 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Behavior Tree Planning with Commonsense Pruning and Heuristic
Jun 04, 2024



Behavior Tree (BT) planning is crucial for autonomous robot behavior control, yet its application in complex scenarios is hampered by long planning times. Pruning and heuristics are common techniques to accelerate planning, but it is difficult to design general pruning strategies and heuristic functions for BT planning problems. This paper proposes improving BT planning efficiency for everyday service robots leveraging commonsense reasoning provided by Large Language Models (LLMs), leading to model-free pre-planning action space pruning and heuristic generation. This approach takes advantage of the modularity and interpretability of BT nodes, represented by predicate logic, to enable LLMs to predict the task-relevant action predicates and objects, and even the optimal path, without an explicit action model. We propose the Heuristic Optimal Behavior Tree Expansion Algorithm (HOBTEA) with two heuristic variants and provide a formal comparison and discussion of their efficiency and optimality. We introduce a learnable and transferable commonsense library to enhance the LLM's reasoning performance without fine-tuning. The action space expansion based on the commonsense library can further increase the success rate of planning. Experiments show the theoretical bounds of commonsense pruning and heuristic, and demonstrate the actual performance of LLM learning and reasoning with the commonsense library. Results in four datasets showcase the practical effectiveness of our approach in everyday service robot applications.
Integrating Intent Understanding and Optimal Behavior Planning for Behavior Tree Generation from Human Instructions
May 13, 2024



Robots executing tasks following human instructions in domestic or industrial environments essentially require both adaptability and reliability. Behavior Tree (BT) emerges as an appropriate control architecture for these scenarios due to its modularity and reactivity. Existing BT generation methods, however, either do not involve interpreting natural language or cannot theoretically guarantee the BTs' success. This paper proposes a two-stage framework for BT generation, which first employs large language models (LLMs) to interpret goals from high-level instructions, then constructs an efficient goal-specific BT through the Optimal Behavior Tree Expansion Algorithm (OBTEA). We represent goals as well-formed formulas in first-order logic, effectively bridging intent understanding and optimal behavior planning. Experiments in the service robot validate the proficiency of LLMs in producing grammatically correct and accurately interpreted goals, demonstrate OBTEA's superiority over the baseline BT Expansion algorithm in various metrics, and finally confirm the practical deployability of our framework. The project website is https://dids-ei.github.io/Project/LLM-OBTEA/.
Molecular Property Prediction Based on Graph Structure Learning
Dec 28, 2023



Molecular property prediction (MPP) is a fundamental but challenging task in the computer-aided drug discovery process. More and more recent works employ different graph-based models for MPP, which have made considerable progress in improving prediction performance. However, current models often ignore relationships between molecules, which could be also helpful for MPP. For this sake, in this paper we propose a graph structure learning (GSL) based MPP approach, called GSL-MPP. Specifically, we first apply graph neural network (GNN) over molecular graphs to extract molecular representations. Then, with molecular fingerprints, we construct a molecular similarity graph (MSG). Following that, we conduct graph structure learning on the MSG (i.e., molecule-level graph structure learning) to get the final molecular embeddings, which are the results of fusing both GNN encoded molecular representations and the relationships among molecules, i.e., combining both intra-molecule and inter-molecule information. Finally, we use these molecular embeddings to perform MPP. Extensive experiments on seven various benchmark datasets show that our method could achieve state-of-the-art performance in most cases, especially on classification tasks. Further visualization studies also demonstrate the good molecular representations of our method.
SeqXFilter: A Memory-efficient Denoising Filter for Dynamic Vision Sensors
Jun 02, 2020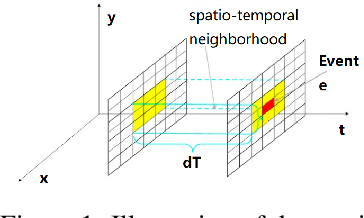
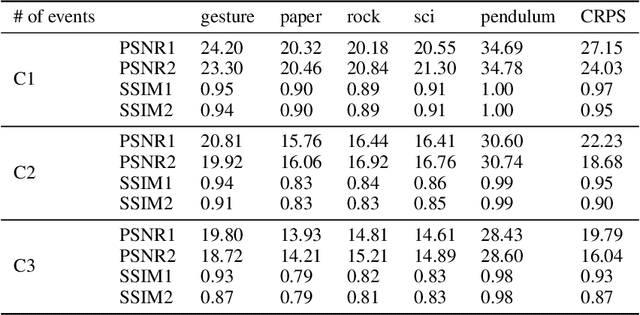

