 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Decoupling of Placid Terminal Attractor-based Gradient Descent Algorithm
Sep 10, 2024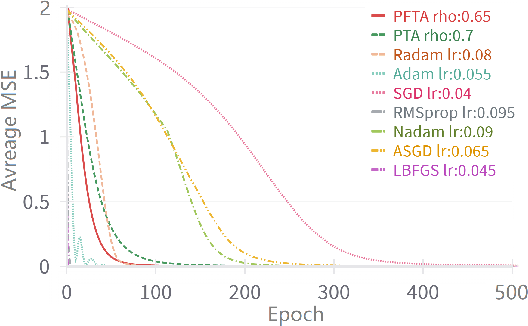
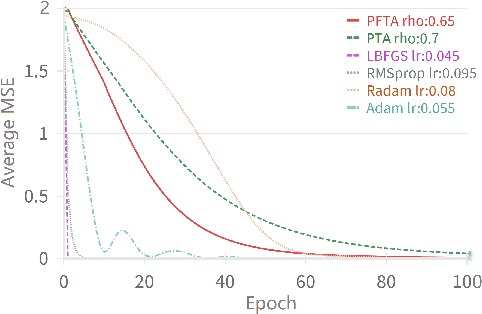
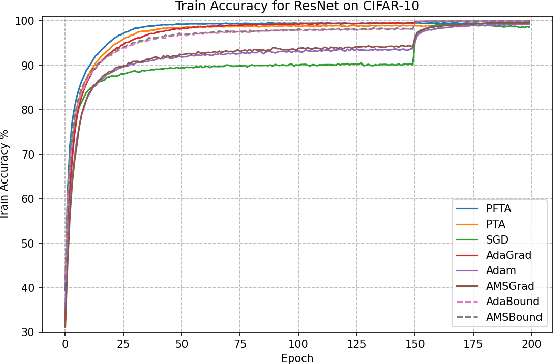
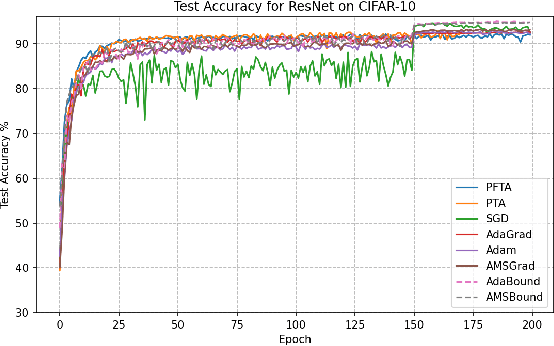
Gradient descent (GD) and stochastic gradient descent (SGD) have been widely used in a large number of application domains. Therefore, understanding the dynamics of GD and improving its convergence speed is still of great importance. This paper carefully analyzes the dynamics of GD based on the terminal attractor at different stages of its gradient flow. On the basis of the terminal sliding mode theory and the terminal attractor theory, four adaptive learning rates are designed. Their performances are investigated in light of a detailed theoretical investigation, and the running times of the learning procedures are evaluated and compared. The total times of their learning processes are also studied in detail. To evaluate their effectiveness, various simulation results are investigated on a function approximation problem and an image classification problem.
Mirror contrastive loss based sliding window transformer for subject-independent motor imagery based EEG signal recognition
Aug 29, 2024



While deep learning models have been extensively utilized in motor imagery based EEG signal recognition, they often operate as black boxes. Motivated by neurological findings indicating that the mental imagery of left or right-hand movement induces event-related desynchronization (ERD) in the contralateral sensorimotor area of the brain, we propose a Mirror Contrastive Loss based Sliding Window Transformer (MCL-SWT) to enhance subject-independent motor imagery-based EEG signal recognition. Specifically, our proposed mirror contrastive loss enhances sensitivity to the spatial location of ERD by contrasting the original EEG signals with their mirror counterparts-mirror EEG signals generated by interchanging the channels of the left and right hemispheres of the EEG signals. Moreover, we introduce a temporal sliding window transformer that computes self-attention scores from high temporal resolution features, thereby improving model performance with manageable computational complexity. We evaluate the performance of MCL-SWT on subject-independent motor imagery EEG signal recognition tasks, and our experimental results demonstrate that MCL-SWT achieved accuracies of 66.48% and 75.62%, surpassing the state-of-the-art (SOTA) model by 2.82% and 2.17%, respectively. Furthermore, ablation experiments confirm the effectiveness of the proposed mirror contrastive loss. A code demo of MCL-SWT is available at https://github.com/roniusLuo/MCL_SWT.
