 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Tacit: Image Quality Assessment via Latent Visual Reasoning
Mar 23, 2026Vision-Language Model (VLM)-based image quality assessment (IQA) has been significantly advanced by incorporating Chain-of-Thought (CoT) reasoning. Recent work has refined image quality reasoning by applying reinforcement learning (RL) and leveraging active visual tools. However, such strategies are typically language-centric, with visual information being treated as static preconditions. Quality-related visual cues often cannot be abstracted into text in extenso due to the gap between discrete textual tokens and quality perception space, which in turn restricts the reasoning effectiveness for visually intensive IQA tasks. In this paper, we revisit this by asking the question, "Is natural language the ideal space for quality reasoning?" and, as a consequence, we propose Q-Tacit, a new paradigm that elicits VLMs to reason beyond natural language in the latent quality space. Our approach follows a synergistic two-stage process: (i) injecting structural visual quality priors into the latent space, and (ii) calibrating latent reasoning trajectories to improve quality assessment ability. Extensive experiments demonstrate that Q-Tacit can effectively perform quality reasoning with significantly fewer tokens than previous reasoning-based methods, while achieving strong overall performance. This paper validates the proposition that language is not the only compact representation suitable for visual quality, opening possibilities for further exploration of effective latent reasoning paradigms for IQA. Source code will be released to support future research.
EduVQA: Benchmarking AI-Generated Video Quality Assessment for Education
Mar 03, 2026While AI-generated content (AIGC) models have achieved remarkable success in generating photorealistic videos, their potential to support visual, story-driven learning in education remains largely untapped. To close this gap, we present EduAIGV-1k, the first benchmark dataset and evaluation framework dedicated to assessing the quality of AI-generated videos (AIGVs) designed to teach foundational math concepts, such as numbers and geometry, to young learners. EduAIGV-1k contains 1,130 short videos produced by ten state-of-the-art text-to-video (T2V) models using 113 pedagogy-oriented prompts. Each video is accompanied by rich, fine-grained annotations along two complementary axes: (1) Perceptual quality, disentangled into spatial and temporal fidelity, and (2) Prompt alignment, labeled at the word-level and sentence-level to quantify the degree to which each mathematical concept in the prompt is accurately grounded in the generated video. These fine-grained annotations transform each video into a multi-dimensional, interpretable supervision signal, far beyond a single quality score. Leveraging this dense feedback, we introduce EduVQA for both perceptual and alignment quality assessment of AIGVs. In particular, we propose a Structured 2D Mixture-of-Experts (S2D-MoE) module, which enhances the dependency between overall quality and each sub-dimension by shared experts and dynamic 2D gating matrix. Extensive experiments show our EduVQA consistently outperforms existing VQA baselines. Both our dataset and code will be publicly available.
From Global to Granular: Revealing IQA Model Performance via Correlation Surface
Jan 29, 2026Evaluation of Image Quality Assessment (IQA) models has long been dominated by global correlation metrics, such as Pearson Linear Correlation Coefficient (PLCC) and Spearman Rank-Order Correlation Coefficient (SRCC). While widely adopted, these metrics reduce performance to a single scalar, failing to capture how ranking consistency varies across the local quality spectrum. For example, two IQA models may achieve identical SRCC values, yet one ranks high-quality images (related to high Mean Opinion Score, MOS) more reliably, while the other better discriminates image pairs with small quality/MOS differences (related to $|Δ$MOS$|$). Such complementary behaviors are invisible under global metrics. Moreover, SRCC and PLCC are sensitive to test-sample quality distributions, yielding unstable comparisons across test sets. To address these limitations, we propose \textbf{Granularity-Modulated Correlation (GMC)}, which provides a structured, fine-grained analysis of IQA performance. GMC includes: (1) a \textbf{Granularity Modulator} that applies Gaussian-weighted correlations conditioned on absolute MOS values and pairwise MOS differences ($|Δ$MOS$|$) to examine local performance variations, and (2) a \textbf{Distribution Regulator} that regularizes correlations to mitigate biases from non-uniform quality distributions. The resulting \textbf{correlation surface} maps correlation values as a joint function of MOS and $|Δ$MOS$|$, providing a 3D representation of IQA performance. Experiments on standard benchmarks show that GMC reveals performance characteristics invisible to scalar metrics, offering a more informative and reliable paradigm for analyzing, comparing, and deploying IQA models. Codes are available at https://github.com/Dniaaa/GMC.
