 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep learning framework for jointly solving transient Fokker-Planck equations with arbitrary parameters and initial distributions
Apr 07, 2026Efficiently solving the Fokker-Planck equation (FPE) is central to analyzing complex parameterized stochastic systems. However, current numerical methods lack parallel computation capabilities across varying conditions, severely limiting comprehensive parameter exploration and transient analysis. This paper introduces a deep learning-based pseudo-analytical probability solution (PAPS) that, via a single training process, simultaneously resolves transient FPE solutions for arbitrary multi-modal initial distributions, system parameters, and time points. The core idea is to unify initial, transient, and stationary distributions via Gaussian mixture distributions (GMDs) and develop a constraint-preserving autoencoder that bijectively maps constrained GMD parameters to unconstrained, low-dimensional latent representations. In this representation space, the panoramic transient dynamics across varying initial conditions and system parameters can be modeled by a single evolution network. Extensive experiments on paradigmatic systems demonstrate that the proposed PAPS maintains high accuracy while achieving inference speeds four orders of magnitude faster than GPU-accelerated Monte Carlo simulations. This efficiency leap enables previously intractable real-time parameter sweeps and systematic investigations of stochastic bifurcations. By decoupling representation learning from physics-informed transient dynamics, our work establishes a scalable paradigm for probabilistic modeling of multi-dimensional, parameterized stochastic systems.
FedBCD:Communication-Efficient Accelerated Block Coordinate Gradient Descent for Federated Learning
Mar 05, 2026Although Federated Learning has been widely studied in recent years, there are still high overhead expenses in each communication round for large-scale models such as Vision Transformer. To lower the communication complexity, we propose a novel Federated Block Coordinate Gradient Descent (FedBCGD) method for communication efficiency. The proposed method splits model parameters into several blocks, including a shared block and enables uploading a specific parameter block by each client, which can significantly reduce communication overhead. Moreover, we also develop an accelerated FedBCGD algorithm (called FedBCGD+) with client drift control and stochastic variance reduction. To the best of our knowledge, this paper is the first work on parameter block communication for training large-scale deep models. We also provide the convergence analysis for the proposed algorithms. Our theoretical results show that the communication complexities of our algorithms are a factor $1/N$ lower than those of existing methods, where $N$ is the number of parameter blocks, and they enjoy much faster convergence than their counterparts. Empirical results indicate the superiority of the proposed algorithms compared to state-of-the-art algorithms. The code is available at https://github.com/junkangLiu0/FedBCGD.
FedNSAM:Consistency of Local and Global Flatness for Federated Learning
Feb 27, 2026In federated learning (FL), multi-step local updates and data heterogeneity usually lead to sharper global minima, which degrades the performance of the global model. Popular FL algorithms integrate sharpness-aware minimization (SAM) into local training to address this issue. However, in the high data heterogeneity setting, the flatness in local training does not imply the flatness of the global model. Therefore, minimizing the sharpness of the local loss surfaces on the client data does not enable the effectiveness of SAM in FL to improve the generalization ability of the global model. We define the \textbf{flatness distance} to explain this phenomenon. By rethinking the SAM in FL and theoretically analyzing the \textbf{flatness distance}, we propose a novel \textbf{FedNSAM} algorithm that accelerates the SAM algorithm by introducing global Nesterov momentum into the local update to harmonize the consistency of global and local flatness. \textbf{FedNSAM} uses the global Nesterov momentum as the direction of local estimation of client global perturbations and extrapolation. Theoretically, we prove a tighter convergence bound than FedSAM by Nesterov extrapolation. Empirically, we conduct comprehensive experiments on CNN and Transformer models to verify the superior performance and efficiency of \textbf{FedNSAM}. The code is available at https://github.com/junkangLiu0/FedNSAM.
