 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Architecture Search based Framework for Liquid State Machine Design
Apr 07, 2020
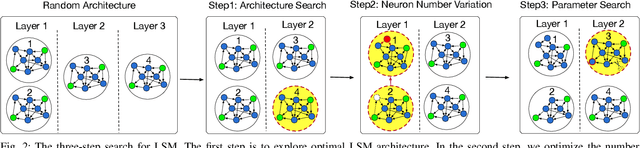
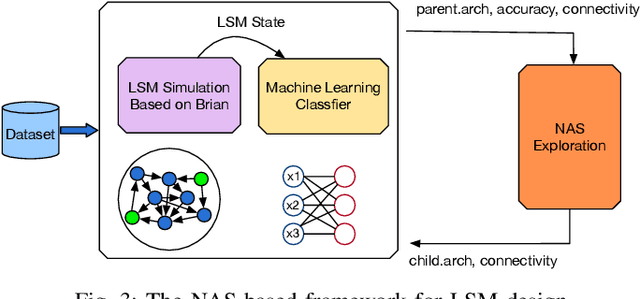

Liquid State Machine (LSM), also known as the recurrent version of Spiking Neural Networks (SNN), has attracted great research interests thanks to its high computational power, biological plausibility from the brain, simple structure and low training complexity. By exploring the design space in network architectures and parameters, recent works have demonstrated great potential for improving the accuracy of LSM model with low complexity. However, these works are based on manually-defined network architectures or predefined parameters. Considering the diversity and uniqueness of brain structure, the design of LSM model should be explored in the largest search space possible. In this paper, we propose a Neural Architecture Search (NAS) based framework to explore both architecture and parameter design space for automatic dataset-oriented LSM model. To handle the exponentially-increased design space, we adopt a three-step search for LSM, including multi-liquid architecture search, variation on the number of neurons and parameters search such as percentage connectivity and excitatory neuron ratio within each liquid. Besides, we propose to use Simulated Annealing (SA) algorithm to implement the three-step heuristic search. Three datasets, including image dataset of MNIST and NMNIST and speech dataset of FSDD, are used to test the effectiveness of our proposed framework. Simulation results show that our proposed framework can produce the dataset-oriented optimal LSM models with high accuracy and low complexity. The best classification accuracy on the three datasets is 93.2%, 92.5% and 84% respectively with only 1000 spiking neurons, and the network connections can be averagely reduced by 61.4% compared with a single LSM. Moreover, we find that the total quantity of neurons in optimal LSM models on three datasets can be further reduced by 20% with only about 0.5% accuracy loss.
Exploration of Input Patterns for Enhancing the Performance of Liquid State Machines
Apr 06, 2020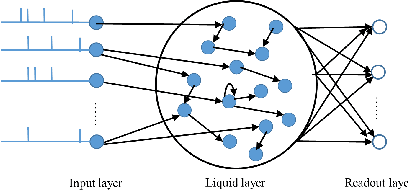
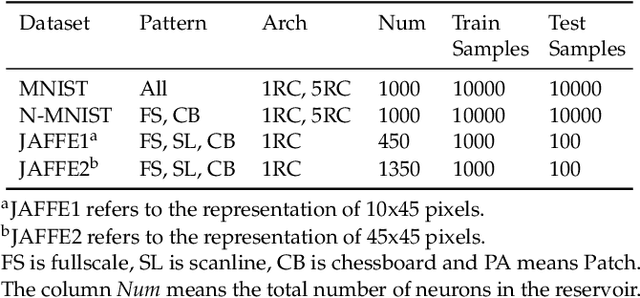


Spiking Neural Networks (SNN) have gained increasing attention for its low power consumption. But training SNN is challenging. Liquid State Machine (LSM), as a major type of Reservoir computing, has been widely recognized for its low training cost among SNNs. The exploration of LSM topology for enhancing performance often requires hyper-parameter search, which is both resource-expensive and time-consuming. We explore the influence of input scale reduction on LSM instead. There are two main reasons for studying input reduction of LSM. One is that the input dimension of large images requires efficient processing. Another one is that input exploration is generally more economic than architecture search. To mitigate the difficulty in effectively dealing with huge input spaces of LSM, and to find that whether input reduction can enhance LSM performance, we explore several input patterns, namely fullscale, scanline, chessboard, and patch. Several datasets have been used to evaluate the performance of the proposed input patterns, including two spatio image datasets and one spatio-temporal image database. The experimental results show that the reduced input under chessboard pattern improves the accuracy by up to 5%, and reduces execution time by up to 50% with up to 75\% less input storage than the fullscale input pattern for LSM.