Plug In, Grade Right: Psychology-Inspired AGIQA
Dec 28, 2025Existing AGIQA models typically estimate image quality by measuring and aggregating the similarities between image embeddings and text embeddings derived from multi-grade quality descriptions. Although effective, we observe that such similarity distributions across grades usually exhibit multimodal patterns. For instance, an image embedding may show high similarity to both "excellent" and "poor" grade descriptions while deviating from the "good" one. We refer to this phenomenon as "semantic drift", where semantic inconsistencies between text embeddings and their intended descriptions undermine the reliability of text-image shared-space learning. To mitigate this issue, we draw inspiration from psychometrics and propose an improved Graded Response Model (GRM) for AGIQA. The GRM is a classical assessment model that categorizes a subject's ability across grades using test items with various difficulty levels. This paradigm aligns remarkably well with human quality rating, where image quality can be interpreted as an image's ability to meet various quality grades. Building on this philosophy, we design a two-branch quality grading module: one branch estimates image ability while the other constructs multiple difficulty levels. To ensure monotonicity in difficulty levels, we further model difficulty generation in an arithmetic manner, which inherently enforces a unimodal and interpretable quality distribution. Our Arithmetic GRM based Quality Grading (AGQG) module enjoys a plug-and-play advantage, consistently improving performance when integrated into various state-of-the-art AGIQA frameworks. Moreover, it also generalizes effectively to both natural and screen content image quality assessment, revealing its potential as a key component in future IQA models.
Simple Lines, Big Ideas: Towards Interpretable Assessment of Human Creativity from Drawings
Nov 17, 2025Assessing human creativity through visual outputs, such as drawings, plays a critical role in fields including psychology, education, and cognitive science. However, current assessment practices still rely heavily on expert-based subjective scoring, which is both labor-intensive and inherently subjective. In this paper, we propose a data-driven framework for automatic and interpretable creativity assessment from drawings. Motivated by the cognitive understanding that creativity can emerge from both what is drawn (content) and how it is drawn (style), we reinterpret the creativity score as a function of these two complementary dimensions.Specifically, we first augment an existing creativity labeled dataset with additional annotations targeting content categories. Based on the enriched dataset, we further propose a multi-modal, multi-task learning framework that simultaneously predicts creativity scores, categorizes content types, and extracts stylistic features. In particular, we introduce a conditional learning mechanism that enables the model to adapt its visual feature extraction by dynamically tuning it to creativity-relevant signals conditioned on the drawing's stylistic and semantic cues.Experimental results demonstrate that our model achieves state-of-the-art performance compared to existing regression-based approaches and offers interpretable visualizations that align well with human judgments. The code and annotations will be made publicly available at https://github.com/WonderOfU9/CSCA_PRCV_2025
Q-Doc: Benchmarking Document Image Quality Assessment Capabilities in Multi-modal Large Language Models
Nov 14, 2025The rapid advancement of Multi-modal Large Language Models (MLLMs) has expanded their capabilities beyond high-level vision tasks. Nevertheless, their potential for Document Image Quality Assessment (DIQA) remains underexplored. To bridge this gap, we propose Q-Doc, a three-tiered evaluation framework for systematically probing DIQA capabilities of MLLMs at coarse, middle, and fine granularity levels. a) At the coarse level, we instruct MLLMs to assign quality scores to document images and analyze their correlation with Quality Annotations. b) At the middle level, we design distortion-type identification tasks, including single-choice and multi-choice tests for multi-distortion scenarios. c) At the fine level, we introduce distortion-severity assessment where MLLMs classify distortion intensity against human-annotated references. Our evaluation demonstrates that while MLLMs possess nascent DIQA abilities, they exhibit critical limitations: inconsistent scoring, distortion misidentification, and severity misjudgment. Significantly, we show that Chain-of-Thought (CoT) prompting substantially enhances performance across all levels. Our work provides a benchmark for DIQA capabilities in MLLMs, revealing pronounced deficiencies in their quality perception and promising pathways for enhancement. The benchmark and code are publicly available at: https://github.com/cydxf/Q-Doc.