Neuromorphic event-based dynamic vision sensors (DVS) have much faster sampling rates and a higher dynamic range than frame-based imaging sensors. However, they are sensitive to background activity (BA) events that are unwanted. There are some filters for tackling this problem based on spatio-temporal correlation. However, they are either memory-intensive or computing-intensive. We propose \emph{SeqXFilter}, a spatio-temporal correlation filter with only a past event window that has an O(1) space complexity and has simple computations. We explore the spatial correlation of an event with its past few events by analyzing the distribution of the events when applying different functions on the spatial distances. We find the best function to check the spatio-temporal correlation for an event for \emph{SeqXFilter}, best separating real events and noise events. We not only give the visual denoising effect of the filter but also use two metrics for quantitatively analyzing the filter's performance. Four neuromorphic event-based datasets, recorded from four DVS with different output sizes, are used for validation of our method. The experimental results show that \emph{SeqXFilter} achieves similar performance as baseline NNb filters, but with extremely small memory cost and simple computation logic.
OD-SGD: One-step Delay Stochastic Gradient Descent for Distributed Training
May 14, 2020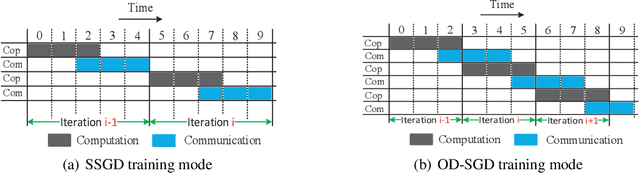

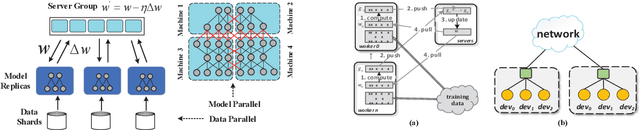

The training of modern deep learning neural network calls for large amounts of computation, which is often provided by GPUs or other specific accelerators. To scale out to achieve faster training speed, two update algorithms are mainly applied in the distributed training process, i.e. the Synchronous SGD algorithm (SSGD) and Asynchronous SGD algorithm (ASGD). SSGD obtains good convergence point while the training speed is slowed down by the synchronous barrier. ASGD has faster training speed but the convergence point is lower when compared to SSGD. To sufficiently utilize the advantages of SSGD and ASGD, we propose a novel technology named One-step Delay SGD (OD-SGD) to combine their strengths in the training process. Therefore, we can achieve similar convergence point and training speed as SSGD and ASGD separately. To the best of our knowledge, we make the first attempt to combine the features of SSGD and ASGD to improve distributed training performance. Each iteration of OD-SGD contains a global update in the parameter server node and local updates in the worker nodes, the local update is introduced to update and compensate the delayed local weights. We evaluate our proposed algorithm on MNIST, CIFAR-10 and ImageNet datasets. Experimental results show that OD-SGD can obtain similar or even slightly better accuracy than SSGD, while its training speed is much faster, which even exceeds the training speed of ASGD.
A Neural Architecture Search based Framework for Liquid State Machine Design
Apr 07, 2020
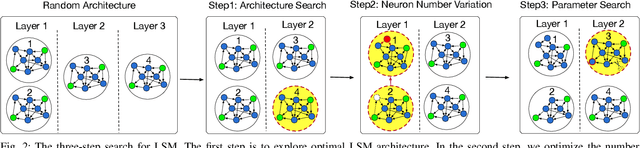
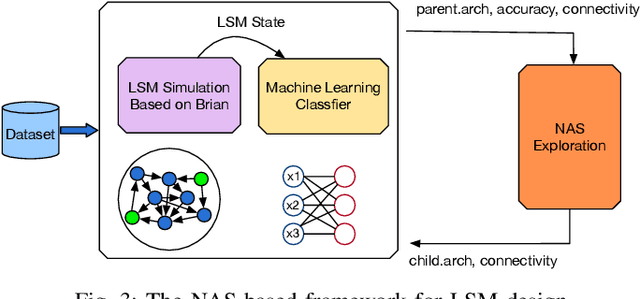