Taming Preconditioner Drift: Unlocking the Potential of Second-Order Optimizers for Federated Learning on Non-IID Data
Feb 22, 2026Second-order optimizers can significantly accelerate large-scale training, yet their naive federated variants are often unstable or even diverge on non-IID data. We show that a key culprit is \emph{preconditioner drift}: client-side second-order training induces heterogeneous \emph{curvature-defined geometries} (i.e., preconditioner coordinate systems), and server-side model averaging updates computed under incompatible metrics, corrupting the global descent direction. To address this geometric mismatch, we propose \texttt{FedPAC}, a \emph{preconditioner alignment and correction} framework for reliable federated second-order optimization. \texttt{FedPAC} explicitly decouples parameter aggregation from geometry synchronization by: (i) \textbf{Alignment} (i.e.,aggregating local preconditioners into a global reference and warm-starting clients via global preconditioner); and (ii) \textbf{Correction} (i.e., steering local preconditioned updates using a global preconditioned direction to suppress long-term drift). We provide drift-coupled non-convex convergence guarantees with linear speedup under partial participation. Empirically, \texttt{FedPAC} consistently improves stability and accuracy across vision and language tasks, achieving up to $5.8\%$ absolute accuracy gain on CIFAR-100 with ViTs. Code is available at https://anonymous.4open.science/r/FedPAC-8B24.
ClothHMR: 3D Mesh Recovery of Humans in Diverse Clothing from Single Image
Dec 19, 2025With 3D data rapidly emerging as an important form of multimedia information, 3D human mesh recovery technology has also advanced accordingly. However, current methods mainly focus on handling humans wearing tight clothing and perform poorly when estimating body shapes and poses under diverse clothing, especially loose garments. To this end, we make two key insights: (1) tailoring clothing to fit the human body can mitigate the adverse impact of clothing on 3D human mesh recovery, and (2) utilizing human visual information from large foundational models can enhance the generalization ability of the estimation. Based on these insights, we propose ClothHMR, to accurately recover 3D meshes of humans in diverse clothing. ClothHMR primarily consists of two modules: clothing tailoring (CT) and FHVM-based mesh recovering (MR). The CT module employs body semantic estimation and body edge prediction to tailor the clothing, ensuring it fits the body silhouette. The MR module optimizes the initial parameters of the 3D human mesh by continuously aligning the intermediate representations of the 3D mesh with those inferred from the foundational human visual model (FHVM). ClothHMR can accurately recover 3D meshes of humans wearing diverse clothing, precisely estimating their body shapes and poses. Experimental results demonstrate that ClothHMR significantly outperforms existing state-of-the-art methods across benchmark datasets and in-the-wild images. Additionally, a web application for online fashion and shopping powered by ClothHMR is developed, illustrating that ClothHMR can effectively serve real-world usage scenarios. The code and model for ClothHMR are available at: \url{https://github.com/starVisionTeam/ClothHMR}.
Smile on the Face, Sadness in the Eyes: Bridging the Emotion Gap with a Multimodal Dataset of Eye and Facial Behaviors
Dec 18, 2025Emotion Recognition (ER) is the process of analyzing and identifying human emotions from sensing data. Currently, the field heavily relies on facial expression recognition (FER) because visual channel conveys rich emotional cues. However, facial expressions are often used as social tools rather than manifestations of genuine inner emotions. To understand and bridge this gap between FER and ER, we introduce eye behaviors as an important emotional cue and construct an Eye-behavior-aided Multimodal Emotion Recognition (EMER) dataset. To collect data with genuine emotions, spontaneous emotion induction paradigm is exploited with stimulus material, during which non-invasive eye behavior data, like eye movement sequences and eye fixation maps, is captured together with facial expression videos. To better illustrate the gap between ER and FER, multi-view emotion labels for mutimodal ER and FER are separately annotated. Furthermore, based on the new dataset, we design a simple yet effective Eye-behavior-aided MER Transformer (EMERT) that enhances ER by bridging the emotion gap. EMERT leverages modality-adversarial feature decoupling and a multitask Transformer to model eye behaviors as a strong complement to facial expressions. In the experiment, we introduce seven multimodal benchmark protocols for a variety of comprehensive evaluations of the EMER dataset. The results show that the EMERT outperforms other state-of-the-art multimodal methods by a great margin, revealing the importance of modeling eye behaviors for robust ER. To sum up, we provide a comprehensive analysis of the importance of eye behaviors in ER, advancing the study on addressing the gap between FER and ER for more robust ER performance. Our EMER dataset and the trained EMERT models will be publicly available at https://github.com/kejun1/EMER.