Beyond Cosine Similarity Magnitude-Aware CLIP for No-Reference Image Quality Assessment
Nov 13, 2025Recent efforts have repurposed the Contrastive Language-Image Pre-training (CLIP) model for No-Reference Image Quality Assessment (NR-IQA) by measuring the cosine similarity between the image embedding and textual prompts such as "a good photo" or "a bad photo." However, this semantic similarity overlooks a critical yet underexplored cue: the magnitude of the CLIP image features, which we empirically find to exhibit a strong correlation with perceptual quality. In this work, we introduce a novel adaptive fusion framework that complements cosine similarity with a magnitude-aware quality cue. Specifically, we first extract the absolute CLIP image features and apply a Box-Cox transformation to statistically normalize the feature distribution and mitigate semantic sensitivity. The resulting scalar summary serves as a semantically-normalized auxiliary cue that complements cosine-based prompt matching. To integrate both cues effectively, we further design a confidence-guided fusion scheme that adaptively weighs each term according to its relative strength. Extensive experiments on multiple benchmark IQA datasets demonstrate that our method consistently outperforms standard CLIP-based IQA and state-of-the-art baselines, without any task-specific training.
VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models: Methods and Results
Sep 11, 2025
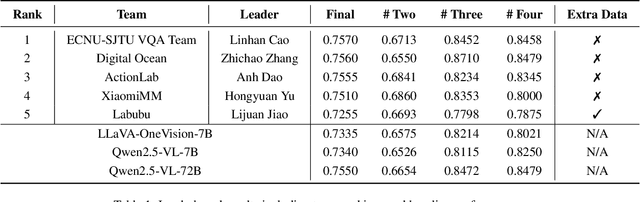
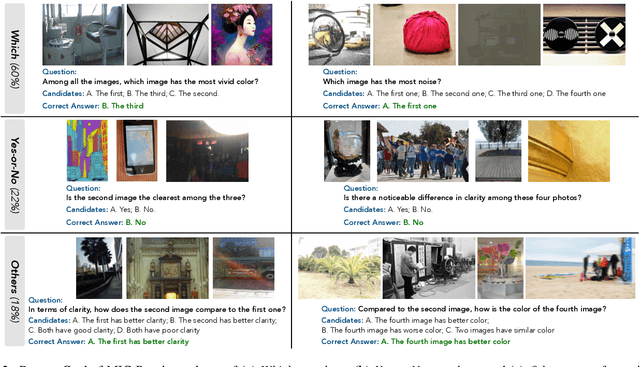
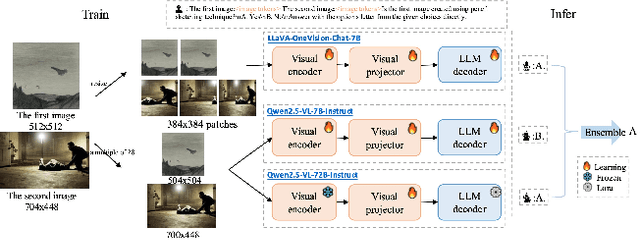
This paper presents a summary of the VQualA 2025 Challenge on Visual Quality Comparison for Large Multimodal Models (LMMs), hosted as part of the ICCV 2025 Workshop on Visual Quality Assessment. The challenge aims to evaluate and enhance the ability of state-of-the-art LMMs to perform open-ended and detailed reasoning about visual quality differences across multiple images. To this end, the competition introduces a novel benchmark comprising thousands of coarse-to-fine grained visual quality comparison tasks, spanning single images, pairs, and multi-image groups. Each task requires models to provide accurate quality judgments. The competition emphasizes holistic evaluation protocols, including 2AFC-based binary preference and multi-choice questions (MCQs). Around 100 participants submitted entries, with five models demonstrating the emerging capabilities of instruction-tuned LMMs on quality assessment. This challenge marks a significant step toward open-domain visual quality reasoning and comparison and serves as a catalyst for future research on interpretable and human-aligned quality evaluation systems.
