 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenting and Understanding: Region-aware Semantic Attention for Fine-grained Image Quality Assessment with Large Language Models
Aug 11, 2025No-reference image quality assessment (NR-IQA) aims to simulate the process of perceiving image quality aligned with subjective human perception. However, existing NR-IQA methods either focus on global representations that leads to limited insights into the semantically salient regions or employ a uniform weighting for region features that weakens the sensitivity to local quality variations. In this paper, we propose a fine-grained image quality assessment model, named RSFIQA, which integrates region-level distortion information to perceive multi-dimensional quality discrepancies. To enhance regional quality awareness, we first utilize the Segment Anything Model (SAM) to dynamically partition the input image into non-overlapping semantic regions. For each region, we teach a powerful Multi-modal Large Language Model (MLLM) to extract descriptive content and perceive multi-dimensional distortions, enabling a comprehensive understanding of both local semantics and quality degradations. To effectively leverage this information, we introduce Region-Aware Semantic Attention (RSA) mechanism, which generates a global attention map by aggregating fine-grained representations from local regions. In addition, RSFIQA is backbone-agnostic and can be seamlessly integrated into various deep neural network architectures. Extensive experiments demonstrate the robustness and effectiveness of the proposed method, which achieves competitive quality prediction performance across multiple benchmark datasets.
Q-CLIP: Unleashing the Power of Vision-Language Models for Video Quality Assessment through Unified Cross-Modal Adaptation
Aug 08, 2025Accurate and efficient Video Quality Assessment (VQA) has long been a key research challenge. Current mainstream VQA methods typically improve performance by pretraining on large-scale classification datasets (e.g., ImageNet, Kinetics-400), followed by fine-tuning on VQA datasets. However, this strategy presents two significant challenges: (1) merely transferring semantic knowledge learned from pretraining is insufficient for VQA, as video quality depends on multiple factors (e.g., semantics, distortion, motion, aesthetics); (2) pretraining on large-scale datasets demands enormous computational resources, often dozens or even hundreds of times greater than training directly on VQA datasets. Recently, Vision-Language Models (VLMs) have shown remarkable generalization capabilities across a wide range of visual tasks, and have begun to demonstrate promising potential in quality assessment. In this work, we propose Q-CLIP, the first fully VLMs-based framework for VQA. Q-CLIP enhances both visual and textual representations through a Shared Cross-Modal Adapter (SCMA), which contains only a minimal number of trainable parameters and is the only component that requires training. This design significantly reduces computational cost. In addition, we introduce a set of five learnable quality-level prompts to guide the VLMs in perceiving subtle quality variations, thereby further enhancing the model's sensitivity to video quality. Furthermore, we investigate the impact of different frame sampling strategies on VQA performance, and find that frame-difference-based sampling leads to better generalization performance across datasets. Extensive experiments demonstrate that Q-CLIP exhibits excellent performance on several VQA datasets.
UGD-IML: A Unified Generative Diffusion-based Framework for Constrained and Unconstrained Image Manipulation Localization
Aug 08, 2025In the digital age, advanced image editing tools pose a serious threat to the integrity of visual content, making image forgery detection and localization a key research focus. Most existing Image Manipulation Localization (IML) methods rely on discriminative learning and require large, high-quality annotated datasets. However, current datasets lack sufficient scale and diversity, limiting model performance in real-world scenarios. To overcome this, recent studies have explored Constrained IML (CIML), which generates pixel-level annotations through algorithmic supervision. However, existing CIML approaches often depend on complex multi-stage pipelines, making the annotation process inefficient. In this work, we propose a novel generative framework based on diffusion models, named UGD-IML, which for the first time unifies both IML and CIML tasks within a single framework. By learning the underlying data distribution, generative diffusion models inherently reduce the reliance on large-scale labeled datasets, allowing our approach to perform effectively even under limited data conditions. In addition, by leveraging a class embedding mechanism and a parameter-sharing design, our model seamlessly switches between IML and CIML modes without extra components or training overhead. Furthermore, the end-to-end design enables our model to avoid cumbersome steps in the data annotation process. Extensive experimental results on multiple datasets demonstrate that UGD-IML outperforms the SOTA methods by an average of 9.66 and 4.36 in terms of F1 metrics for IML and CIML tasks, respectively. Moreover, the proposed method also excels in uncertainty estimation, visualization and robustness.
