 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Dirac Delta: Mitigating Diversity Collapse in Reinforcement Fine-Tuning for Versatile Image Generation
Jan 18, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning large-scale generative models, such as diffusion and flow models, to align with complex human preferences and user-specified tasks. A fundamental limitation remains \textit{the curse of diversity collapse}, where the objective formulation and optimization landscape inherently collapse the policy to a Dirac delta distribution. To address this challenge, we propose \textbf{DRIFT} (\textbf{D}ive\textbf{R}sity-\textbf{I}ncentivized Reinforcement \textbf{F}ine-\textbf{T}uning for Versatile Image Generation), an innovative framework that systematically incentivizes output diversity throughout the on-policy fine-tuning process, reconciling strong task alignment with high generation diversity to enhance versatility essential for applications that demand diverse candidate generations. We approach the problem across three representative perspectives: i) \textbf{sampling} a reward-concentrated subset that filters out reward outliers to prevent premature collapse; ii) \textbf{prompting} with stochastic variations to expand the conditioning space, and iii) \textbf{optimization} of the intra-group diversity with a potential-based reward shaping mechanism. Experimental results show that DRIFT achieves superior Pareto dominance regarding task alignment and generation diversity, yielding a $ 9.08\%\!\sim\! 43.46\%$ increase in diversity at equivalent alignment levels and a $ 59.65\% \!\sim\! 65.86\%$ increase in alignment at equivalent levels of diversity.
GaussianMorphing: Mesh-Guided 3D Gaussians for Semantic-Aware Object Morphing
Oct 02, 2025We introduce GaussianMorphing, a novel framework for semantic-aware 3D shape and texture morphing from multi-view images. Previous approaches usually rely on point clouds or require pre-defined homeomorphic mappings for untextured data. Our method overcomes these limitations by leveraging mesh-guided 3D Gaussian Splatting (3DGS) for high-fidelity geometry and appearance modeling. The core of our framework is a unified deformation strategy that anchors 3DGaussians to reconstructed mesh patches, ensuring geometrically consistent transformations while preserving texture fidelity through topology-aware constraints. In parallel, our framework establishes unsupervised semantic correspondence by using the mesh topology as a geometric prior and maintains structural integrity via physically plausible point trajectories. This integrated approach preserves both local detail and global semantic coherence throughout the morphing process with out requiring labeled data. On our proposed TexMorph benchmark, GaussianMorphing substantially outperforms prior 2D/3D methods, reducing color consistency error ($\Delta E$) by 22.2% and EI by 26.2%. Project page: https://baiyunshu.github.io/GAUSSIANMORPHING.github.io/
MVQA: Mamba with Unified Sampling for Efficient Video Quality Assessment
Apr 22, 2025The rapid growth of long-duration, high-definition videos has made efficient video quality assessment (VQA) a critical challenge. Existing research typically tackles this problem through two main strategies: reducing model parameters and resampling inputs. However, light-weight Convolution Neural Networks (CNN) and Transformers often struggle to balance efficiency with high performance due to the requirement of long-range modeling capabilities. Recently, the state-space model, particularly Mamba, has emerged as a promising alternative, offering linear complexity with respect to sequence length. Meanwhile, efficient VQA heavily depends on resampling long sequences to minimize computational costs, yet current resampling methods are often weak in preserving essential semantic information. In this work, we present MVQA, a Mamba-based model designed for efficient VQA along with a novel Unified Semantic and Distortion Sampling (USDS) approach. USDS combines semantic patch sampling from low-resolution videos and distortion patch sampling from original-resolution videos. The former captures semantically dense regions, while the latter retains critical distortion details. To prevent computation increase from dual inputs, we propose a fusion mechanism using pre-defined masks, enabling a unified sampling strategy that captures both semantic and quality information without additional computational burden. Experiments show that the proposed MVQA, equipped with USDS, achieve comparable performance to state-of-the-art methods while being $2\times$ as fast and requiring only $1/5$ GPU memory.