View-on-Graph: Zero-shot 3D Visual Grounding via Vision-Language Reasoning on Scene Graphs
Dec 10, 20253D visual grounding (3DVG) identifies objects in 3D scenes from language descriptions. Existing zero-shot approaches leverage 2D vision-language models (VLMs) by converting 3D spatial information (SI) into forms amenable to VLM processing, typically as composite inputs such as specified view renderings or video sequences with overlaid object markers. However, this VLM + SI paradigm yields entangled visual representations that compel the VLM to process entire cluttered cues, making it hard to exploit spatial semantic relationships effectively. In this work, we propose a new VLM x SI paradigm that externalizes the 3D SI into a form enabling the VLM to incrementally retrieve only what it needs during reasoning. We instantiate this paradigm with a novel View-on-Graph (VoG) method, which organizes the scene into a multi-modal, multi-layer scene graph and allows the VLM to operate as an active agent that selectively accesses necessary cues as it traverses the scene. This design offers two intrinsic advantages: (i) by structuring 3D context into a spatially and semantically coherent scene graph rather than confounding the VLM with densely entangled visual inputs, it lowers the VLM's reasoning difficulty; and (ii) by actively exploring and reasoning over the scene graph, it naturally produces transparent, step-by-step traces for interpretable 3DVG. Extensive experiments show that VoG achieves state-of-the-art zero-shot performance, establishing structured scene exploration as a promising strategy for advancing zero-shot 3DVG.
When Genes Speak: A Semantic-Guided Framework for Spatially Resolved Transcriptomics Data Clustering
Nov 14, 2025Spatial transcriptomics enables gene expression profiling with spatial context, offering unprecedented insights into the tissue microenvironment. However, most computational models treat genes as isolated numerical features, ignoring the rich biological semantics encoded in their symbols. This prevents a truly deep understanding of critical biological characteristics. To overcome this limitation, we present SemST, a semantic-guided deep learning framework for spatial transcriptomics data clustering. SemST leverages Large Language Models (LLMs) to enable genes to "speak" through their symbolic meanings, transforming gene sets within each tissue spot into biologically informed embeddings. These embeddings are then fused with the spatial neighborhood relationships captured by Graph Neural Networks (GNNs), achieving a coherent integration of biological function and spatial structure. We further introduce the Fine-grained Semantic Modulation (FSM) module to optimally exploit these biological priors. The FSM module learns spot-specific affine transformations that empower the semantic embeddings to perform an element-wise calibration of the spatial features, thus dynamically injecting high-order biological knowledge into the spatial context. Extensive experiments on public spatial transcriptomics datasets show that SemST achieves state-of-the-art clustering performance. Crucially, the FSM module exhibits plug-and-play versatility, consistently improving the performance when integrated into other baseline methods.
FedMuon: Accelerating Federated Learning with Matrix Orthogonalization
Oct 31, 2025The core bottleneck of Federated Learning (FL) lies in the communication rounds. That is, how to achieve more effective local updates is crucial for reducing communication rounds. Existing FL methods still primarily use element-wise local optimizers (Adam/SGD), neglecting the geometric structure of the weight matrices. This often leads to the amplification of pathological directions in the weights during local updates, leading deterioration in the condition number and slow convergence. Therefore, we introduce the Muon optimizer in local, which has matrix orthogonalization to optimize matrix-structured parameters. Experimental results show that, in IID setting, Local Muon significantly accelerates the convergence of FL and reduces communication rounds compared to Local SGD and Local AdamW. However, in non-IID setting, independent matrix orthogonalization based on the local distributions of each client induces strong client drift. Applying Muon in non-IID FL poses significant challenges: (1) client preconditioner leading to client drift; (2) moment reinitialization. To address these challenges, we propose a novel Federated Muon optimizer (FedMuon), which incorporates two key techniques: (1) momentum aggregation, where clients use the aggregated momentum for local initialization; (2) local-global alignment, where the local gradients are aligned with the global update direction to significantly reduce client drift. Theoretically, we prove that \texttt{FedMuon} achieves a linear speedup convergence rate without the heterogeneity assumption, where $S$ is the number of participating clients per round, $K$ is the number of local iterations, and $R$ is the total number of communication rounds. Empirically, we validate the effectiveness of FedMuon on language and vision models. Compared to several baselines, FedMuon significantly reduces communication rounds and improves test accuracy.