MVQA: Mamba with Unified Sampling for Efficient Video Quality Assessment
Apr 22, 2025The rapid growth of long-duration, high-definition videos has made efficient video quality assessment (VQA) a critical challenge. Existing research typically tackles this problem through two main strategies: reducing model parameters and resampling inputs. However, light-weight Convolution Neural Networks (CNN) and Transformers often struggle to balance efficiency with high performance due to the requirement of long-range modeling capabilities. Recently, the state-space model, particularly Mamba, has emerged as a promising alternative, offering linear complexity with respect to sequence length. Meanwhile, efficient VQA heavily depends on resampling long sequences to minimize computational costs, yet current resampling methods are often weak in preserving essential semantic information. In this work, we present MVQA, a Mamba-based model designed for efficient VQA along with a novel Unified Semantic and Distortion Sampling (USDS) approach. USDS combines semantic patch sampling from low-resolution videos and distortion patch sampling from original-resolution videos. The former captures semantically dense regions, while the latter retains critical distortion details. To prevent computation increase from dual inputs, we propose a fusion mechanism using pre-defined masks, enabling a unified sampling strategy that captures both semantic and quality information without additional computational burden. Experiments show that the proposed MVQA, equipped with USDS, achieve comparable performance to state-of-the-art methods while being $2\times$ as fast and requiring only $1/5$ GPU memory.
CLiF-VQA: Enhancing Video Quality Assessment by Incorporating High-Level Semantic Information related to Human Feelings
Nov 13, 2023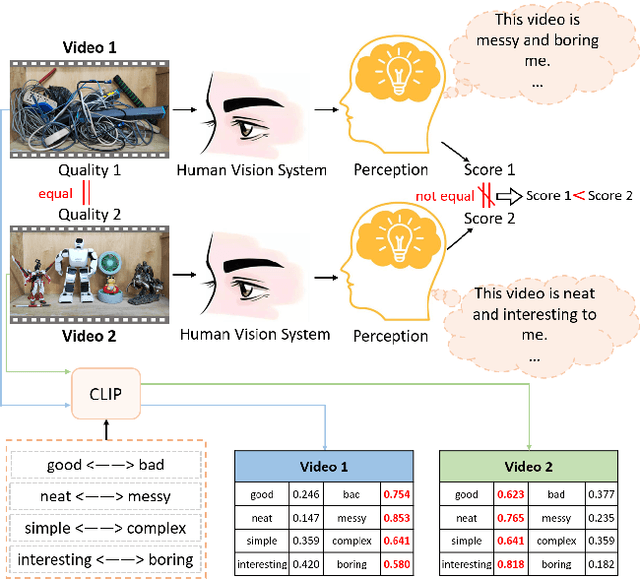
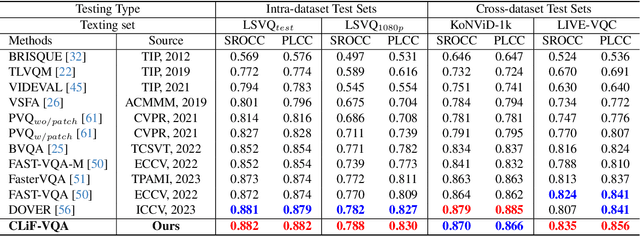
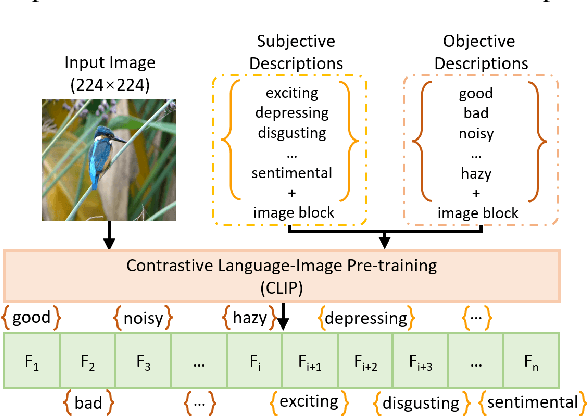
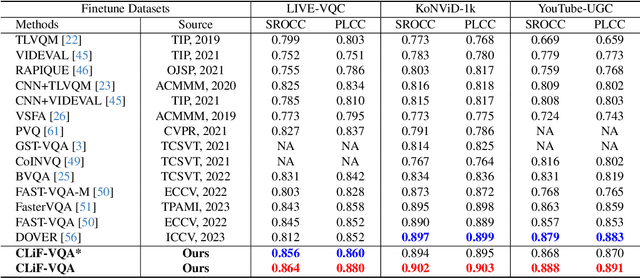
Video Quality Assessment (VQA) aims to simulate the process of perceiving video quality by the human visual system (HVS). The judgments made by HVS are always influenced by human subjective feelings. However, most of the current VQA research focuses on capturing various distortions in the spatial and temporal domains of videos, while ignoring the impact of human feelings. In this paper, we propose CLiF-VQA, which considers both features related to human feelings and spatial features of videos. In order to effectively extract features related to human feelings from videos, we explore the consistency between CLIP and human feelings in video perception for the first time. Specifically, we design multiple objective and subjective descriptions closely related to human feelings as prompts. Further we propose a novel CLIP-based semantic feature extractor (SFE) which extracts features related to human feelings by sliding over multiple regions of the video frame. In addition, we further capture the low-level-aware features of the video through a spatial feature extraction module. The two different features are then aggregated thereby obtaining the quality score of the video. Extensive experiments show that the proposed CLiF-VQA exhibits excellent performance on several VQA datasets.