 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEduVQA: Benchmarking AI-Generated Video Quality Assessment for Education
Mar 03, 2026While AI-generated content (AIGC) models have achieved remarkable success in generating photorealistic videos, their potential to support visual, story-driven learning in education remains largely untapped. To close this gap, we present EduAIGV-1k, the first benchmark dataset and evaluation framework dedicated to assessing the quality of AI-generated videos (AIGVs) designed to teach foundational math concepts, such as numbers and geometry, to young learners. EduAIGV-1k contains 1,130 short videos produced by ten state-of-the-art text-to-video (T2V) models using 113 pedagogy-oriented prompts. Each video is accompanied by rich, fine-grained annotations along two complementary axes: (1) Perceptual quality, disentangled into spatial and temporal fidelity, and (2) Prompt alignment, labeled at the word-level and sentence-level to quantify the degree to which each mathematical concept in the prompt is accurately grounded in the generated video. These fine-grained annotations transform each video into a multi-dimensional, interpretable supervision signal, far beyond a single quality score. Leveraging this dense feedback, we introduce EduVQA for both perceptual and alignment quality assessment of AIGVs. In particular, we propose a Structured 2D Mixture-of-Experts (S2D-MoE) module, which enhances the dependency between overall quality and each sub-dimension by shared experts and dynamic 2D gating matrix. Extensive experiments show our EduVQA consistently outperforms existing VQA baselines. Both our dataset and code will be publicly available.
Mitigating Perception Bias: A Training-Free Approach to Enhance LMM for Image Quality Assessment
Nov 19, 2024



Despite the impressive performance of large multimodal models (LMMs) in high-level visual tasks, their capacity for image quality assessment (IQA) remains limited. One main reason is that LMMs are primarily trained for high-level tasks (e.g., image captioning), emphasizing unified image semantics extraction under varied quality. Such semantic-aware yet quality-insensitive perception bias inevitably leads to a heavy reliance on image semantics when those LMMs are forced for quality rating. In this paper, instead of retraining or tuning an LMM costly, we propose a training-free debiasing framework, in which the image quality prediction is rectified by mitigating the bias caused by image semantics. Specifically, we first explore several semantic-preserving distortions that can significantly degrade image quality while maintaining identifiable semantics. By applying these specific distortions to the query or test images, we ensure that the degraded images are recognized as poor quality while their semantics remain. During quality inference, both a query image and its corresponding degraded version are fed to the LMM along with a prompt indicating that the query image quality should be inferred under the condition that the degraded one is deemed poor quality.This prior condition effectively aligns the LMM's quality perception, as all degraded images are consistently rated as poor quality, regardless of their semantic difference.Finally, the quality scores of the query image inferred under different prior conditions (degraded versions) are aggregated using a conditional probability model. Extensive experiments on various IQA datasets show that our debiasing framework could consistently enhance the LMM performance and the code will be publicly available.
2AFC Prompting of Large Multimodal Models for Image Quality Assessment
Feb 02, 2024



While abundant research has been conducted on improving high-level visual understanding and reasoning capabilities of large multimodal models~(LMMs), their visual quality assessment~(IQA) ability has been relatively under-explored. Here we take initial steps towards this goal by employing the two-alternative forced choice~(2AFC) prompting, as 2AFC is widely regarded as the most reliable way of collecting human opinions of visual quality. Subsequently, the global quality score of each image estimated by a particular LMM can be efficiently aggregated using the maximum a posterior estimation. Meanwhile, we introduce three evaluation criteria: consistency, accuracy, and correlation, to provide comprehensive quantifications and deeper insights into the IQA capability of five LMMs. Extensive experiments show that existing LMMs exhibit remarkable IQA ability on coarse-grained quality comparison, but there is room for improvement on fine-grained quality discrimination. The proposed dataset sheds light on the future development of IQA models based on LMMs. The codes will be made publicly available at https://github.com/h4nwei/2AFC-LMMs.
Perceptual Quality Assessment of 360$^\circ$ Images Based on Generative Scanpath Representation
Sep 07, 2023



Despite substantial efforts dedicated to the design of heuristic models for omnidirectional (i.e., 360$^\circ$) image quality assessment (OIQA), a conspicuous gap remains due to the lack of consideration for the diversity of viewing behaviors that leads to the varying perceptual quality of 360$^\circ$ images. Two critical aspects underline this oversight: the neglect of viewing conditions that significantly sway user gaze patterns and the overreliance on a single viewport sequence from the 360$^\circ$ image for quality inference. To address these issues, we introduce a unique generative scanpath representation (GSR) for effective quality inference of 360$^\circ$ images, which aggregates varied perceptual experiences of multi-hypothesis users under a predefined viewing condition. More specifically, given a viewing condition characterized by the starting point of viewing and exploration time, a set of scanpaths consisting of dynamic visual fixations can be produced using an apt scanpath generator. Following this vein, we use the scanpaths to convert the 360$^\circ$ image into the unique GSR, which provides a global overview of gazed-focused contents derived from scanpaths. As such, the quality inference of the 360$^\circ$ image is swiftly transformed to that of GSR. We then propose an efficient OIQA computational framework by learning the quality maps of GSR. Comprehensive experimental results validate that the predictions of the proposed framework are highly consistent with human perception in the spatiotemporal domain, especially in the challenging context of locally distorted 360$^\circ$ images under varied viewing conditions. The code will be released at https://github.com/xiangjieSui/GSR
A Database for Perceived Quality Assessment of User-Generated VR Videos
Jun 13, 2022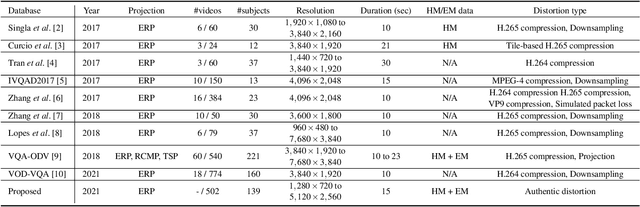

