 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Global to Granular: Revealing IQA Model Performance via Correlation Surface
Jan 29, 2026Evaluation of Image Quality Assessment (IQA) models has long been dominated by global correlation metrics, such as Pearson Linear Correlation Coefficient (PLCC) and Spearman Rank-Order Correlation Coefficient (SRCC). While widely adopted, these metrics reduce performance to a single scalar, failing to capture how ranking consistency varies across the local quality spectrum. For example, two IQA models may achieve identical SRCC values, yet one ranks high-quality images (related to high Mean Opinion Score, MOS) more reliably, while the other better discriminates image pairs with small quality/MOS differences (related to $|Δ$MOS$|$). Such complementary behaviors are invisible under global metrics. Moreover, SRCC and PLCC are sensitive to test-sample quality distributions, yielding unstable comparisons across test sets. To address these limitations, we propose \textbf{Granularity-Modulated Correlation (GMC)}, which provides a structured, fine-grained analysis of IQA performance. GMC includes: (1) a \textbf{Granularity Modulator} that applies Gaussian-weighted correlations conditioned on absolute MOS values and pairwise MOS differences ($|Δ$MOS$|$) to examine local performance variations, and (2) a \textbf{Distribution Regulator} that regularizes correlations to mitigate biases from non-uniform quality distributions. The resulting \textbf{correlation surface} maps correlation values as a joint function of MOS and $|Δ$MOS$|$, providing a 3D representation of IQA performance. Experiments on standard benchmarks show that GMC reveals performance characteristics invisible to scalar metrics, offering a more informative and reliable paradigm for analyzing, comparing, and deploying IQA models. Codes are available at https://github.com/Dniaaa/GMC.
Plug In, Grade Right: Psychology-Inspired AGIQA
Dec 28, 2025Existing AGIQA models typically estimate image quality by measuring and aggregating the similarities between image embeddings and text embeddings derived from multi-grade quality descriptions. Although effective, we observe that such similarity distributions across grades usually exhibit multimodal patterns. For instance, an image embedding may show high similarity to both "excellent" and "poor" grade descriptions while deviating from the "good" one. We refer to this phenomenon as "semantic drift", where semantic inconsistencies between text embeddings and their intended descriptions undermine the reliability of text-image shared-space learning. To mitigate this issue, we draw inspiration from psychometrics and propose an improved Graded Response Model (GRM) for AGIQA. The GRM is a classical assessment model that categorizes a subject's ability across grades using test items with various difficulty levels. This paradigm aligns remarkably well with human quality rating, where image quality can be interpreted as an image's ability to meet various quality grades. Building on this philosophy, we design a two-branch quality grading module: one branch estimates image ability while the other constructs multiple difficulty levels. To ensure monotonicity in difficulty levels, we further model difficulty generation in an arithmetic manner, which inherently enforces a unimodal and interpretable quality distribution. Our Arithmetic GRM based Quality Grading (AGQG) module enjoys a plug-and-play advantage, consistently improving performance when integrated into various state-of-the-art AGIQA frameworks. Moreover, it also generalizes effectively to both natural and screen content image quality assessment, revealing its potential as a key component in future IQA models.
