 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLV-Edit: Towards Consistent and Highly Efficient Editing for Minute-Level Videos
Feb 02, 2026We propose MLV-Edit, a training-free, flow-based framework that address the unique challenges of minute-level video editing. While existing techniques excel in short-form video manipulation, scaling them to long-duration videos remains challenging due to prohibitive computational overhead and the difficulty of maintaining global temporal consistency across thousands of frames. To address this, MLV-Edit employs a divide-and-conquer strategy for segment-wise editing, facilitated by two core modules: Velocity Blend rectifies motion inconsistencies at segment boundaries by aligning the flow fields of adjacent chunks, eliminating flickering and boundary artifacts commonly observed in fragmented video processing; and Attention Sink anchors local segment features to global reference frames, effectively suppressing cumulative structural drift. Extensive quantitative and qualitative experiments demonstrate that MLV-Edit consistently outperforms state-of-the-art methods in terms of temporal stability and semantic fidelity.
IC-Effect: Precise and Efficient Video Effects Editing via In-Context Learning
Dec 17, 2025

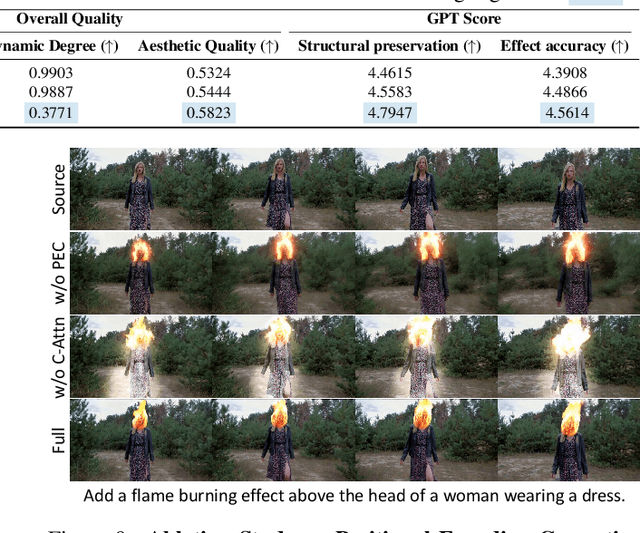

We propose \textbf{IC-Effect}, an instruction-guided, DiT-based framework for few-shot video VFX editing that synthesizes complex effects (\eg flames, particles and cartoon characters) while strictly preserving spatial and temporal consistency. Video VFX editing is highly challenging because injected effects must blend seamlessly with the background, the background must remain entirely unchanged, and effect patterns must be learned efficiently from limited paired data. However, existing video editing models fail to satisfy these requirements. IC-Effect leverages the source video as clean contextual conditions, exploiting the contextual learning capability of DiT models to achieve precise background preservation and natural effect injection. A two-stage training strategy, consisting of general editing adaptation followed by effect-specific learning via Effect-LoRA, ensures strong instruction following and robust effect modeling. To further improve efficiency, we introduce spatiotemporal sparse tokenization, enabling high fidelity with substantially reduced computation. We also release a paired VFX editing dataset spanning $15$ high-quality visual styles. Extensive experiments show that IC-Effect delivers high-quality, controllable, and temporally consistent VFX editing, opening new possibilities for video creation.
UniMIC: Token-Based Multimodal Interactive Coding for Human-AI Collaboration
Sep 26, 2025



