 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShorter, but Still Trustworthy? An Empirical Study of Chain-of-Thought Compression
Apr 05, 2026Long chain-of-thought (Long-CoT) reasoning models have motivated a growing body of work on compressing reasoning traces to reduce inference cost, yet existing evaluations focus almost exclusively on task accuracy and token savings. Trustworthiness properties, whether acquired or reinforced through post-training, are encoded in the same parameter space that compression modifies. This means preserving accuracy does not, a priori, guarantee preserving trustworthiness. We conduct the first systematic empirical study of how CoT compression affects model trustworthiness, evaluating multiple models of different scales along three dimensions: safety, hallucination resistance, and multilingual robustness. Under controlled comparisons, we find that CoT compression frequently introduces trustworthiness regressions and that different methods exhibit markedly different degradation profiles across dimensions. To enable fair comparison across bases, we propose a normalized efficiency score for each dimension that reveals how naïve scalar metrics can obscure trustworthiness trade-offs. As an existence proof, we further introduce an alignment-aware DPO variant that reduces CoT length by 19.3\% on reasoning benchmarks with substantially smaller trustworthiness loss. Our findings suggest that CoT compression should be optimized not only for efficiency but also for trustworthiness, treating both as equally important design constraints.
Feature Augmentation for Self-supervised Contrastive Learning: A Closer Look
Oct 16, 2024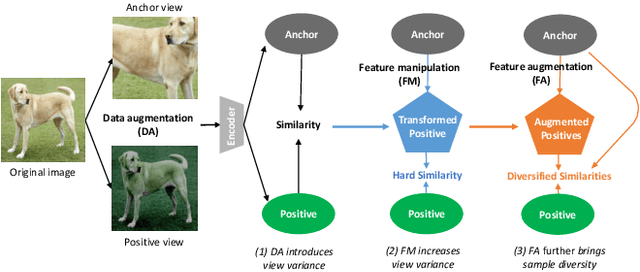

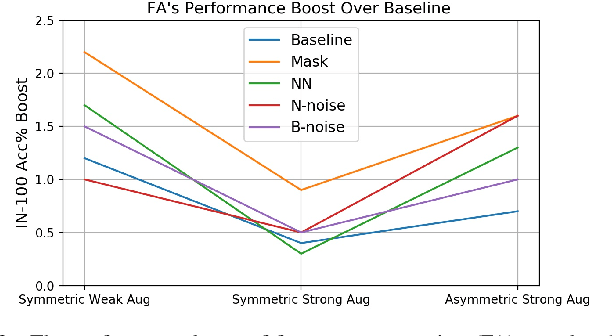

Self-supervised contrastive learning heavily relies on the view variance brought by data augmentation, so that it can learn a view-invariant pre-trained representation. Beyond increasing the view variance for contrast, this work focuses on improving the diversity of training data, to improve the generalization and robustness of the pre-trained models. To this end, we propose a unified framework to conduct data augmentation in the feature space, known as feature augmentation. This strategy is domain-agnostic, which augments similar features to the original ones and thus improves the data diversity. We perform a systematic investigation of various feature augmentation architectures, the gradient-flow skill, and the relationship between feature augmentation and traditional data augmentation. Our study reveals some practical principles for feature augmentation in self-contrastive learning. By integrating feature augmentation on the instance discrimination or the instance similarity paradigm, we consistently improve the performance of pre-trained feature learning and gain better generalization over the downstream image classification and object detection task.
SeqXFilter: A Memory-efficient Denoising Filter for Dynamic Vision Sensors
Jun 02, 2020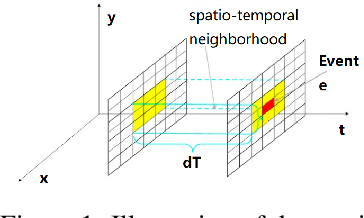
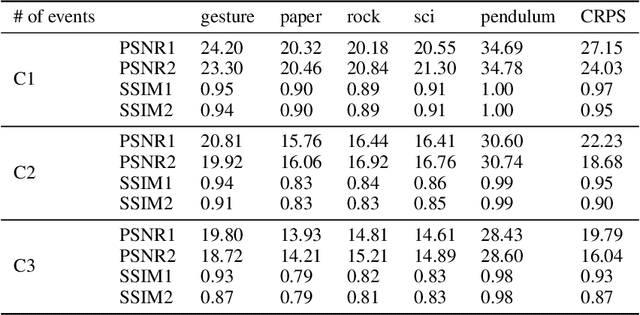
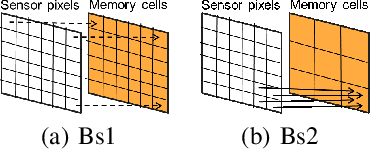

Neuromorphic event-based dynamic vision sensors (DVS) have much faster sampling rates and a higher dynamic range than frame-based imaging sensors. However, they are sensitive to background activity (BA) events that are unwanted. There are some filters for tackling this problem based on spatio-temporal correlation. However, they are either memory-intensive or computing-intensive. We propose \emph{SeqXFilter}, a spatio-temporal correlation filter with only a past event window that has an O(1) space complexity and has simple computations. We explore the spatial correlation of an event with its past few events by analyzing the distribution of the events when applying different functions on the spatial distances. We find the best function to check the spatio-temporal correlation for an event for \emph{SeqXFilter}, best separating real events and noise events. We not only give the visual denoising effect of the filter but also use two metrics for quantitatively analyzing the filter's performance. Four neuromorphic event-based datasets, recorded from four DVS with different output sizes, are used for validation of our method. The experimental results show that \emph{SeqXFilter} achieves similar performance as baseline NNb filters, but with extremely small memory cost and simple computation logic.