Combining Generative and Geometry Priors for Wide-Angle Portrait Correction
Oct 13, 2024Wide-angle lens distortion in portrait photography presents a significant challenge for capturing photo-realistic and aesthetically pleasing images. Such distortions are especially noticeable in facial regions. In this work, we propose encapsulating the generative face prior as a guided natural manifold to facilitate the correction of facial regions. Moreover, a notable central symmetry relationship exists in the non-face background, yet it has not been explored in the correction process. This geometry prior motivates us to introduce a novel constraint to explicitly enforce symmetry throughout the correction process, thereby contributing to a more visually appealing and natural correction in the non-face region. Experiments demonstrate that our approach outperforms previous methods by a large margin, excelling not only in quantitative measures such as line straightness and shape consistency metrics but also in terms of perceptual visual quality. All the code and models are available at https://github.com/Dev-Mrha/DualPriorsCorrection.
Text4Seg: Reimagining Image Segmentation as Text Generation
Oct 13, 2024
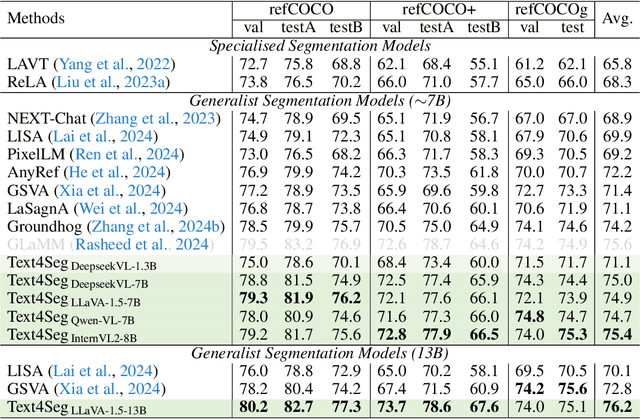
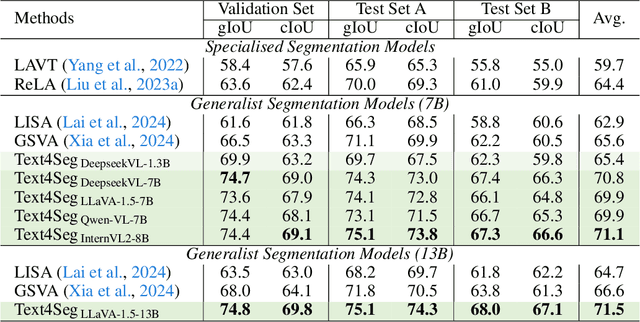
Multimodal Large Language Models (MLLMs) have shown exceptional capabilities in vision-language tasks; however, effectively integrating image segmentation into these models remains a significant challenge. In this paper, we introduce Text4Seg, a novel text-as-mask paradigm that casts image segmentation as a text generation problem, eliminating the need for additional decoders and significantly simplifying the segmentation process. Our key innovation is semantic descriptors, a new textual representation of segmentation masks where each image patch is mapped to its corresponding text label. This unified representation allows seamless integration into the auto-regressive training pipeline of MLLMs for easier optimization. We demonstrate that representing an image with $16\times16$ semantic descriptors yields competitive segmentation performance. To enhance efficiency, we introduce the Row-wise Run-Length Encoding (R-RLE), which compresses redundant text sequences, reducing the length of semantic descriptors by 74% and accelerating inference by $3\times$, without compromising performance. Extensive experiments across various vision tasks, such as referring expression segmentation and comprehension, show that Text4Seg achieves state-of-the-art performance on multiple datasets by fine-tuning different MLLM backbones. Our approach provides an efficient, scalable solution for vision-centric tasks within the MLLM framework.
MRSE: An Efficient Multi-modality Retrieval System for Large Scale E-commerce
Aug 27, 2024



Providing high-quality item recall for text queries is crucial in large-scale e-commerce search systems. Current Embedding-based Retrieval Systems (ERS) embed queries and items into a shared low-dimensional space, but uni-modality ERS rely too heavily on textual features, making them unreliable in complex contexts. While multi-modality ERS incorporate various data sources, they often overlook individual preferences for different modalities, leading to suboptimal results. To address these issues, we propose MRSE, a Multi-modality Retrieval System that integrates text, item images, and user preferences through lightweight mixture-of-expert (LMoE) modules to better align features across and within modalities. MRSE also builds user profiles at a multi-modality level and introduces a novel hybrid loss function that enhances consistency and robustness using hard negative sampling. Experiments on a large-scale dataset from Shopee and online A/B testing show that MRSE achieves an 18.9% improvement in offline relevance and a 3.7% gain in online core metrics compared to Shopee's state-of-the-art uni-modality system.