Simple Lines, Big Ideas: Towards Interpretable Assessment of Human Creativity from Drawings
Nov 17, 2025Assessing human creativity through visual outputs, such as drawings, plays a critical role in fields including psychology, education, and cognitive science. However, current assessment practices still rely heavily on expert-based subjective scoring, which is both labor-intensive and inherently subjective. In this paper, we propose a data-driven framework for automatic and interpretable creativity assessment from drawings. Motivated by the cognitive understanding that creativity can emerge from both what is drawn (content) and how it is drawn (style), we reinterpret the creativity score as a function of these two complementary dimensions.Specifically, we first augment an existing creativity labeled dataset with additional annotations targeting content categories. Based on the enriched dataset, we further propose a multi-modal, multi-task learning framework that simultaneously predicts creativity scores, categorizes content types, and extracts stylistic features. In particular, we introduce a conditional learning mechanism that enables the model to adapt its visual feature extraction by dynamically tuning it to creativity-relevant signals conditioned on the drawing's stylistic and semantic cues.Experimental results demonstrate that our model achieves state-of-the-art performance compared to existing regression-based approaches and offers interpretable visualizations that align well with human judgments. The code and annotations will be made publicly available at https://github.com/WonderOfU9/CSCA_PRCV_2025
Q-Doc: Benchmarking Document Image Quality Assessment Capabilities in Multi-modal Large Language Models
Nov 14, 2025The rapid advancement of Multi-modal Large Language Models (MLLMs) has expanded their capabilities beyond high-level vision tasks. Nevertheless, their potential for Document Image Quality Assessment (DIQA) remains underexplored. To bridge this gap, we propose Q-Doc, a three-tiered evaluation framework for systematically probing DIQA capabilities of MLLMs at coarse, middle, and fine granularity levels. a) At the coarse level, we instruct MLLMs to assign quality scores to document images and analyze their correlation with Quality Annotations. b) At the middle level, we design distortion-type identification tasks, including single-choice and multi-choice tests for multi-distortion scenarios. c) At the fine level, we introduce distortion-severity assessment where MLLMs classify distortion intensity against human-annotated references. Our evaluation demonstrates that while MLLMs possess nascent DIQA abilities, they exhibit critical limitations: inconsistent scoring, distortion misidentification, and severity misjudgment. Significantly, we show that Chain-of-Thought (CoT) prompting substantially enhances performance across all levels. Our work provides a benchmark for DIQA capabilities in MLLMs, revealing pronounced deficiencies in their quality perception and promising pathways for enhancement. The benchmark and code are publicly available at: https://github.com/cydxf/Q-Doc.
Beyond Cosine Similarity Magnitude-Aware CLIP for No-Reference Image Quality Assessment
Nov 13, 2025Recent efforts have repurposed the Contrastive Language-Image Pre-training (CLIP) model for No-Reference Image Quality Assessment (NR-IQA) by measuring the cosine similarity between the image embedding and textual prompts such as "a good photo" or "a bad photo." However, this semantic similarity overlooks a critical yet underexplored cue: the magnitude of the CLIP image features, which we empirically find to exhibit a strong correlation with perceptual quality. In this work, we introduce a novel adaptive fusion framework that complements cosine similarity with a magnitude-aware quality cue. Specifically, we first extract the absolute CLIP image features and apply a Box-Cox transformation to statistically normalize the feature distribution and mitigate semantic sensitivity. The resulting scalar summary serves as a semantically-normalized auxiliary cue that complements cosine-based prompt matching. To integrate both cues effectively, we further design a confidence-guided fusion scheme that adaptively weighs each term according to its relative strength. Extensive experiments on multiple benchmark IQA datasets demonstrate that our method consistently outperforms standard CLIP-based IQA and state-of-the-art baselines, without any task-specific training.
