 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedBench v4: A Robust and Scalable Benchmark for Evaluating Chinese Medical Language Models, Multimodal Models, and Intelligent Agents
Nov 19, 2025Recent advances in medical large language models (LLMs), multimodal models, and agents demand evaluation frameworks that reflect real clinical workflows and safety constraints. We present MedBench v4, a nationwide, cloud-based benchmarking infrastructure comprising over 700,000 expert-curated tasks spanning 24 primary and 91 secondary specialties, with dedicated tracks for LLMs, multimodal models, and agents. Items undergo multi-stage refinement and multi-round review by clinicians from more than 500 institutions, and open-ended responses are scored by an LLM-as-a-judge calibrated to human ratings. We evaluate 15 frontier models. Base LLMs reach a mean overall score of 54.1/100 (best: Claude Sonnet 4.5, 62.5/100), but safety and ethics remain low (18.4/100). Multimodal models perform worse overall (mean 47.5/100; best: GPT-5, 54.9/100), with solid perception yet weaker cross-modal reasoning. Agents built on the same backbones substantially improve end-to-end performance (mean 79.8/100), with Claude Sonnet 4.5-based agents achieving up to 85.3/100 overall and 88.9/100 on safety tasks. MedBench v4 thus reveals persisting gaps in multimodal reasoning and safety for base models, while showing that governance-aware agentic orchestration can markedly enhance benchmarked clinical readiness without sacrificing capability. By aligning tasks with Chinese clinical guidelines and regulatory priorities, the platform offers a practical reference for hospitals, developers, and policymakers auditing medical AI.
MedCalc-Eval and MedCalc-Env: Advancing Medical Calculation Capabilities of Large Language Models
Oct 31, 2025As large language models (LLMs) enter the medical domain, most benchmarks evaluate them on question answering or descriptive reasoning, overlooking quantitative reasoning critical to clinical decision-making. Existing datasets like MedCalc-Bench cover few calculation tasks and fail to reflect real-world computational scenarios. We introduce MedCalc-Eval, the largest benchmark for assessing LLMs' medical calculation abilities, comprising 700+ tasks across two types: equation-based (e.g., Cockcroft-Gault, BMI, BSA) and rule-based scoring systems (e.g., Apgar, Glasgow Coma Scale). These tasks span diverse specialties including internal medicine, surgery, pediatrics, and cardiology, offering a broader and more challenging evaluation setting. To improve performance, we further develop MedCalc-Env, a reinforcement learning environment built on the InternBootcamp framework, enabling multi-step clinical reasoning and planning. Fine-tuning a Qwen2.5-32B model within this environment achieves state-of-the-art results on MedCalc-Eval, with notable gains in numerical sensitivity, formula selection, and reasoning robustness. Remaining challenges include unit conversion, multi-condition logic, and contextual understanding. Code and datasets are available at https://github.com/maokangkun/MedCalc-Eval.
