 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOD-SGD: One-step Delay Stochastic Gradient Descent for Distributed Training
Paper and Code
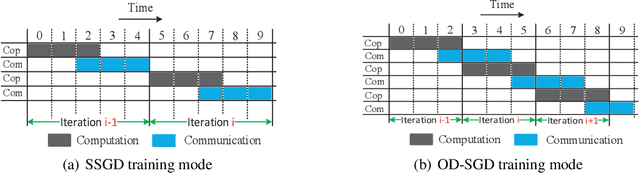


The training of modern deep learning neural network calls for large amounts of computation, which is often provided by GPUs or other specific accelerators. To scale out to achieve faster training speed, two update algorithms are mainly applied in the distributed training process, i.e. the Synchronous SGD algorithm (SSGD) and Asynchronous SGD algorithm (ASGD). SSGD obtains good convergence point while the training speed is slowed down by the synchronous barrier. ASGD has faster training speed but the convergence point is lower when compared to SSGD. To sufficiently utilize the advantages of SSGD and ASGD, we propose a novel technology named One-step Delay SGD (OD-SGD) to combine their strengths in the training process. Therefore, we can achieve similar convergence point and training speed as SSGD and ASGD separately. To the best of our knowledge, we make the first attempt to combine the features of SSGD and ASGD to improve distributed training performance. Each iteration of OD-SGD contains a global update in the parameter server node and local updates in the worker nodes, the local update is introduced to update and compensate the delayed local weights. We evaluate our proposed algorithm on MNIST, CIFAR-10 and ImageNet datasets. Experimental results show that OD-SGD can obtain similar or even slightly better accuracy than SSGD, while its training speed is much faster, which even exceeds the training speed of ASGD.