Liquid State Machine (LSM), also known as the recurrent version of Spiking Neural Networks (SNN), has attracted great research interests thanks to its high computational power, biological plausibility from the brain, simple structure and low training complexity. By exploring the design space in network architectures and parameters, recent works have demonstrated great potential for improving the accuracy of LSM model with low complexity. However, these works are based on manually-defined network architectures or predefined parameters. Considering the diversity and uniqueness of brain structure, the design of LSM model should be explored in the largest search space possible. In this paper, we propose a Neural Architecture Search (NAS) based framework to explore both architecture and parameter design space for automatic dataset-oriented LSM model. To handle the exponentially-increased design space, we adopt a three-step search for LSM, including multi-liquid architecture search, variation on the number of neurons and parameters search such as percentage connectivity and excitatory neuron ratio within each liquid. Besides, we propose to use Simulated Annealing (SA) algorithm to implement the three-step heuristic search. Three datasets, including image dataset of MNIST and NMNIST and speech dataset of FSDD, are used to test the effectiveness of our proposed framework. Simulation results show that our proposed framework can produce the dataset-oriented optimal LSM models with high accuracy and low complexity. The best classification accuracy on the three datasets is 93.2%, 92.5% and 84% respectively with only 1000 spiking neurons, and the network connections can be averagely reduced by 61.4% compared with a single LSM. Moreover, we find that the total quantity of neurons in optimal LSM models on three datasets can be further reduced by 20% with only about 0.5% accuracy loss.
Exploration of Input Patterns for Enhancing the Performance of Liquid State Machines
Apr 06, 2020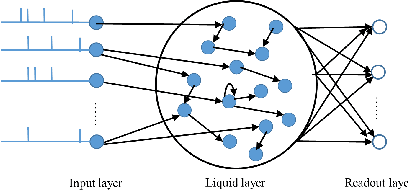
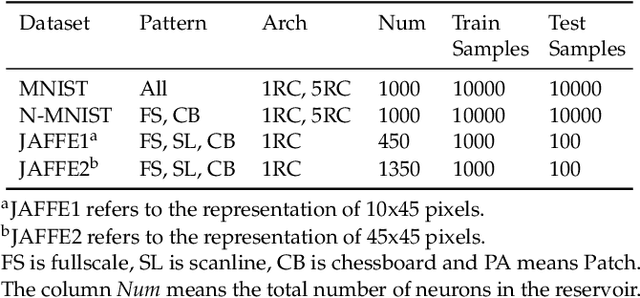


Spiking Neural Networks (SNN) have gained increasing attention for its low power consumption. But training SNN is challenging. Liquid State Machine (LSM), as a major type of Reservoir computing, has been widely recognized for its low training cost among SNNs. The exploration of LSM topology for enhancing performance often requires hyper-parameter search, which is both resource-expensive and time-consuming. We explore the influence of input scale reduction on LSM instead. There are two main reasons for studying input reduction of LSM. One is that the input dimension of large images requires efficient processing. Another one is that input exploration is generally more economic than architecture search. To mitigate the difficulty in effectively dealing with huge input spaces of LSM, and to find that whether input reduction can enhance LSM performance, we explore several input patterns, namely fullscale, scanline, chessboard, and patch. Several datasets have been used to evaluate the performance of the proposed input patterns, including two spatio image datasets and one spatio-temporal image database. The experimental results show that the reduced input under chessboard pattern improves the accuracy by up to 5%, and reduces execution time by up to 50% with up to 75\% less input storage than the fullscale input pattern for LSM.