FedAdamW: A Communication-Efficient Optimizer with Convergence and Generalization Guarantees for Federated Large Models
Oct 31, 2025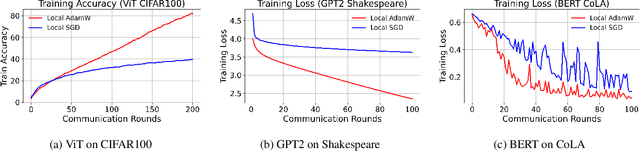
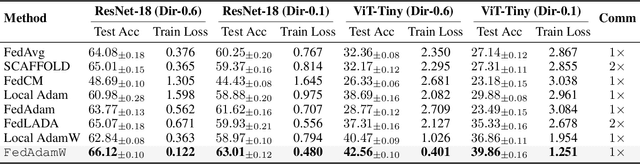
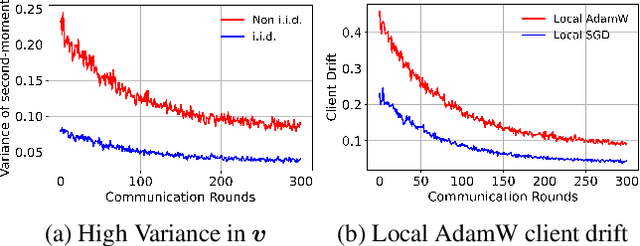
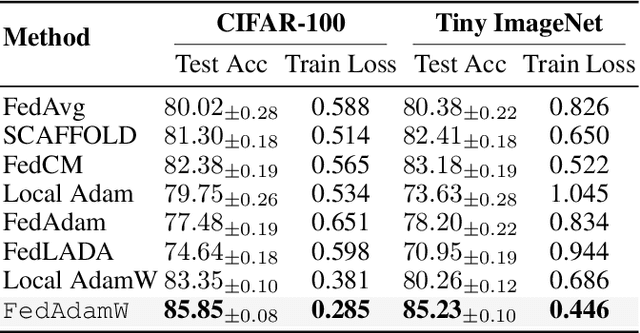
AdamW has become one of the most effective optimizers for training large-scale models. We have also observed its effectiveness in the context of federated learning (FL). However, directly applying AdamW in federated learning settings poses significant challenges: (1) due to data heterogeneity, AdamW often yields high variance in the second-moment estimate $\boldsymbol{v}$; (2) the local overfitting of AdamW may cause client drift; and (3) Reinitializing moment estimates ($\boldsymbol{v}$, $\boldsymbol{m}$) at each round slows down convergence. To address these challenges, we propose the first \underline{Fed}erated \underline{AdamW} algorithm, called \texttt{FedAdamW}, for training and fine-tuning various large models. \texttt{FedAdamW} aligns local updates with the global update using both a \textbf{local correction mechanism} and decoupled weight decay to mitigate local overfitting. \texttt{FedAdamW} efficiently aggregates the \texttt{mean} of the second-moment estimates to reduce their variance and reinitialize them. Theoretically, we prove that \texttt{FedAdamW} achieves a linear speedup convergence rate of $\mathcal{O}(\sqrt{(L \Delta \sigma_l^2)/(S K R \epsilon^2)}+(L \Delta)/R)$ without \textbf{heterogeneity assumption}, where $S$ is the number of participating clients per round, $K$ is the number of local iterations, and $R$ is the total number of communication rounds. We also employ PAC-Bayesian generalization analysis to explain the effectiveness of decoupled weight decay in local training. Empirically, we validate the effectiveness of \texttt{FedAdamW} on language and vision Transformer models. Compared to several baselines, \texttt{FedAdamW} significantly reduces communication rounds and improves test accuracy. The code is available in https://github.com/junkangLiu0/FedAdamW.