Disentangling Bias by Modeling Intra- and Inter-modal Causal Attention for Multimodal Sentiment Analysis
Aug 07, 2025
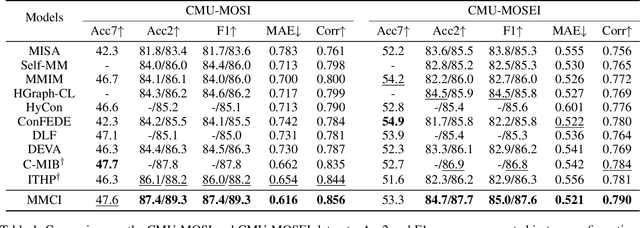
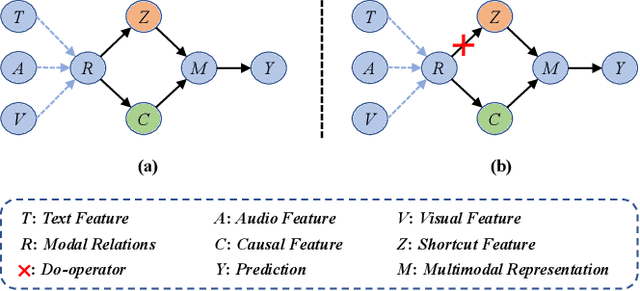
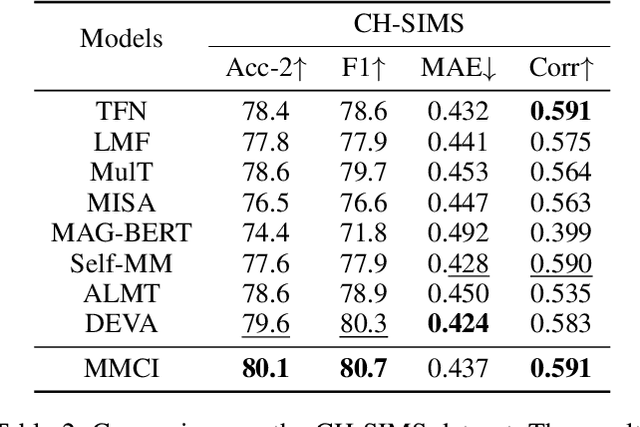
Multimodal sentiment analysis (MSA) aims to understand human emotions by integrating information from multiple modalities, such as text, audio, and visual data. However, existing methods often suffer from spurious correlations both within and across modalities, leading models to rely on statistical shortcuts rather than true causal relationships, thereby undermining generalization. To mitigate this issue, we propose a Multi-relational Multimodal Causal Intervention (MMCI) model, which leverages the backdoor adjustment from causal theory to address the confounding effects of such shortcuts. Specifically, we first model the multimodal inputs as a multi-relational graph to explicitly capture intra- and inter-modal dependencies. Then, we apply an attention mechanism to separately estimate and disentangle the causal features and shortcut features corresponding to these intra- and inter-modal relations. Finally, by applying the backdoor adjustment, we stratify the shortcut features and dynamically combine them with the causal features to encourage MMCI to produce stable predictions under distribution shifts. Extensive experiments on several standard MSA datasets and out-of-distribution (OOD) test sets demonstrate that our method effectively suppresses biases and improves performance.
AI-generated Image Quality Assessment in Visual Communication
Dec 20, 2024



Assessing the quality of artificial intelligence-generated images (AIGIs) plays a crucial role in their application in real-world scenarios. However, traditional image quality assessment (IQA) algorithms primarily focus on low-level visual perception, while existing IQA works on AIGIs overemphasize the generated content itself, neglecting its effectiveness in real-world applications. To bridge this gap, we propose AIGI-VC, a quality assessment database for AI-Generated Images in Visual Communication, which studies the communicability of AIGIs in the advertising field from the perspectives of information clarity and emotional interaction. The dataset consists of 2,500 images spanning 14 advertisement topics and 8 emotion types. It provides coarse-grained human preference annotations and fine-grained preference descriptions, benchmarking the abilities of IQA methods in preference prediction, interpretation, and reasoning. We conduct an empirical study of existing representative IQA methods and large multi-modal models on the AIGI-VC dataset, uncovering their strengths and weaknesses.
Mitigating Perception Bias: A Training-Free Approach to Enhance LMM for Image Quality Assessment
Nov 19, 2024Despite the impressive performance of large multimodal models (LMMs) in high-level visual tasks, their capacity for image quality assessment (IQA) remains limited. One main reason is that LMMs are primarily trained for high-level tasks (e.g., image captioning), emphasizing unified image semantics extraction under varied quality. Such semantic-aware yet quality-insensitive perception bias inevitably leads to a heavy reliance on image semantics when those LMMs are forced for quality rating. In this paper, instead of retraining or tuning an LMM costly, we propose a training-free debiasing framework, in which the image quality prediction is rectified by mitigating the bias caused by image semantics. Specifically, we first explore several semantic-preserving distortions that can significantly degrade image quality while maintaining identifiable semantics. By applying these specific distortions to the query or test images, we ensure that the degraded images are recognized as poor quality while their semantics remain. During quality inference, both a query image and its corresponding degraded version are fed to the LMM along with a prompt indicating that the query image quality should be inferred under the condition that the degraded one is deemed poor quality.This prior condition effectively aligns the LMM's quality perception, as all degraded images are consistently rated as poor quality, regardless of their semantic difference.Finally, the quality scores of the query image inferred under different prior conditions (degraded versions) are aggregated using a conditional probability model. Extensive experiments on various IQA datasets show that our debiasing framework could consistently enhance the LMM performance and the code will be publicly available.
