 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-Based Longitudinal Prediction of Childhood Myopia Progression Using Fundus Image Sequences and Baseline Refraction Data
Jul 31, 2024

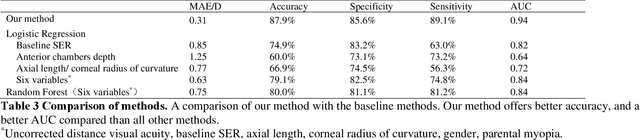
Childhood myopia constitutes a significant global health concern. It exhibits an escalating prevalence and has the potential to evolve into severe, irreversible conditions that detrimentally impact familial well-being and create substantial economic costs. Contemporary research underscores the importance of precisely predicting myopia progression to enable timely and effective interventions, thereby averting severe visual impairment in children. Such predictions predominantly rely on subjective clinical assessments, which are inherently biased and resource-intensive, thus hindering their widespread application. In this study, we introduce a novel, high-accuracy method for quantitatively predicting the myopic trajectory and myopia risk in children using only fundus images and baseline refraction data. This approach was validated through a six-year longitudinal study of 3,408 children in Henan, utilizing 16,211 fundus images and corresponding refractive data. Our method based on deep learning demonstrated predictive accuracy with an error margin of 0.311D per year and AUC scores of 0.944 and 0.995 for forecasting the risks of developing myopia and high myopia, respectively. These findings confirm the utility of our model in supporting early intervention strategies and in significantly reducing healthcare costs, particularly by obviating the need for additional metadata and repeated consultations. Furthermore, our method was designed to rely only on fundus images and refractive error data, without the need for meta data or multiple inquiries from doctors, strongly reducing the associated medical costs and facilitating large-scale screening. Our model can even provide good predictions based on only a single time measurement. Consequently, the proposed method is an important means to reduce medical inequities caused by economic disparities.
Diagnosis of Multiple Fundus Disorders Amidst a Scarcity of Medical Experts Via Self-supervised Machine Learning
Apr 23, 2024



Fundus diseases are major causes of visual impairment and blindness worldwide, especially in underdeveloped regions, where the shortage of ophthalmologists hinders timely diagnosis. AI-assisted fundus image analysis has several advantages, such as high accuracy, reduced workload, and improved accessibility, but it requires a large amount of expert-annotated data to build reliable models. To address this dilemma, we propose a general self-supervised machine learning framework that can handle diverse fundus diseases from unlabeled fundus images. Our method's AUC surpasses existing supervised approaches by 15.7%, and even exceeds performance of a single human expert. Furthermore, our model adapts well to various datasets from different regions, races, and heterogeneous image sources or qualities from multiple cameras or devices. Our method offers a label-free general framework to diagnose fundus diseases, which could potentially benefit telehealth programs for early screening of people at risk of vision loss.
SSVT: Self-Supervised Vision Transformer For Eye Disease Diagnosis Based On Fundus Images
Apr 20, 2024

Machine learning-based fundus image diagnosis technologies trigger worldwide interest owing to their benefits such as reducing medical resource power and providing objective evaluation results. However, current methods are commonly based on supervised methods, bringing in a heavy workload to biomedical staff and hence suffering in expanding effective databases. To address this issue, in this article, we established a label-free method, name 'SSVT',which can automatically analyze un-labeled fundus images and generate high evaluation accuracy of 97.0% of four main eye diseases based on six public datasets and two datasets collected by Beijing Tongren Hospital. The promising results showcased the effectiveness of the proposed unsupervised learning method, and the strong application potential in biomedical resource shortage regions to improve global eye health.
Disease Forecast via Progression Learning
Dec 21, 2020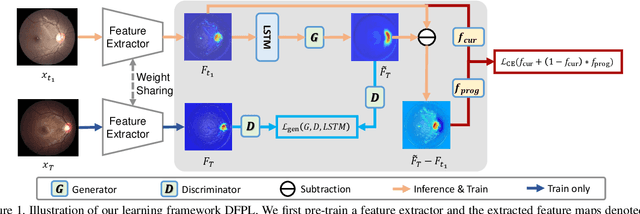
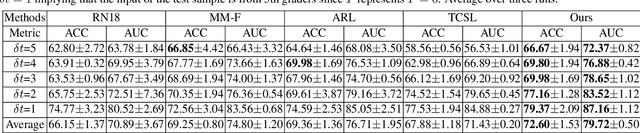