Disease Forecast via Progression Learning
Dec 21, 2020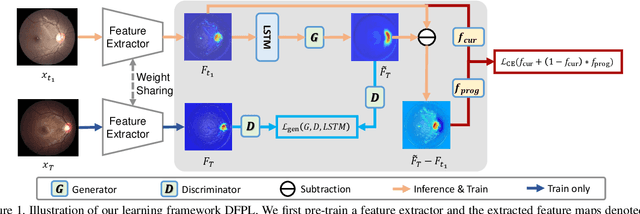
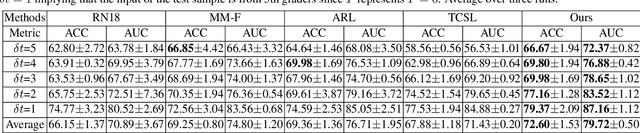

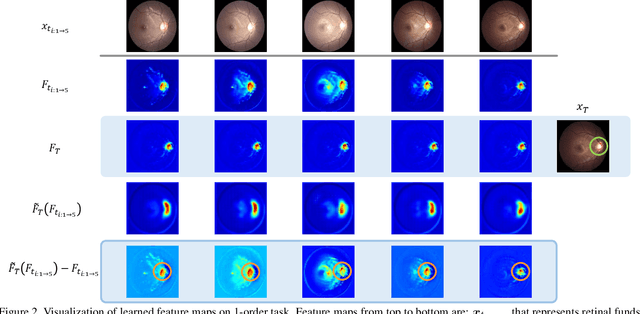
Forecasting Parapapillary atrophy (PPA), i.e., a symptom related to most irreversible eye diseases, provides an alarm for implementing an intervention to slow down the disease progression at early stage. A key question for this forecast is: how to fully utilize the historical data (e.g., retinal image) up to the current stage for future disease prediction? In this paper, we provide an answer with a novel framework, namely \textbf{D}isease \textbf{F}orecast via \textbf{P}rogression \textbf{L}earning (\textbf{DFPL}), which exploits the irreversibility prior (i.e., cannot be reversed once diagnosed). Specifically, based on this prior, we decompose two factors that contribute to the prediction of the future disease: i) the current disease label given the data (retinal image, clinical attributes) at present and ii) the future disease label given the progression of the retinal images that from the current to the future. To model these two factors, we introduce the current and progression predictors in DFPL, respectively. In order to account for the degree of progression of the disease, we propose a temporal generative model to accurately generate the future image and compare it with the current one to get a residual image. The generative model is implemented by a recurrent neural network, in order to exploit the dependency of the historical data. To verify our approach, we apply it to a PPA in-house dataset and it yields a significant improvement (\textit{e.g.}, \textbf{4.48\%} of accuracy; \textbf{3.45\%} of AUC) over others. Besides, our generative model can accurately localize the disease-related regions.
A Holistically-Guided Decoder for Deep Representation Learning with Applications to Semantic Segmentation and Object Detection
Dec 18, 2020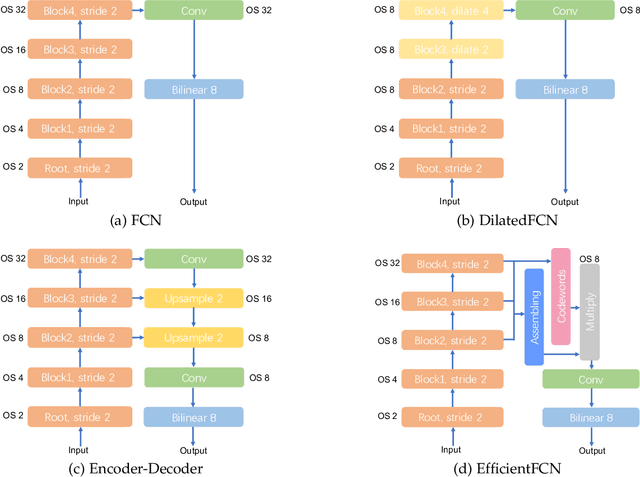
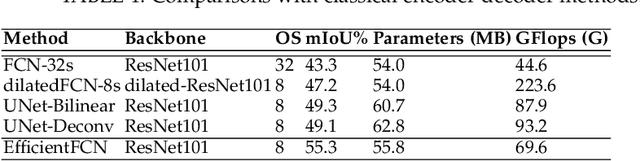
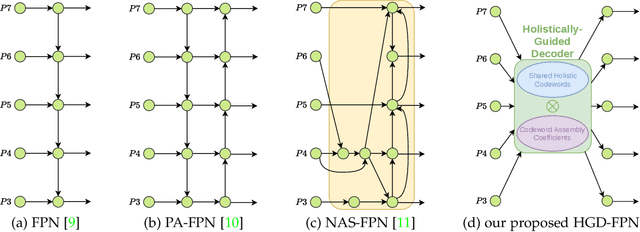
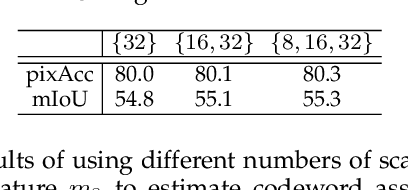
Both high-level and high-resolution feature representations are of great importance in various visual understanding tasks. To acquire high-resolution feature maps with high-level semantic information, one common strategy is to adopt dilated convolutions in the backbone networks to extract high-resolution feature maps, such as the dilatedFCN-based methods for semantic segmentation. However, due to many convolution operations are conducted on the high-resolution feature maps, such methods have large computational complexity and memory consumption. In this paper, we propose one novel holistically-guided decoder which is introduced to obtain the high-resolution semantic-rich feature maps via the multi-scale features from the encoder. The decoding is achieved via novel holistic codeword generation and codeword assembly operations, which take advantages of both the high-level and low-level features from the encoder features. With the proposed holistically-guided decoder, we implement the EfficientFCN architecture for semantic segmentation and HGD-FPN for object detection and instance segmentation. The EfficientFCN achieves comparable or even better performance than state-of-the-art methods with only 1/3 of their computational costs for semantic segmentation on PASCAL Context, PASCAL VOC, ADE20K datasets. Meanwhile, the proposed HGD-FPN achieves $>2\%$ higher mean Average Precision (mAP) when integrated into several object detection frameworks with ResNet-50 encoding backbones.
