 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Holistically-Guided Decoder for Deep Representation Learning with Applications to Semantic Segmentation and Object Detection
Paper and Code
Dec 18, 2020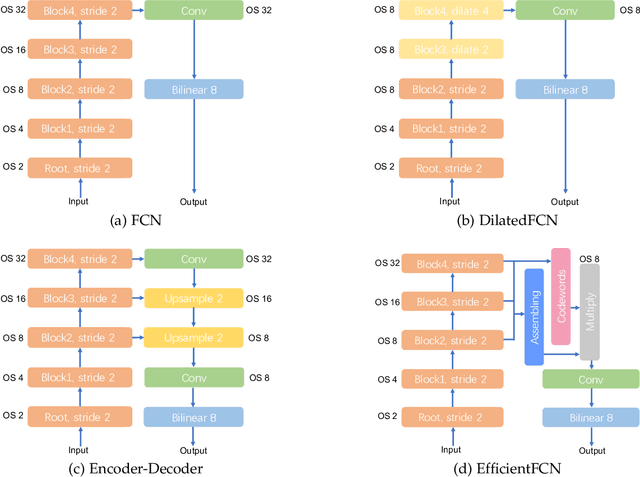
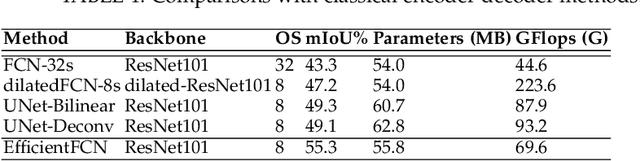
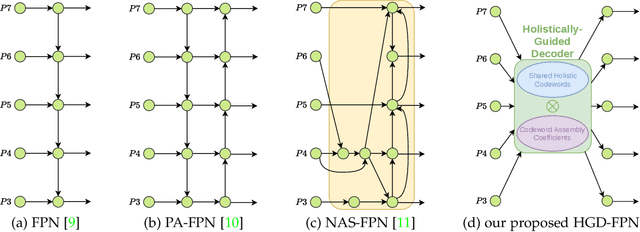
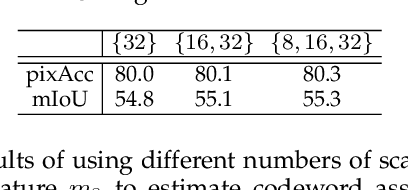
Both high-level and high-resolution feature representations are of great importance in various visual understanding tasks. To acquire high-resolution feature maps with high-level semantic information, one common strategy is to adopt dilated convolutions in the backbone networks to extract high-resolution feature maps, such as the dilatedFCN-based methods for semantic segmentation. However, due to many convolution operations are conducted on the high-resolution feature maps, such methods have large computational complexity and memory consumption. In this paper, we propose one novel holistically-guided decoder which is introduced to obtain the high-resolution semantic-rich feature maps via the multi-scale features from the encoder. The decoding is achieved via novel holistic codeword generation and codeword assembly operations, which take advantages of both the high-level and low-level features from the encoder features. With the proposed holistically-guided decoder, we implement the EfficientFCN architecture for semantic segmentation and HGD-FPN for object detection and instance segmentation. The EfficientFCN achieves comparable or even better performance than state-of-the-art methods with only 1/3 of their computational costs for semantic segmentation on PASCAL Context, PASCAL VOC, ADE20K datasets. Meanwhile, the proposed HGD-FPN achieves $>2\%$ higher mean Average Precision (mAP) when integrated into several object detection frameworks with ResNet-50 encoding backbones.