ProxyCLIP: Proxy Attention Improves CLIP for Open-Vocabulary Segmentation
Aug 09, 2024Open-vocabulary semantic segmentation requires models to effectively integrate visual representations with open-vocabulary semantic labels. While Contrastive Language-Image Pre-training (CLIP) models shine in recognizing visual concepts from text, they often struggle with segment coherence due to their limited localization ability. In contrast, Vision Foundation Models (VFMs) excel at acquiring spatially consistent local visual representations, yet they fall short in semantic understanding. This paper introduces ProxyCLIP, an innovative framework designed to harmonize the strengths of both CLIP and VFMs, facilitating enhanced open-vocabulary semantic segmentation. ProxyCLIP leverages the spatial feature correspondence from VFMs as a form of proxy attention to augment CLIP, thereby inheriting the VFMs' robust local consistency and maintaining CLIP's exceptional zero-shot transfer capacity. We propose an adaptive normalization and masking strategy to get the proxy attention from VFMs, allowing for adaptation across different VFMs. Remarkably, as a training-free approach, ProxyCLIP significantly improves the average mean Intersection over Union (mIoU) across eight benchmarks from 40.3 to 44.4, showcasing its exceptional efficacy in bridging the gap between spatial precision and semantic richness for the open-vocabulary segmentation task.
Q-Ground: Image Quality Grounding with Large Multi-modality Models
Jul 24, 2024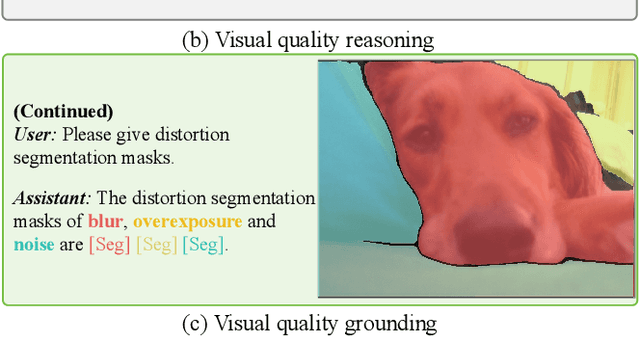

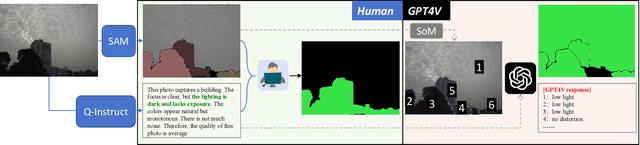

Recent advances of large multi-modality models (LMM) have greatly improved the ability of image quality assessment (IQA) method to evaluate and explain the quality of visual content. However, these advancements are mostly focused on overall quality assessment, and the detailed examination of local quality, which is crucial for comprehensive visual understanding, is still largely unexplored. In this work, we introduce Q-Ground, the first framework aimed at tackling fine-scale visual quality grounding by combining large multi-modality models with detailed visual quality analysis. Central to our contribution is the introduction of the QGround-100K dataset, a novel resource containing 100k triplets of (image, quality text, distortion segmentation) to facilitate deep investigations into visual quality. The dataset comprises two parts: one with human-labeled annotations for accurate quality assessment, and another labeled automatically by LMMs such as GPT4V, which helps improve the robustness of model training while also reducing the costs of data collection. With the QGround-100K dataset, we propose a LMM-based method equipped with multi-scale feature learning to learn models capable of performing both image quality answering and distortion segmentation based on text prompts. This dual-capability approach not only refines the model's understanding of region-aware image quality but also enables it to interactively respond to complex, text-based queries about image quality and specific distortions. Q-Ground takes a step towards sophisticated visual quality analysis in a finer scale, establishing a new benchmark for future research in the area. Codes and dataset are available at https://github.com/Q-Future/Q-Ground.