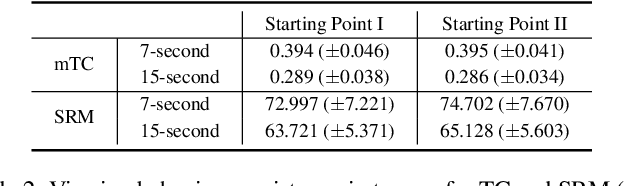
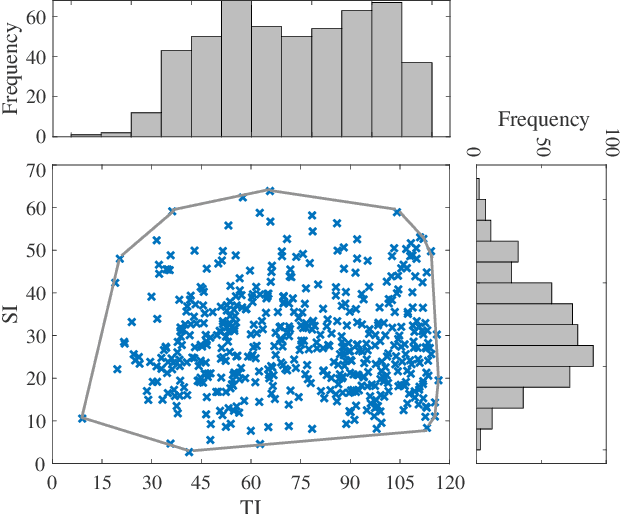
Virtual reality (VR) videos (typically in the form of 360$^\circ$ videos) have gained increasing attention due to the fast development of VR technologies and the remarkable popularization of consumer-grade 360$^\circ$ cameras and displays. Thus it is pivotal to understand how people perceive user-generated VR videos, which may suffer from commingled authentic distortions, often localized in space and time. In this paper, we establish one of the largest 360$^\circ$ video databases, containing 502 user-generated videos with rich content and distortion diversities. We capture viewing behaviors (i.e., scanpaths) of 139 users, and collect their opinion scores of perceived quality under four different viewing conditions (two starting points $\times$ two exploration times). We provide a thorough statistical analysis of recorded data, resulting in several interesting observations, such as the significant impact of viewing conditions on viewing behaviors and perceived quality. Besides, we explore other usage of our data and analysis, including evaluation of computational models for quality assessment and saliency detection of 360$^\circ$ videos. We have made the dataset and code available at https://github.com/Yao-Yiru/VR-Video-Database.
Omnidirectional Images as Moving Camera Videos
May 21, 2020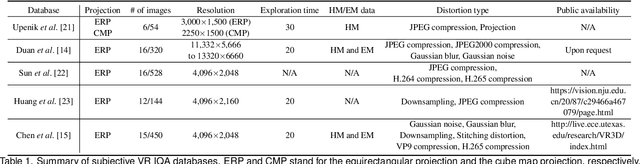


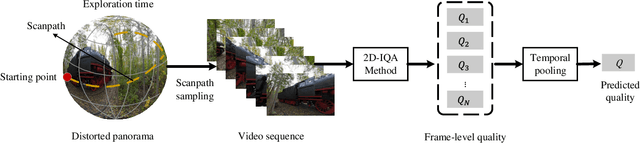
Omnidirectional images (also referred to as static 360{\deg} panoramas) impose viewing conditions much different from those of regular 2D images. A natural question arises: how do humans perceive image distortions in immersive virtual reality (VR) environments? We argue that, apart from the distorted panorama itself, three types of viewing behavior governed by VR conditions are crucial in determining its perceived quality: starting point, exploration time, and scanpath. In this paper, we propose a principled computational framework for objective quality assessment of 360{\deg} images, which embodies the threefold behavior in a delightful way. Specifically, we first transform an omnidirectional image to several video representations using viewing behavior of different users. We then leverage the recent advances in full-reference 2D image/video quality assessment to compute the perceived quality of the panorama. We construct a set of specific quality measures within the proposed framework, and demonstrate their promises on two VR quality databases.