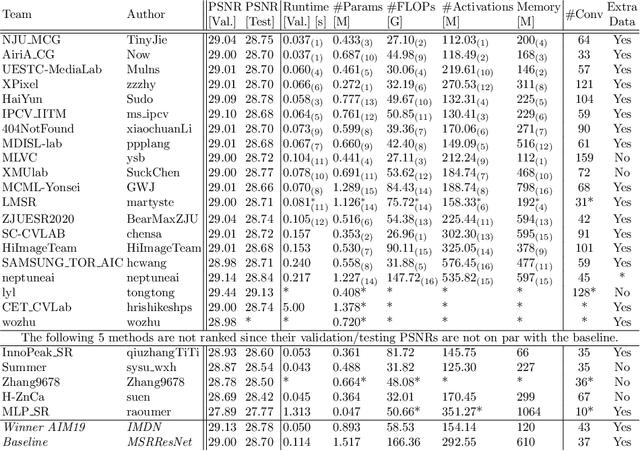
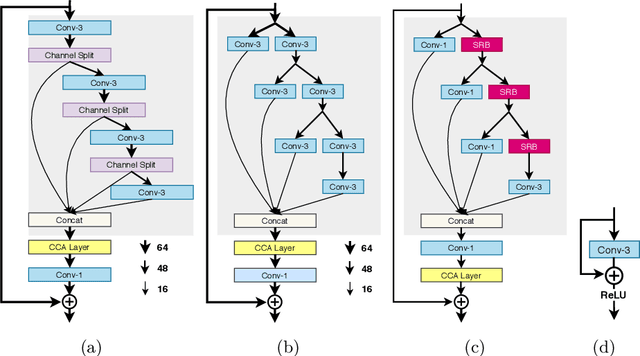
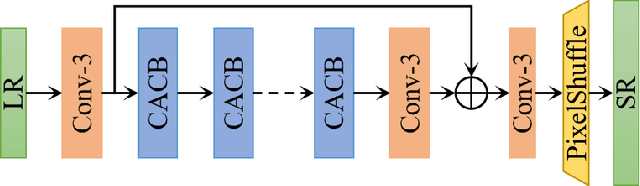
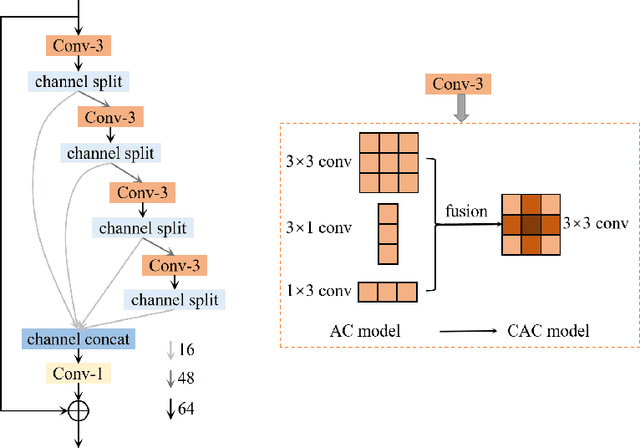
This paper reviews the AIM 2020 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The challenge task was to super-resolve an input image with a magnification factor x4 based on a set of prior examples of low and corresponding high resolution images. The goal is to devise a network that reduces one or several aspects such as runtime, parameter count, FLOPs, activations, and memory consumption while at least maintaining PSNR of MSRResNet. The track had 150 registered participants, and 25 teams submitted the final results. They gauge the state-of-the-art in efficient single image super-resolution.
A System-Level Solution for Low-Power Object Detection
Oct 19, 2019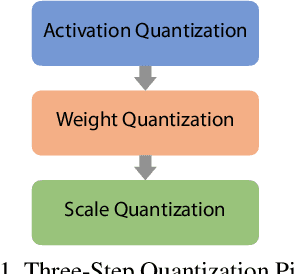
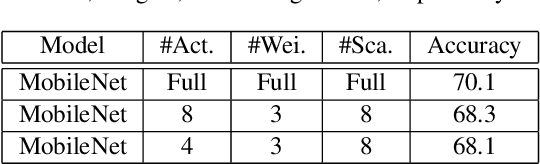
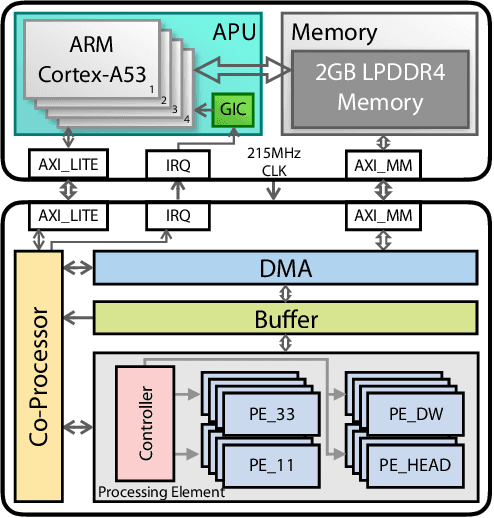

Object detection has made impressive progress in recent years with the help of deep learning. However, state-of-the-art algorithms are both computation and memory intensive. Though many lightweight networks are developed for a trade-off between accuracy and efficiency, it is still a challenge to make it practical on an embedded device. In this paper, we present a system-level solution for efficient object detection on a heterogeneous embedded device. The detection network is quantized to low bits and allows efficient implementation with shift operators. In order to make the most of the benefits of low-bit quantization, we design a dedicated accelerator with programmable logic. Inside the accelerator, a hybrid dataflow is exploited according to the heterogeneous property of different convolutional layers. We adopt a straightforward but resource-friendly column-prior tiling strategy to map the computation-intensive convolutional layers to the accelerator that can support arbitrary feature size. Other operations can be performed on the low-power CPU cores, and the entire system is executed in a pipelined manner. As a case study, we evaluate our object detection system on a real-world surveillance video with input size of 512x512, and it turns out that the system can achieve an inference speed of 18 fps at the cost of 6.9W (with display) with an mAP of 66.4 verified on the PASCAL VOC 2012 dataset.