ClearCLIP: Decomposing CLIP Representations for Dense Vision-Language Inference
Jul 17, 2024



Despite the success of large-scale pretrained Vision-Language Models (VLMs) especially CLIP in various open-vocabulary tasks, their application to semantic segmentation remains challenging, producing noisy segmentation maps with mis-segmented regions. In this paper, we carefully re-investigate the architecture of CLIP, and identify residual connections as the primary source of noise that degrades segmentation quality. With a comparative analysis of statistical properties in the residual connection and the attention output across different pretrained models, we discover that CLIP's image-text contrastive training paradigm emphasizes global features at the expense of local discriminability, leading to noisy segmentation results. In response, we propose ClearCLIP, a novel approach that decomposes CLIP's representations to enhance open-vocabulary semantic segmentation. We introduce three simple modifications to the final layer: removing the residual connection, implementing the self-self attention, and discarding the feed-forward network. ClearCLIP consistently generates clearer and more accurate segmentation maps and outperforms existing approaches across multiple benchmarks, affirming the significance of our discoveries.
G-Refine: A General Quality Refiner for Text-to-Image Generation
Apr 29, 2024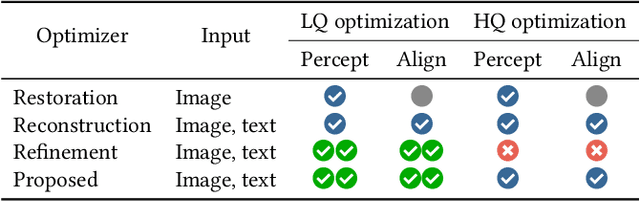
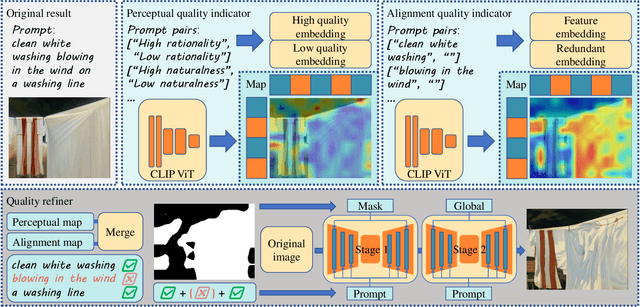
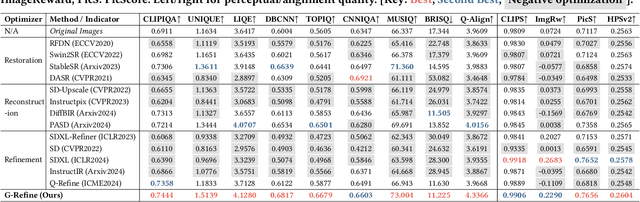
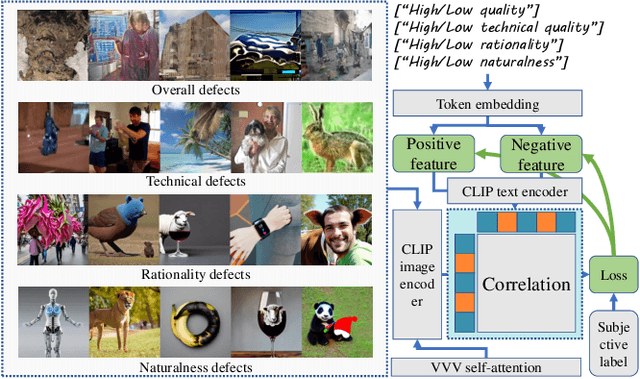
With the evolution of Text-to-Image (T2I) models, the quality defects of AI-Generated Images (AIGIs) pose a significant barrier to their widespread adoption. In terms of both perception and alignment, existing models cannot always guarantee high-quality results. To mitigate this limitation, we introduce G-Refine, a general image quality refiner designed to enhance low-quality images without compromising the integrity of high-quality ones. The model is composed of three interconnected modules: a perception quality indicator, an alignment quality indicator, and a general quality enhancement module. Based on the mechanisms of the Human Visual System (HVS) and syntax trees, the first two indicators can respectively identify the perception and alignment deficiencies, and the last module can apply targeted quality enhancement accordingly. Extensive experimentation reveals that when compared to alternative optimization methods, AIGIs after G-Refine outperform in 10+ quality metrics across 4 databases. This improvement significantly contributes to the practical application of contemporary T2I models, paving the way for their broader adoption. The code will be released on https://github.com/Q-Future/Q-Refine.