The rapid progress of Large Multimodal Models (LMMs) and cloud-based AI agents is transforming human-AI collaboration into bidirectional, multimodal interaction. However, existing codecs remain optimized for unimodal, one-way communication, resulting in repeated degradation under conventional compress-transmit-reconstruct pipelines. To address this limitation, we propose UniMIC, a Unified token-based Multimodal Interactive Coding framework that bridges edge devices and cloud AI agents. Instead of transmitting raw pixels or plain text, UniMIC employs compact tokenized representations as the communication medium, enabling efficient low-bitrate transmission while maintaining compatibility with LMMs. To further enhance compression, lightweight Transformer-based entropy models with scenario-specific designs-generic, masked, and text-conditioned-effectively minimize inter-token redundancy. Extensive experiments on text-to-image generation, text-guided inpainting, outpainting, and visual question answering show that UniMIC achieves substantial bitrate savings and remains robust even at ultra-low bitrates (<0.05bpp), without compromising downstream task performance. These results establish UniMIC as a practical and forward-looking paradigm for next-generation multimodal interactive communication.
Tuning-Free Image Editing with Fidelity and Editability via Unified Latent Diffusion Model
Apr 08, 2025Balancing fidelity and editability is essential in text-based image editing (TIE), where failures commonly lead to over- or under-editing issues. Existing methods typically rely on attention injections for structure preservation and leverage the inherent text alignment capabilities of pre-trained text-to-image (T2I) models for editability, but they lack explicit and unified mechanisms to properly balance these two objectives. In this work, we introduce UnifyEdit, a tuning-free method that performs diffusion latent optimization to enable a balanced integration of fidelity and editability within a unified framework. Unlike direct attention injections, we develop two attention-based constraints: a self-attention (SA) preservation constraint for structural fidelity, and a cross-attention (CA) alignment constraint to enhance text alignment for improved editability. However, simultaneously applying both constraints can lead to gradient conflicts, where the dominance of one constraint results in over- or under-editing. To address this challenge, we introduce an adaptive time-step scheduler that dynamically adjusts the influence of these constraints, guiding the diffusion latent toward an optimal balance. Extensive quantitative and qualitative experiments validate the effectiveness of our approach, demonstrating its superiority in achieving a robust balance between structure preservation and text alignment across various editing tasks, outperforming other state-of-the-art methods. The source code will be available at https://github.com/CUC-MIPG/UnifyEdit.
Edit Transfer: Learning Image Editing via Vision In-Context Relations
Mar 17, 2025We introduce a new setting, Edit Transfer, where a model learns a transformation from just a single source-target example and applies it to a new query image. While text-based methods excel at semantic manipulations through textual prompts, they often struggle with precise geometric details (e.g., poses and viewpoint changes). Reference-based editing, on the other hand, typically focuses on style or appearance and fails at non-rigid transformations. By explicitly learning the editing transformation from a source-target pair, Edit Transfer mitigates the limitations of both text-only and appearance-centric references. Drawing inspiration from in-context learning in large language models, we propose a visual relation in-context learning paradigm, building upon a DiT-based text-to-image model. We arrange the edited example and the query image into a unified four-panel composite, then apply lightweight LoRA fine-tuning to capture complex spatial transformations from minimal examples. Despite using only 42 training samples, Edit Transfer substantially outperforms state-of-the-art TIE and RIE methods on diverse non-rigid scenarios, demonstrating the effectiveness of few-shot visual relation learning.
EmoAgent: Multi-Agent Collaboration of Plan, Edit, and Critic, for Affective Image Manipulation
Mar 14, 2025



Affective Image Manipulation (AIM) aims to alter an image's emotional impact by adjusting multiple visual elements to evoke specific feelings.Effective AIM is inherently complex, necessitating a collaborative approach that involves identifying semantic cues within source images, manipulating these elements to elicit desired emotional responses, and verifying that the combined adjustments successfully evoke the target emotion.To address these challenges, we introduce EmoAgent, the first multi-agent collaboration framework for AIM. By emulating the cognitive behaviors of a human painter, EmoAgent incorporates three specialized agents responsible for planning, editing, and critical evaluation. Furthermore, we develop an emotion-factor knowledge retriever, a decision-making tree space, and a tool library to enhance EmoAgent's effectiveness in handling AIM. Experiments demonstrate that the proposed multi-agent framework outperforms existing methods, offering more reasonable and effective emotional expression.
Stable Diffusion is a Natural Cross-Modal Decoder for Layered AI-generated Image Compression
Dec 17, 2024



Recent advances in Artificial Intelligence Generated Content (AIGC) have garnered significant interest, accompanied by an increasing need to transmit and compress the vast number of AI-generated images (AIGIs). However, there is a noticeable deficiency in research focused on compression methods for AIGIs. To address this critical gap, we introduce a scalable cross-modal compression framework that incorporates multiple human-comprehensible modalities, designed to efficiently capture and relay essential visual information for AIGIs. In particular, our framework encodes images into a layered bitstream consisting of a semantic layer that delivers high-level semantic information through text prompts; a structural layer that captures spatial details using edge or skeleton maps; and a texture layer that preserves local textures via a colormap. Utilizing Stable Diffusion as the backend, the framework effectively leverages these multimodal priors for image generation, effectively functioning as a decoder when these priors are encoded. Qualitative and quantitative results show that our method proficiently restores both semantic and visual details, competing against baseline approaches at extremely low bitrates ( <0.02 bpp). Additionally, our framework facilitates downstream editing applications without requiring full decoding, thereby paving a new direction for future research in AIGI compression.
Mirror contrastive loss based sliding window transformer for subject-independent motor imagery based EEG signal recognition
Aug 29, 2024