Compressing Human Body Video with Interactive Semantics: A Generative Approach
May 22, 2025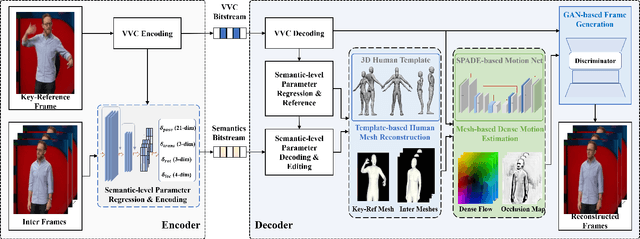
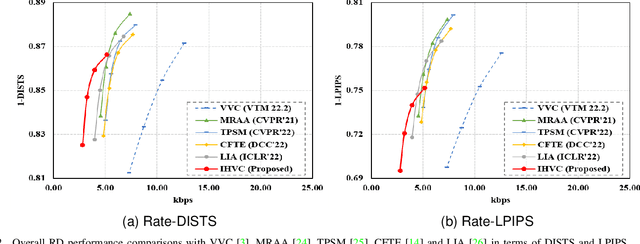


In this paper, we propose to compress human body video with interactive semantics, which can facilitate video coding to be interactive and controllable by manipulating semantic-level representations embedded in the coded bitstream. In particular, the proposed encoder employs a 3D human model to disentangle nonlinear dynamics and complex motion of human body signal into a series of configurable embeddings, which are controllably edited, compactly compressed, and efficiently transmitted. Moreover, the proposed decoder can evolve the mesh-based motion fields from these decoded semantics to realize the high-quality human body video reconstruction. Experimental results illustrate that the proposed framework can achieve promising compression performance for human body videos at ultra-low bitrate ranges compared with the state-of-the-art video coding standard Versatile Video Coding (VVC) and the latest generative compression schemes. Furthermore, the proposed framework enables interactive human body video coding without any additional pre-/post-manipulation processes, which is expected to shed light on metaverse-related digital human communication in the future.
Pleno-Generation: A Scalable Generative Face Video Compression Framework with Bandwidth Intelligence
Feb 24, 2025



Generative model based compact video compression is typically operated within a relative narrow range of bitrates, and often with an emphasis on ultra-low rate applications. There has been an increasing consensus in the video communication industry that full bitrate coverage should be enabled by generative coding. However, this is an extremely difficult task, largely because generation and compression, although related, have distinct goals and trade-offs. The proposed Pleno-Generation (PGen) framework distinguishes itself through its exceptional capabilities in ensuring the robustness of video coding by utilizing a wider range of bandwidth for generation via bandwidth intelligence. In particular, we initiate our research of PGen with face video coding, and PGen offers a paradigm shift that prioritizes high-fidelity reconstruction over pursuing compact bitstream. The novel PGen framework leverages scalable representation and layered reconstruction for Generative Face Video Compression (GFVC), in an attempt to imbue the bitstream with intelligence in different granularity. Experimental results illustrate that the proposed PGen framework can facilitate existing GFVC algorithms to better deliver high-fidelity and faithful face videos. In addition, the proposed framework can allow a greater space of flexibility for coding applications and show superior RD performance with a much wider bitrate range in terms of various quality evaluations. Moreover, in comparison with the latest Versatile Video Coding (VVC) codec, the proposed scheme achieves competitive Bj{\o}ntegaard-delta-rate savings for perceptual-level evaluations.