A game method for improving the interpretability of convolution neural network
Oct 21, 2019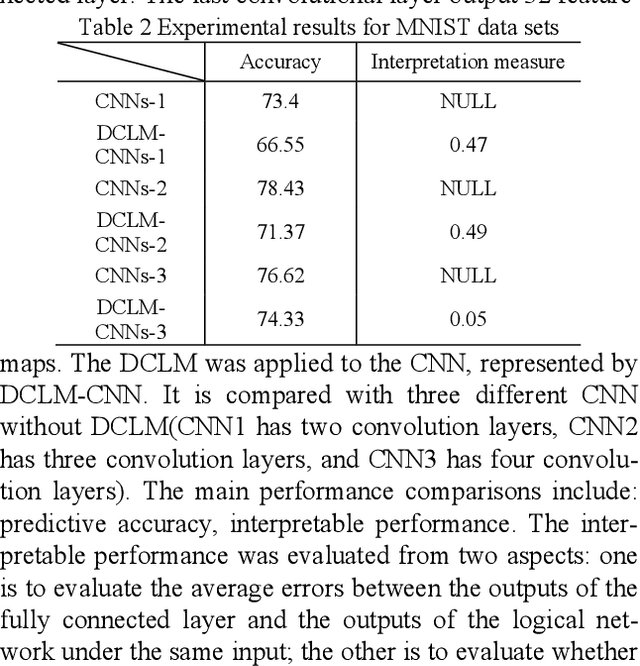
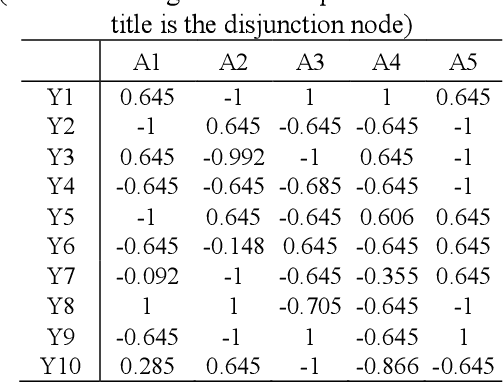
Real artificial intelligence always has been focused on by many machine learning researchers, especially in the area of deep learning. However deep neural network is hard to be understood and explained, and sometimes, even metaphysics. The reason is, we believe that: the network is essentially a perceptual model. Therefore, we believe that in order to complete complex intelligent activities from simple perception, it is necessary to con-struct another interpretable logical network to form accurate and reasonable responses and explanations to external things. Researchers like Bolei Zhou and Quanshi Zhang have found many explanatory rules for deep feature extraction aimed at the feature extraction stage of convolution neural network. However, although researchers like Marco Gori have also made great efforts to improve the interpretability of the fully connected layers of the network, the problem is also very difficult. This paper firstly analyzes its reason. Then a method of constructing logical network based on the fully connected layers and extracting logical relation between input and output of the layers is proposed. The game process between perceptual learning and logical abstract cognitive learning is implemented to improve the interpretable performance of deep learning process and deep learning model. The benefits of our approach are illustrated on benchmark data sets and in real-world experiments.
How to improve the interpretability of kernel learning
Nov 21, 2018In recent years, machine learning researchers have focused on methods to construct flexible and interpretable prediction models. However, the interpretability evaluation, the relationship between the generalization performance and the interpretability of the model and the method for improving the interpretability are very important factors to consider. In this paper, the quantitative index of the interpretability is proposed and its rationality is given, and the relationship between the interpretability and the generalization performance is analyzed. For traditional supervised kernel machine learning problem, a universal learning framework is put forward to solve the equilibrium problem between the two performances. The uniqueness of solution of the problem is proved and condition of unique solution is obtained. Probability upper bound of the sum of the two performances is analyzed.
How far from automatically interpreting deep learning
Nov 19, 2018In recent years, deep learning researchers have focused on how to find the interpretability behind deep learning models. However, today cognitive competence of human has not completely covered the deep learning model. In other words, there is a gap between the deep learning model and the cognitive mode. How to evaluate and shrink the cognitive gap is a very important issue. In this paper, the interpretability evaluation, the relationship between the generalization performance and the interpretability of the model and the method for improving the interpretability are concerned. A universal learning framework is put forward to solve the equilibrium problem between the two performances. The uniqueness of solution of the problem is proved and condition of unique solution is obtained. Probability upper bound of the sum of the two performances is analyzed.