While deep learning models have been extensively utilized in motor imagery based EEG signal recognition, they often operate as black boxes. Motivated by neurological findings indicating that the mental imagery of left or right-hand movement induces event-related desynchronization (ERD) in the contralateral sensorimotor area of the brain, we propose a Mirror Contrastive Loss based Sliding Window Transformer (MCL-SWT) to enhance subject-independent motor imagery-based EEG signal recognition. Specifically, our proposed mirror contrastive loss enhances sensitivity to the spatial location of ERD by contrasting the original EEG signals with their mirror counterparts-mirror EEG signals generated by interchanging the channels of the left and right hemispheres of the EEG signals. Moreover, we introduce a temporal sliding window transformer that computes self-attention scores from high temporal resolution features, thereby improving model performance with manageable computational complexity. We evaluate the performance of MCL-SWT on subject-independent motor imagery EEG signal recognition tasks, and our experimental results demonstrate that MCL-SWT achieved accuracies of 66.48% and 75.62%, surpassing the state-of-the-art (SOTA) model by 2.82% and 2.17%, respectively. Furthermore, ablation experiments confirm the effectiveness of the proposed mirror contrastive loss. A code demo of MCL-SWT is available at https://github.com/roniusLuo/MCL_SWT.
Unrolled Decomposed Unpaired Learning for Controllable Low-Light Video Enhancement
Aug 22, 2024



Obtaining pairs of low/normal-light videos, with motions, is more challenging than still images, which raises technical issues and poses the technical route of unpaired learning as a critical role. This paper makes endeavors in the direction of learning for low-light video enhancement without using paired ground truth. Compared to low-light image enhancement, enhancing low-light videos is more difficult due to the intertwined effects of noise, exposure, and contrast in the spatial domain, jointly with the need for temporal coherence. To address the above challenge, we propose the Unrolled Decomposed Unpaired Network (UDU-Net) for enhancing low-light videos by unrolling the optimization functions into a deep network to decompose the signal into spatial and temporal-related factors, which are updated iteratively. Firstly, we formulate low-light video enhancement as a Maximum A Posteriori estimation (MAP) problem with carefully designed spatial and temporal visual regularization. Then, via unrolling the problem, the optimization of the spatial and temporal constraints can be decomposed into different steps and updated in a stage-wise manner. From the spatial perspective, the designed Intra subnet leverages unpair prior information from expert photography retouched skills to adjust the statistical distribution. Additionally, we introduce a novel mechanism that integrates human perception feedback to guide network optimization, suppressing over/under-exposure conditions. Meanwhile, to address the issue from the temporal perspective, the designed Inter subnet fully exploits temporal cues in progressive optimization, which helps achieve improved temporal consistency in enhancement results. Consequently, the proposed method achieves superior performance to state-of-the-art methods in video illumination, noise suppression, and temporal consistency across outdoor and indoor scenes.
Unifying Generation and Compression: Ultra-low bitrate Image Coding Via Multi-stage Transformer
Mar 06, 2024Recent progress in generative compression technology has significantly improved the perceptual quality of compressed data. However, these advancements primarily focus on producing high-frequency details, often overlooking the ability of generative models to capture the prior distribution of image content, thus impeding further bitrate reduction in extreme compression scenarios (<0.05 bpp). Motivated by the capabilities of predictive language models for lossless compression, this paper introduces a novel Unified Image Generation-Compression (UIGC) paradigm, merging the processes of generation and compression. A key feature of the UIGC framework is the adoption of vector-quantized (VQ) image models for tokenization, alongside a multi-stage transformer designed to exploit spatial contextual information for modeling the prior distribution. As such, the dual-purpose framework effectively utilizes the learned prior for entropy estimation and assists in the regeneration of lost tokens. Extensive experiments demonstrate the superiority of the proposed UIGC framework over existing codecs in perceptual quality and human perception, particularly in ultra-low bitrate scenarios (<=0.03 bpp), pioneering a new direction in generative compression.