AIM 2020 Challenge on Learned Image Signal Processing Pipeline
Nov 10, 2020
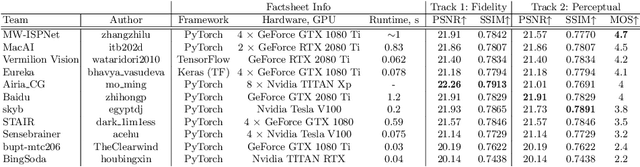
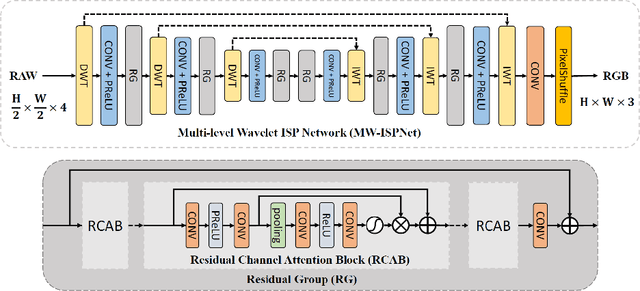
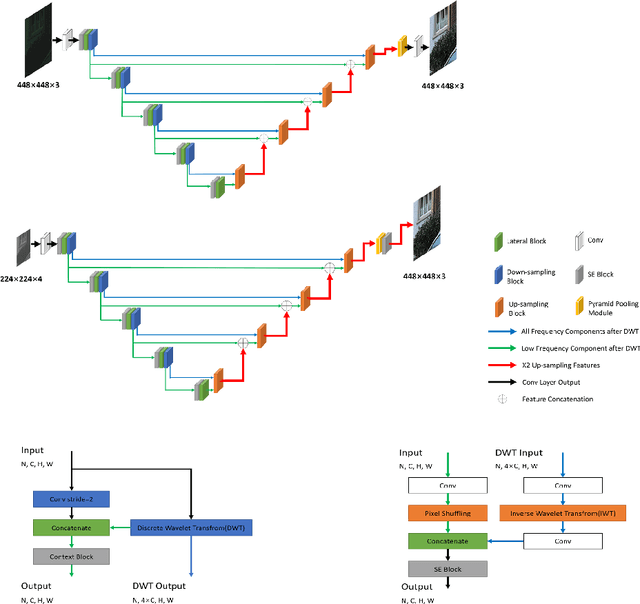
This paper reviews the second AIM learned ISP challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world RAW-to-RGB mapping problem, where to goal was to map the original low-quality RAW images captured by the Huawei P20 device to the same photos obtained with the Canon 5D DSLR camera. The considered task embraced a number of complex computer vision subtasks, such as image demosaicing, denoising, white balancing, color and contrast correction, demoireing, etc. The target metric used in this challenge combined fidelity scores (PSNR and SSIM) with solutions' perceptual results measured in a user study. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical image signal processing pipeline modeling.