RCNet: Deep Recurrent Collaborative Network for Multi-View Low-Light Image Enhancement
Sep 06, 2024

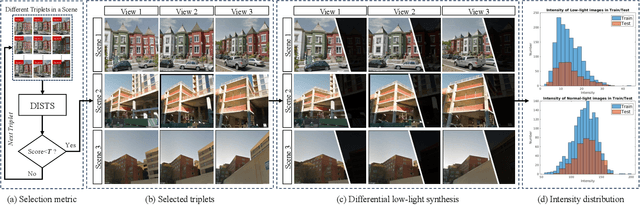
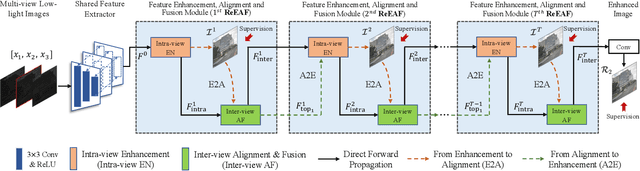
Scene observation from multiple perspectives would bring a more comprehensive visual experience. However, in the context of acquiring multiple views in the dark, the highly correlated views are seriously alienated, making it challenging to improve scene understanding with auxiliary views. Recent single image-based enhancement methods may not be able to provide consistently desirable restoration performance for all views due to the ignorance of potential feature correspondence among different views. To alleviate this issue, we make the first attempt to investigate multi-view low-light image enhancement. First, we construct a new dataset called Multi-View Low-light Triplets (MVLT), including 1,860 pairs of triple images with large illumination ranges and wide noise distribution. Each triplet is equipped with three different viewpoints towards the same scene. Second, we propose a deep multi-view enhancement framework based on the Recurrent Collaborative Network (RCNet). Specifically, in order to benefit from similar texture correspondence across different views, we design the recurrent feature enhancement, alignment and fusion (ReEAF) module, in which intra-view feature enhancement (Intra-view EN) followed by inter-view feature alignment and fusion (Inter-view AF) is performed to model the intra-view and inter-view feature propagation sequentially via multi-view collaboration. In addition, two different modules from enhancement to alignment (E2A) and from alignment to enhancement (A2E) are developed to enable the interactions between Intra-view EN and Inter-view AF, which explicitly utilize attentive feature weighting and sampling for enhancement and alignment, respectively. Experimental results demonstrate that our RCNet significantly outperforms other state-of-the-art methods. All of our dataset, code, and model will be available at https://github.com/hluo29/RCNet.
Unrolled Decomposed Unpaired Learning for Controllable Low-Light Video Enhancement
Aug 22, 2024



Obtaining pairs of low/normal-light videos, with motions, is more challenging than still images, which raises technical issues and poses the technical route of unpaired learning as a critical role. This paper makes endeavors in the direction of learning for low-light video enhancement without using paired ground truth. Compared to low-light image enhancement, enhancing low-light videos is more difficult due to the intertwined effects of noise, exposure, and contrast in the spatial domain, jointly with the need for temporal coherence. To address the above challenge, we propose the Unrolled Decomposed Unpaired Network (UDU-Net) for enhancing low-light videos by unrolling the optimization functions into a deep network to decompose the signal into spatial and temporal-related factors, which are updated iteratively. Firstly, we formulate low-light video enhancement as a Maximum A Posteriori estimation (MAP) problem with carefully designed spatial and temporal visual regularization. Then, via unrolling the problem, the optimization of the spatial and temporal constraints can be decomposed into different steps and updated in a stage-wise manner. From the spatial perspective, the designed Intra subnet leverages unpair prior information from expert photography retouched skills to adjust the statistical distribution. Additionally, we introduce a novel mechanism that integrates human perception feedback to guide network optimization, suppressing over/under-exposure conditions. Meanwhile, to address the issue from the temporal perspective, the designed Inter subnet fully exploits temporal cues in progressive optimization, which helps achieve improved temporal consistency in enhancement results. Consequently, the proposed method achieves superior performance to state-of-the-art methods in video illumination, noise suppression, and temporal consistency across outdoor and indoor scenes.