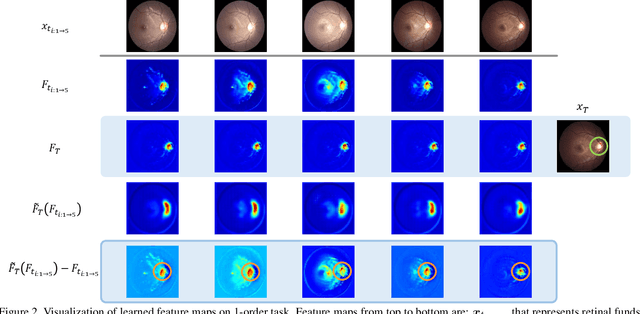
Forecasting Parapapillary atrophy (PPA), i.e., a symptom related to most irreversible eye diseases, provides an alarm for implementing an intervention to slow down the disease progression at early stage. A key question for this forecast is: how to fully utilize the historical data (e.g., retinal image) up to the current stage for future disease prediction? In this paper, we provide an answer with a novel framework, namely \textbf{D}isease \textbf{F}orecast via \textbf{P}rogression \textbf{L}earning (\textbf{DFPL}), which exploits the irreversibility prior (i.e., cannot be reversed once diagnosed). Specifically, based on this prior, we decompose two factors that contribute to the prediction of the future disease: i) the current disease label given the data (retinal image, clinical attributes) at present and ii) the future disease label given the progression of the retinal images that from the current to the future. To model these two factors, we introduce the current and progression predictors in DFPL, respectively. In order to account for the degree of progression of the disease, we propose a temporal generative model to accurately generate the future image and compare it with the current one to get a residual image. The generative model is implemented by a recurrent neural network, in order to exploit the dependency of the historical data. To verify our approach, we apply it to a PPA in-house dataset and it yields a significant improvement (\textit{e.g.}, \textbf{4.48\%} of accuracy; \textbf{3.45\%} of AUC) over others. Besides, our generative model can accurately localize the disease-related regions.
Exploration of Input Patterns for Enhancing the Performance of Liquid State Machines
Apr 06, 2020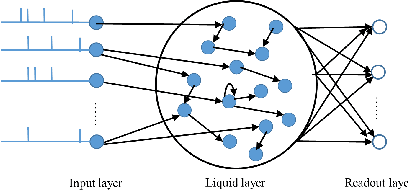
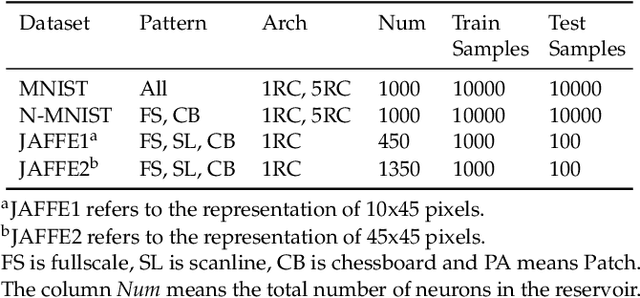


Spiking Neural Networks (SNN) have gained increasing attention for its low power consumption. But training SNN is challenging. Liquid State Machine (LSM), as a major type of Reservoir computing, has been widely recognized for its low training cost among SNNs. The exploration of LSM topology for enhancing performance often requires hyper-parameter search, which is both resource-expensive and time-consuming. We explore the influence of input scale reduction on LSM instead. There are two main reasons for studying input reduction of LSM. One is that the input dimension of large images requires efficient processing. Another one is that input exploration is generally more economic than architecture search. To mitigate the difficulty in effectively dealing with huge input spaces of LSM, and to find that whether input reduction can enhance LSM performance, we explore several input patterns, namely fullscale, scanline, chessboard, and patch. Several datasets have been used to evaluate the performance of the proposed input patterns, including two spatio image datasets and one spatio-temporal image database. The experimental results show that the reduced input under chessboard pattern improves the accuracy by up to 5%, and reduces execution time by up to 50% with up to 75\% less input storage than the fullscale input pattern for LSM.